微软亚洲研究院秦涛:对偶学习的对称之美 | 硬创公开课总结
按:众所周知,大规模带标签的数据对于深度学习尤为重要。在以图像识别、机器翻译等为代表的任务中,深度神经网络通过大量带标签的数据进行训练。但这样的前提存在两个主要的局限性。首先是人工标记数据的成本很高;其次是大规模标记数据获取的难度较大。
为了解决这一问题,在 NIPS 2016 上,微软亚洲研究院提出了“一种新的机器学习范式”——对偶学习,利用任务互为对偶的特点从无标注的数据中进行学习。它的训练原理是怎样,具体有哪些应用前景,近期又有着怎样的进展?本期硬创公开课,荣幸地邀请到微软亚洲研究院主管研究员秦涛博士,为我们讲述对偶学习的新进展。做了不改动原意的整理与编辑,并邀请了秦涛博士核对确认,在此表示感谢。
嘉宾介绍
秦涛博士,微软亚洲研究院主管研究员,在国际会议和期刊上发表学术论文100余篇,曾/现任机器学习及人工智能方向多个国际大会领域主席或程序委员会成员,曾任多个国际学术研讨会联合主席。秦涛博士是中国科学技术大学兼职博士生导师,IEEE、ACM会员。他的团队的研究重点是深度学习和强化学习的算法设计、理论分析及在实际问题中的应用。

大家晚上好,很高兴能有这样一个机会和大家分享微软最近的一些研究成果。首先非常感谢提供硬创公开课的平台,同时也感谢各位朋友这么晚还来参加这个线上活动。我今天报告的题目是对偶学习,主要想阐述的是人工智能的对称之美。

先做一个简单的自我介绍,我叫秦涛,是微软亚洲研究院机器学习组的主管研究员。首先我将介绍下我们组所做的事情。
DRL团队介绍我们组主攻方向是机器学习,有好几个小团队,涵盖了多个机器学习的方向。我们有一个团队侧重于分布式机器学习平台、架构及算法实现,我们做了很多开源的项目,包括微软认知工具包(原名: CNTK) 及分布式计算平台 DMTK 等,这些项目都可以在 GitHub 上找到。
我们除了做平台外,另一个研究方向是机器学习算法,包括两个团队:
深度学习与强化学习算法团队;
符号学习团队,即希望把一些逻辑、推理包括知识图谱的内容与深度学习、统计学习结合起来。
我们还有一个团队侧重于机器学习理论。我们始终认为,机器学习作为一个研究方向,不仅是算法和应用,也需要对学习的理论进行理解与认识。
具体到我带的深度学习与强化学习团队,主要课题如同 PPT 上所示的,有四个大方向。

对偶学习是非常重要的一个方向,也是我待会会重点介绍的内容。
第二个很重要的方向是轻量级快速算法。目前深度学习或强化学习的训练需要非常多的数据,非常长的训练时间及大量计算资源如GPU。我们设计了一些快速算法,能达到同样的精度或是相近的精度。
第三个方向是自主学习。我们意识到深度学习本身效果可以做得很好,但需要研究者或实践者具备一定的经验,知道如何调各种超参数,比如网络结构如何设计,每层多少节点,是否要用 residual connection/skip connection,卷积或 recurrent connection,包括优化过程中需不需要做各种各样的 SGD 算法,learning rate 怎么做 decay。这些对结果都会有很大影响。
当我们面临一个新的数据集时,可能我们需要花很多时间和代价才能得到一个好的模型。因为需要做很多超参数的 tuning.
我们自主学习的理念有点像在模仿自动驾驶,也就是说,能否通过学习的方式,来解决超参数的tuning问题?
此外,我们团队还会做深度学习与强化学习的相关应用,主要涵盖三个方面,包括:
语言理解(语言模型、文本分类、机器翻译、文本生成等)、图像理解(图像分类、生成、描述等)
游戏(麻将、桥牌等)
金融科技
接下来我将进入今天的分享主题:对偶学习。
对偶学习在介绍对偶学习之前,我想先介绍一下 AI 的发展。大家从很多媒体报道可以了解到,AI从 1956 年诞生以来至今已经 61 年,期间历经风雨包括两次高峰与两次低谷,到目前为止我们处于第三次的上升期,并且这一次的高峰可能还未到达。

AI 在很多实际应用中取得了很好的成绩,特别是在很多具体的任务上打败了人类水平。

因此我们可以说,现在正是 AI 的黄金时代。不仅仅因为它得到了政府的提倡和扶植,在学术圈是一个比较火的研究方向,更重要的是它在工业界的实际问题中取得了非常令人瞩目的成绩,比如:
微软亚洲研究院在 2015 年 ImageNet 上提出的深度残差网络,第一次使得图像识别水平超过人类的平均水平,top 5 的错误率达到了 3.5%,而人类的水平差不多是 5.1%。
而在语音识别领域,在去年 10 月,微软的语音识别系统在日常对话数据上,达到了 5.9% 的水平,首次取得与人类相当的识别精度。
游戏领域上,DeepMind 的 AlphaGo 打败了李世石,包括今年化名为「Master」也打败了很多围棋高手。今年 5 月下旬,AlphaGo 也会与中国顶级棋手进行对战(届时也将赴现场报道)。
虽然 AI (特别是以深度学习为代表)取得了非常大的成功,但它也面临着很多挑战。对于研究者而言,不仅要看它取得了哪些成绩,还要看它存在哪些问题,有哪些方向需要我们进行研究和推进。我们总结了当前 AI 或深度学习所面临的一些主要的挑战,也是我们组目前研究的方向。
AI 目前所面临的挑战 大数据,代价高昂
大数据,代价高昂目前的 AI 非常依赖大数据,特别是大量的人工标注的数据,但这些数据代价高,且在某些领域内数据很难获得。
大模型,使用不便深度学习的模型一般体量很大,可能达到上千万、上亿、上十亿参数的规模,一个模型大概是几百兆。如果在云端或是自己的 PC 上使用,问题不大,但如果想在移动设备(手机、物联网设备)上使用,就面临各种问题。比如手机输入法,如果用深度神经网络,表现会更好,但很多时候,光一个语言模型就要达到上百兆,对用户而言一个手机输入法需要加载上百兆的模型是一件挺难接受的事,会导致响应速度、memory、耗电量等多个问题。
大计算,时不我待训练一个深度模型很花时间。以 AlphaGo 为例,论文里讲到需要一个月左右的训练时间。如果有很多参数、超参数需要调节,算法的迭代速度会变得很慢。时间很多时候是比钱更宝贵的,虽然我们可以同时用很多 GPU训练,但还是需要好几周的训练时间才能得到一个模型。如此长的训练时间不管是对于大公司的产品迭代,还是创业公司的快速发展,都是一个很大的制约因素。
蛮力解法,似是而非现在的深度学习更像是一种「蛮力求解」,主要靠的是数量取胜,也就是说,由非常多的数据、参数、计算量堆砌起来。人做计算的功耗相对而言非常低,而人的学习过程也不需要那么大的数据量。举个例子,比如说开车,现在驾校标准的上课时间也就几十个小时,但特斯拉的无人驾驶汽车在路上跑了几百万小时,依然不能达到和人类一样的水平。因此,深度学习是否能结合人的一些知识提升学习速度,也是一个值得研究的问题。
调参黑科技,难言之隐深度学习有点类似于「黑科技」,参数调节是非常微妙的,比如一个参数的初始化非常依赖经验或感觉,这使得目前的深度学习不太像严格意义上的科学,更像是一种艺术。那么我们能否寻找到一种自动化调参的方法,让人工的干预越少越好。这样一来,我们也更方便将深度学习技术应用到新的场景中。
黑盒系统,不明就里随着模型深度和参数的增加,深度学习系统也会出现一些问题。此前某个互联网公司推出了图像分类的服务,但当时误将黑人判断为猩猩,引起了种族歧视的社会舆论,虽然这并不是企业的初衷,只是技术上出现了问题。这件事情实际上是因为深度学习系统是一个黑盒系统,技术人员难以预计一个黑盒子系统在使用中会出什么问题,以及解释为什么会出某个问题,也就很难在问题出现之前进行防范。因此,如果我们能让深度学习系统从黑盒子变成白盒子,具备可解释性及可修正性,自然让人工智能和深度学习有更大的应用空间。
一阶智能,非我所思现在的深度学习更像是一种「一阶智能」,即考虑静态任务(图像分类、语音识别)。但人类在社会中所面临的问题,比如自动驾驶、金融等领域,涉及的情况更加复杂。在面临决策时,人们不仅会考虑自己如何做选择,也常常会考虑其它人如何选择。
比如,当前的路堵车了,我是否要选择另一条路,但与此同时,可能别人也会选择同样的做法,那么是否会导致另外一条路更堵?
比如炒股,如果你要比别人获得更好的收益,那么不仅要考虑自己如何买入卖出,还要考虑其它人看好什么股票,他们买入卖出的时间节点是什么。
这实际上是人类在做决策时的一个博弈过程。目前深度学习的成功,包括图像识别、语音识别,还是处于一阶智能。那么可能我们需要考虑的是,如果同时有多个 AI 在一个系统中相互作用,会有什么二阶效应,该如何解决这个问题。
对偶学习的提出对偶学习的提出,主要是为了应对第一个挑战,即大数据的问题。

举些例子:
ImageNet 中标注过的训练样本量,大概是 120 万张图片;
语音识别领域需要成千上万小时的语料数据;
机器翻译里面需要上千万双语句对来训练;
围棋,如 AlphaGo,需要上千万的职业棋手的比赛落子记录。
而目前,大量的人工标注数据存在几个问题:
首先是标注代价高;
其次是某些应用领域很难拿到数据,如癌症数据(需要与医院合作),而因为涉及个人隐私,病人可能不愿意共享数据。
我们可以估计一下机器翻译标注数据的代价。目前市场上请专家翻译,是按照每个词进行计费, 5-10 美分/词,那么我们按市场平均价 0.075 美元,一个句子平均 30 个词来算,如果我们需要翻译 1000 万句话,那么花费会达到 2250 万美金。
不过有人认为,其实这个成本也还能接受。但像微软这样的公司,通常提供的是几十种甚至上百种语言的互译。如果仅仅考虑 100 种语言的互译,数据标注可能就已经需要超过 1000 亿美元了。
因为标注数据的代价如此大,研究人员也提出了不同的解决方案来降低对标注数据的依赖。目前互联网非常发达,没有标注的数据量非常大,如何利用这些无标注的数据辅助机器学习呢?这些方法包括:
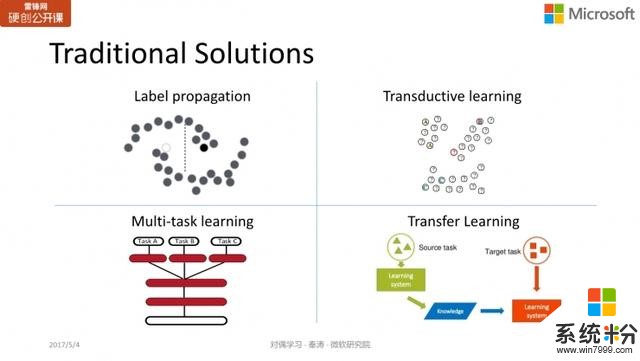
Label Propagation(标签传播):以图像分类为例,如果只有一万张标注数据,但我想获得 100 万张标注数据,怎么办?我可以从网上抓取到很多图像,如果一个未标注的图像A和标注的图像B很相似,那么就认为图像A具有和B相同的类别标签。这样就可以给很多未标注的数据加上标签,增加训练的数据量。
Transductive learning (转导学习):一种半监督学习的方法。
Multi-task Learning (多任务学习):每个任务都有自己的标注数据,那么多个任务在训练时可以共享这些数据,从而每个任务训练自己的模型时都能看到更多的数据。
Transfer Learning (迁移学习):这也是最近比较火的一种训练方法。比如我有一个标注数据较少的目标任务(target task),但我的另一个 source task 的标注数据量比较充足,那么我们可以通过模型的迁移或将数据通过变换借鉴过来,以辅助 target task 的学习。
对偶学习:一种新的视角我们采用一种新的视角来应对标注数据不足的问题,我们称其为人工智能的对称之美。其实大自然钟爱对称之美,例如生物构造(蝴蝶、人脸),人类也偏爱对称之美,比如泰姬陵、中国的故宫、太极。

对称结构不仅存在于自然界,在 AI 的任务中也广泛存在。比如:
机器翻译,有英翻中和中翻英的对称;
语音处理,需要语音转文字(语音识别),也有文本转语音(语音合成)的任务;
图像理解,图像描述(image captioning)与图像生成 (image generation)也是一个对称的过程。
对话任务:问题回答(Question answering)与问题生成(Question generation)
搜索引擎:文本匹配查询(Query-document matching)与广告关键词推荐服务(Query/keyword suggestion)

对偶学习的基本思想,实际上是一个新的学习范式,利用 AI 任务的对称属性(primal-dual)使其获得更有效的反馈/正则化,从而引导、加强学习过程(特别是在数据量少的情况下)。
 如何从零或非常少的训练数据中进行对偶学习?
如何从零或非常少的训练数据中进行对偶学习?
这是我们发表在 NIPS 2016 的一个工作,主要是以机器翻译为目标。
以机器翻译为例,我们手头有两个智能体,一个只懂英文不懂中文,另一个反之。我们希望同时训练英翻中和中翻英的模型。
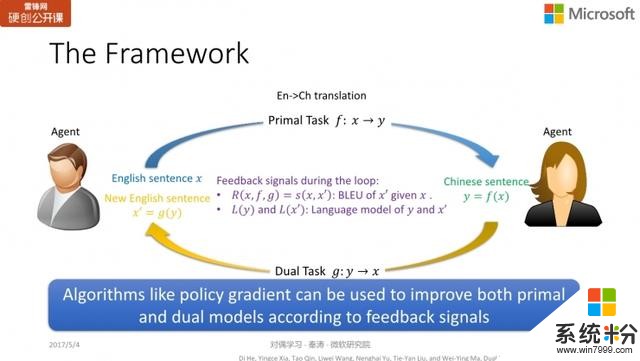
首先,拿到一个无标注的英文句子,我们并不知道
的正确中文翻译。我们通过 primal model
;翻译成一个中文句子
。
因为我们没有进行标注,因此无从判断句子
的正误。但懂中文的智能体可以判断作为一个中文句子,
是否为一个通顺的、语法正确的句子。因此,懂中文的智能体可以给出一个 partial feedback,反馈句子
的质量如何。
随后,我们通过对偶模型
,将中文句子
再翻译为英文句子
。懂英文的智能体收到这个句子后,它可以比较
与
的相似度。如果
和
的表现很好,那么
与
应该非常相近。如果反之,可能模型就需要改进。
这个过程实际上非常像强化学习的过程。在训练过程中,没有人告诉机器某个状态下正确的 action 是什么,只能通过「试错-反馈」的过程来反复尝试。
以围棋为例子,可能需要走上百步才能知道输赢,但通过最终的反馈,就能训练提高这个模型的优劣。对于我们机器翻译在
的状态下,我们无从知道正确的 action
是什么,因此只能通过已有的 policy
来 take action 得到
,再用另一个 policy
得到
, 从而通过比较
和
获得反馈。这实际上也是一个不断试错的过程,而且像强化学习一样,是具有延迟的反馈,最开始采取第一个 action
时,只能获得部分反馈,只有到流程结束,才能获得更有效的完整反馈,比如说
和
的相似性。
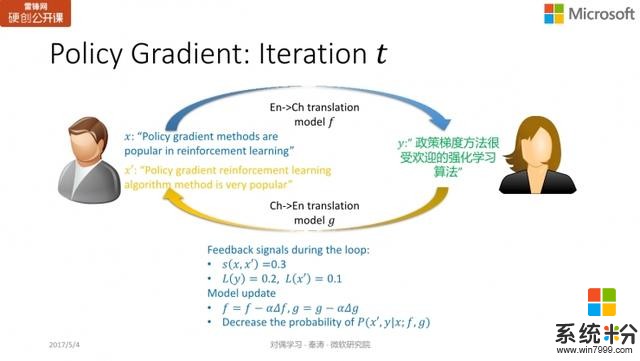
Policy Gradient因此,像强化学习的一些算法,都可以直接用于训练更新模型
和
。我们的工作中用了一个叫策略梯度 policy gradient 的方法。它实际上是强化学习的一类方法。

简单说来,它的基本思想是,当采取某个行动(action)获得了一个反馈/reward 后,如果反馈不错,那么我们会调整模型,使下一次采取同样行动的概率变大,如果反馈不好,那么我们就需要更新模型,降低我们采取同样行动的概率。在算法上的实际,我们会对 primal model 和 dual model 求梯度,如果反馈好,我们会把梯度加到模型上,增加这个 action 的概率;反之,我们会将梯度减去,减少这个 action 出现的概率。
举个简单例子,
为「Policy gradient methods are popular in reinforcement learning」,而得到的
在语法上一看就有问题,从而我们发现
和
并不理想,因此希望更新
和
的参数,通过减去梯度,使不好 action 出现的概率变小。
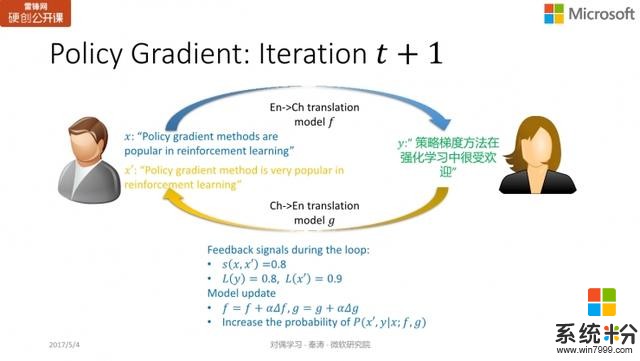
而在新的一轮迭代中,我们发现
和
都不错,那么通过加上梯度,使得让好的 action 出现的概率变大。
双语翻译
在英法翻译的实验上,双语标注的数据大概有 1200 万个句对,目前机器翻译最好的算法是基于深度神经网络(Neural Machine Translation),如果用 100% 的双语句对做训练,NMT 能达到 30 分的 BLEU score(满分为 100 分),如果只用 10% 的标注数据训练的话,NMT 的表现能达到 25 分;而在同样 10% 的数据下,采用对偶学习的思想进行训练,得分能达到 30 以上。也就是说,我们只用 10% 的双语数据就达到了 NMT 采用 100% 数据的准确度。

前面我们估计过,1000 万双语标记的数据耗费大概为 2200 万美元,而如果只需要 10% 就能达到同样的效果,我们只需要花 200 万美元。有点夸张地说,我们可以节省 2000 万美元的标注费用,非常可观。这个实验结果表明,对偶学习利用无标注数据的效率还是非常高的。
语音处理、图像处理及问题生成
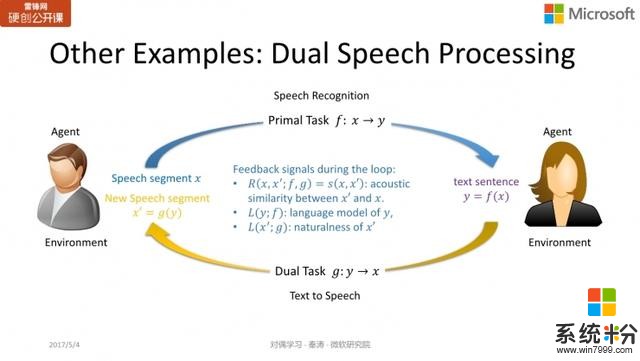
同样的思想也可以应用于语音处理中,primal task 指的是语音识别,而 dual task 则是语音合成,
是一个文本(句子),那么我们就能判断
的语法是否正确,语言的模型得分如何,进而判断
和
的相似度。
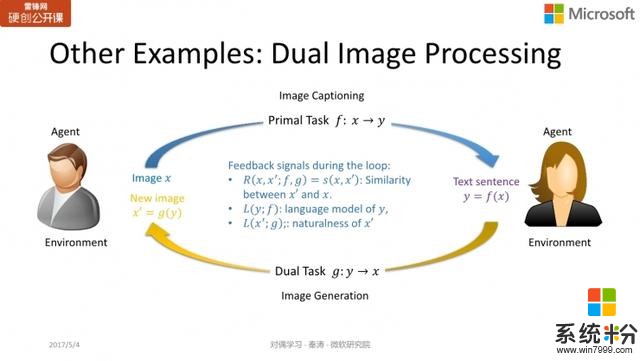
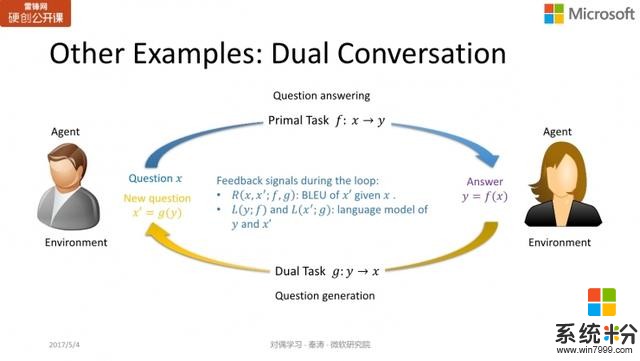
图像和文本之间的相互转换,问题回答与问题生成,也可以用同样的方式实现。我们有同事已经在这个领域做过一些尝试,也得到了很不错的结果。
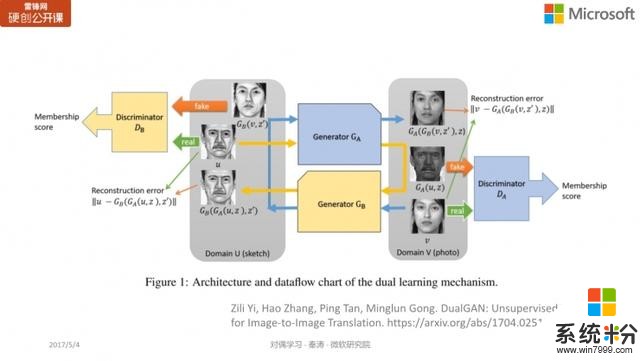
image-to-image translation
这个工作我们发表在 NIPS 2016 上,有很多研究人员把对偶学习的思想推广应用到其它领域。比如这个叫「image-to-image translation」的任务,将两种不同的图像相互转换,比如将素描转换为一个照片(生成器 A),或是反过来,将照片转换为素描(生成器 B)。通过生成器 A 和生成器 B 的两次生成,我们希望原始素描与最后生成的素描越相似越好。或是反过来,通过生成器 B 和生成器 A 的先后两次生成,我们希望原始照片与最后生成的照片的重构误差越小越好。对偶学习和 GAN相结合,可以得到很好的结果。
下图所示的是 Architecture label 的 photo translation 训练结果,第一列指的是原始 input 的 sketch(素描),第二列就是真实图片的样子,第三列就是 DualGAN 得到的结果,而第四列则是只用 GAN 训练得到的结果,第五列则是 cGAN,是训练标注数据所得到的结果。

第二行中,我们可以看到,中间 DualGAN 的结果比 GAN 及 cGAN 的结果都要好,比如第二行 GAN 的上半部分细节丢失得比较严重;而第三行中 DualGAN 生成的门相对比较清楚,而 GAN 和 cGAN 生成的门相对比较模糊。从实验结果的比对中我们可以看到,DualGAN 的效果相对要好不少。
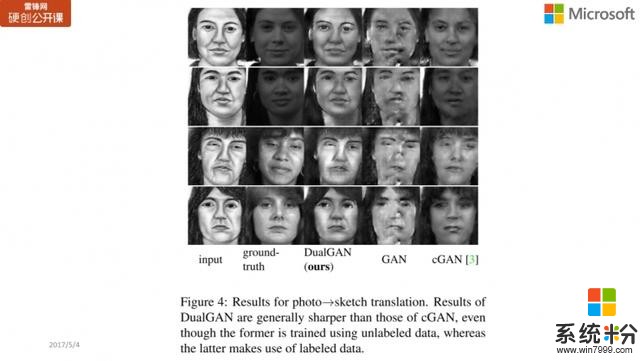
此外还有一个是从照片到素描(photo to sketch)的比对结果,同样地,第一列指的是原始 input 的 sketch(素描),第二列是真实图像,后面三列分别是 DualGAN、GAN 和 cGAN 的训练结果。DualGAN 在细节上更加清楚,我们可以看到 GAN 甚至某些地方都变形了,而 cGAN 也有不少细节(特别是眼睛)不够清楚。
Face Attribute Manipulation
此外,我们还注意到另一个工作,它也是借鉴了对偶学习的思想,叫「Face Attribute Manipulation」,即图像处理方面的一些工作。比如说,有个人戴着墨镜,那么我们会希望「脑补」出对方摘下墨镜的样子。或是反过来,在淘宝上看到一个墨镜,想知道自己戴上墨镜会是什么样子。把墨镜从人脸上去掉或戴上,实际上也是一个互为对偶的任务。

第一行是原始图片的样子,第二行则是结合 dual supervised learning 的方法来处理的结果;第三行则是不用对偶思想进行处理的结果。我们可以看出,第二行的结果比第三行的要好不少。从第一列及第五列可以看出,没有用对偶学习的话,不仅生成的图片比较模糊,脸也变形了。
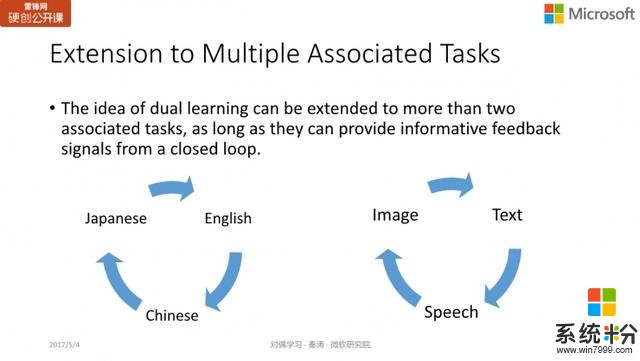
从无标注数据进行对偶学习的基本思想是要能获得反馈、形成闭环(Closed loop 的反馈)。这种思想不仅仅是局限在互为对偶的两个任务,可以扩展到更多的任务上,比如翻译,我们可以在英文、中文、日文间进行转换,形成闭环,从无标注的数据进行学习;又比如语音、图像和文本三者的转换也可以形成闭环,进行对偶学习。
目前为止,我们介绍了如何利用结构对称之美从无标注的数据进行对偶学习。需要指出的是,对称之美的价值不局限于此。我们来看看下面这个概率公式,我们可以想象其中
是中文,
是英文,或
是图片,
是句子,联合概率
可用不同的分解方式来实现,比如用 primal 的分解方式,即
,同样地,对偶分解方式可以写成
。

利用这样一个互为对称的 AI 任务的概率关系,我们可以:
把它做为结构化的正则项,以加强监督学习。
或者提高我们的推理预测(improve inference)能力。
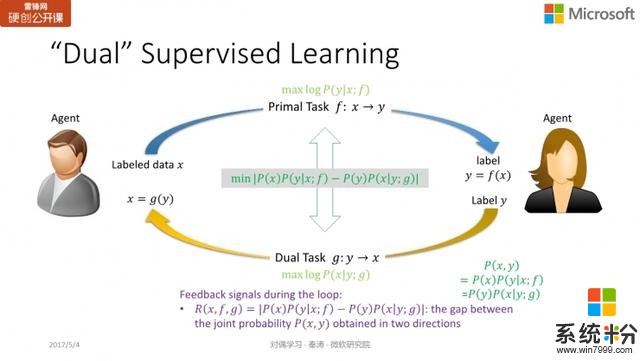
对偶学习如何增强监督学习?下面我们首先来看看对称之美如何加强监督学习。

机器翻译
我们还是以翻译为例,如果是有标注的数据,那么监督学习的训练过程相对简单。我们知道
是
正确的翻译,因此,我们就希望更新模型
,使
出现的概率越大越好,也就是最大似然准则。
同样地,对偶训练的过程也是迭代更新对偶模型
使
,使条件概率
最大化。在传统的监督学习中,两个任务的训练过程其实是分开的。我们知道,联合概率
不论是用原模型
计算还是用对偶模型
计算,得到的值应该是一样的。但是如果是分开训练
和
的话,不一定能保证联合概率相同。
为了解决这一问题,我们加入了「正则化」项,也就是
,将两个概率值的 gap 最小化。从而,我们实现了通过结构的对称性加强监督学习的过程,将两个互为对称的两个任务一起进行学习,我们把这个考虑的结构对称性的监督学习叫做对偶监督学习。对偶监督学习实际上要优化三个损失函数:最大化对数似然
,最大化对数似然
,以及
。第三项就是正则化像,即要求联合概率越接近越好。这与 SVM 的正则化像的区别在于,后者与模型有关,和数据无关,但对偶监督学习中讨论的正则化像还与数据相关。
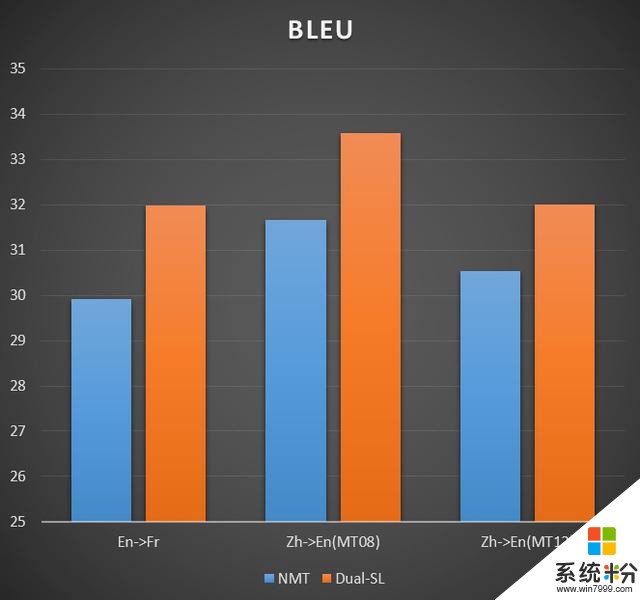
基于对偶监督学习的方法,我们做了机器翻译的任务,包括英法、英中等翻译,我们的方法(Dual-SL)相比标准的神经机器翻译(NMT)效果还是要好不少,用BLEU来评价得分提高了 1-2 分。
图像分类与生成
我们还将同样的思想应用到图像分类与图像生成上。这两个过程同样互为对称,但与机器翻译的主要不同点在于,这个过程存在着信息损失。比如将一张图分成一个类别,但一个类别如「猫」是一个很抽象的概念,可能对应很多不同猫的图片,也就是说从
至
有信息损失。有人担心是否因为信息损失的问题,对偶学习就不管用了,实际上不然。
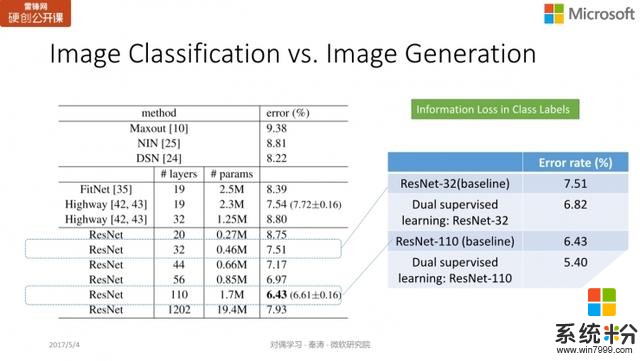
我们在 CIFAR 上采用了 32 层的深度残差网络 ResNet 和 110 层的深度残差网络进行测试。单独训练图像分类时,32层的错误率是 7.51;110 层的则是 6.43;而如果结合了对偶监督学习,错误率可以分别减少到 6.82 及 5.40。这个提高实际上非常显著,从 32 层到 110 层的效果提升也就是 1 个点左右,我们在 110 层的基础上加上对偶学习后,我们可以进一步将错误率降低一个点。目前这项工作已经被 ICML 2017 接受。
对偶学习如何增强推断?
就像我们前面讲的,不论是有标注的数据,还是无标注的数据,都是通过一种结构的对偶属性提高我们训练的过程,改进我们的模型,使我们的训练做得更好。除此之外,其实利用结构的对称之美还能提升我们推断及预测的过程。
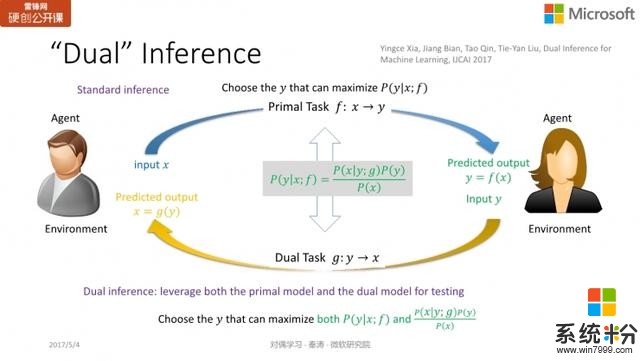
同样以机器翻译为例,如果我有了一个模型
(英翻中的模型)和模型
(中翻英的模型)。如果有一个英文的句子
,我们通过解码把能最大化
的中文句子
作为
的翻译;同理,给定一个中文的句子
,我们把能最大化条件概率
的英文句子
作为
的翻译。这就是机器学习中标准预测推断的做法。
前面我们讲到,联合概率
有两种计算方式,那么
条件概率模型可以用正向模型
来计算,也可以通过反向模型
来计算,即
。
因此我们提出了一个新的概念,叫对偶推断或对偶预测「dual inference」,在预测/推断过程中同时采用
和
两个模型。原本机器学习标准的预测过程是:我要从
预测出
,直接用
就可以了,但现在不同,我预测
时,我希望生成
能使两项最大化:
和
。
需要指出的是,对偶推断/预测不影响 和 的训练过程,这两个模型还可以按照原来的训练过程进行,我们只是改进了预测的过程。
我们在机器翻译、文本情感分类、图像分类上做了实验,结果如下面三张图所示,相对于传统的机器学习中的推断/预测方式,对偶推断对这些任务的准确度都有明显的提升(错误率明显降低)。
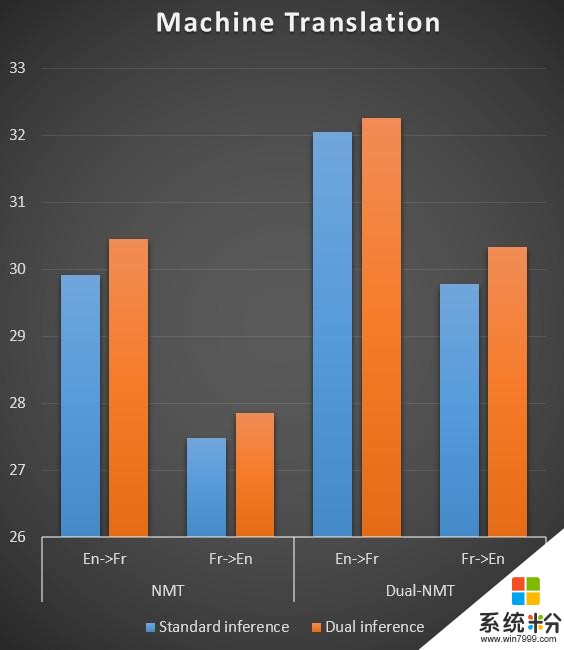
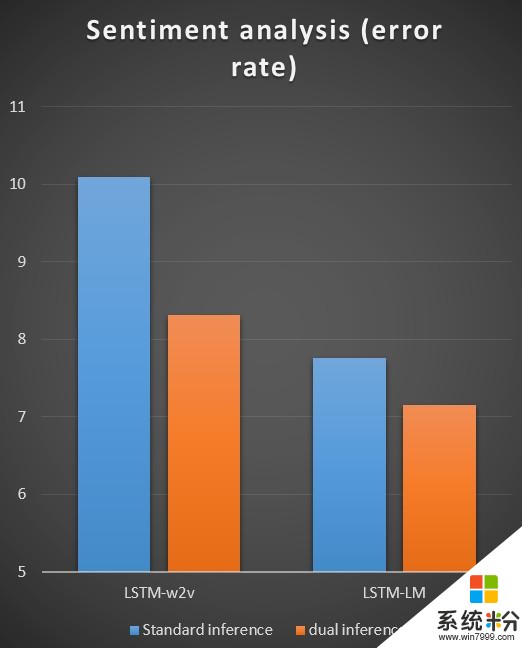
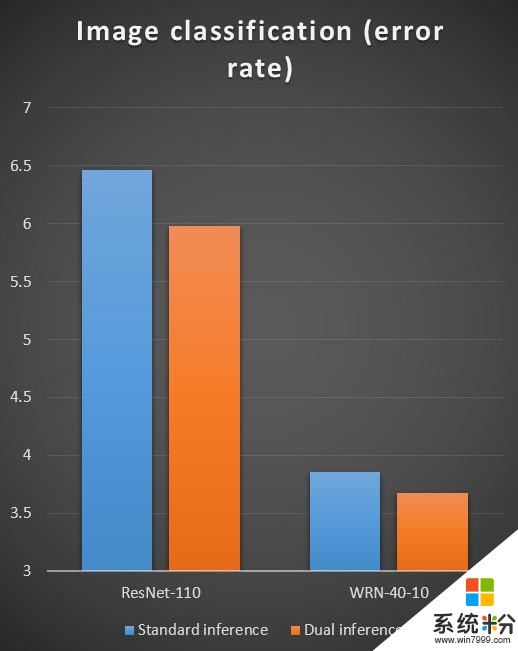
对偶推断/预测这个工作也刚刚发表在国际人工智能大会上(IJCAI 2017)上,感兴趣的读者可以阅读我们的论文。
相关工作
对偶学习的思想与很多工作都有关系。
Auto Encoder对深度学习比较了解的同学可能知道一个概念叫「auto encoder」(自编码器),主要是为了学习数据的隐藏表达(hidden representation)。比如输入一张图像,我们希望将它映射到一个特征空间,在无监督学习中,通过特征表达的解码过程将图像反向生成。
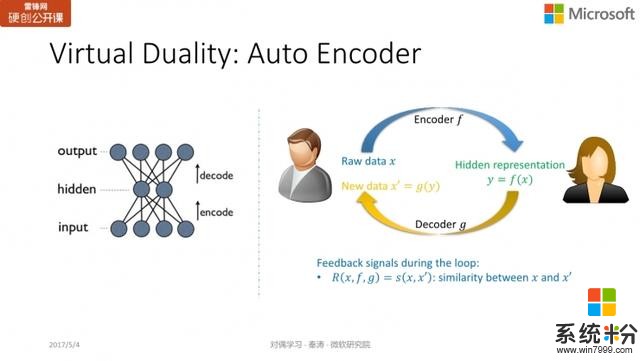
如果用对偶学习来表示这一过程,encoder 相当于原模型;而 decoder 就相当于对偶模型;目的是希望生成的新数据
与原始数据
越接近越好。
从这个角度来看,auto encoder 的思想与无监督对偶学习的概念很类似。
GANs另一个很火的网络是 GANs,基本思想是输入一个噪声向量,我们希望生成器所生成的图片与真实图像越接近越好,使判别器无法区分。这种关系就像造假者与警察的关系:造假者希望能制造出尽可能以假乱真的东西,而警察希望尽可能将赝品和正品区分开来。
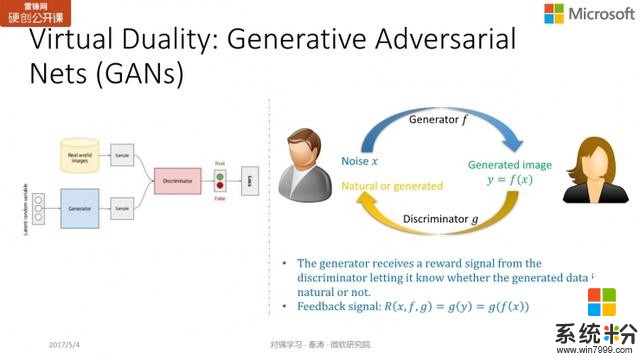
GANs 目前也是深度学习非常火的研究方向。如果用对偶学习的图例来看,生成器就像是原模型,把随机噪声向量
映射到一个图片
;而判别器就相当于对偶模型,通过直接给
打分的方式,给予它的真实程度反馈。
对偶学习:一种新的学习范式
对偶学习可以应用于很多方面,如无监督学习与半监督学习,但它的思想与传统思路有些不同。
与无监督/半监督学习对比:
首先在无监督学习里,无标注数据并没有反馈;半监督学习里会生成一些伪标签,但质量不能控制。这与对偶学习非常不同,我们会对无标注数据生成一个伪标签,进而通过对偶模型对这些伪标签给出质量反馈,因此我们能更有效地利用无标注数据,使得结果比以往的半监督/无监督学习要好。
与 co-training 对比:
其次,有人会认为这种方法与 co-training 很相似,但实际上 co-training 只是半监督学习的一种特殊方法,做了一些很强的假设,如数据的特征集由两个不相交的子集且每个子集的特征也足够强,且co-training只是针对一个任务进行学习。而对偶学习至少需要两个互为对称的任务,且对数据的特征没有假设。
与多任务学习对比:
对偶学习与多任务学习也有些不同。如多任务学习在邮件识别
中,垃圾邮件识别(
到
)与紧急邮件筛选(
到
),共享底层的表达
,但上层的
与
是不同的。而对偶学习并不共享底层表达。
与迁移学习对比:
此外,对偶学习与迁移学习也有不一样的地方。迁移学习有一个主要任务,采用其它的任务辅助它。对偶学习的两个任务是共同提高的,不分主次。
因此,我们认为对偶学习是一种新的学习范式。
总结

对偶学习非常通用
能够覆盖目前 AI 的许多应用,包括文本理解、图像理解,语音识别等。
也能涵盖于 auto-encoder,GANs 等工作。
对偶学习可以应用于不同学习环境
监督学习、半监督学习、无监督学习都不在话下。
不仅能提升训练效果,也能提升推断过程。
对偶学习在技术上的贡献
对偶学习利用了结构的对称性/相关性提升学习,利用人类的先验知识提升深度学习的系统;
对偶学习另一个很有意义的地方在于提供了一种从无标注数据学习的行之有效的方法。有很多人认为深度学习五到十年的主要突破方向在于如何从无标注数据进行学习,而对偶学习通过一个闭环的反馈系统,使我们能从无标注数据中进行学习。
另外,强化学习在游戏领域中表现更好,因为游戏可以通过规则制定明确的反馈机制,但像机器翻译、无人驾驶这样的物理世界的任务,实际上很难获得反馈。通过对偶学习,我们可以获得反馈信号,让强化学习在实际问题中进行应用。
对偶学习的工作有非常多的研究者共同参与,包括微软亚洲研究院的同事及实习生们。欢迎大家与我们交流讨论合作,一同推进对偶学习的研究。

最后打一个广告。人工智能深度学习目前是非常火的研究领域,也面临着非常多的挑战,我们希望能有更多的朋友能加入这个方向的研究,共同推进人工智能的发展,创造未来。感兴趣的朋友特别是即将毕业的同学或者已经从事这方面工作的同学可以把简历发到这个邮箱 ml-recruit@microsoft.com。
谢谢大家。
 Q&A
Q&A1. 之前在知乎上看过秦老师关于对偶学习的回答,里面提到在解决大数据问题时,微软会将对偶学习应用到更多的领域中去,比如图像分类和生成。但图像的分类和生成,与机器互译的流程并不完全相同(即并不完全对称),您是如何理解这个问题的?
的确,过程看起来是对称的,实际上两者的信息保留度上相差很多。我们可以近似的认为,机器翻译从中文到英文是没有信息损失的,反之亦然。但像图像分类与图像生成存在信息损失,因此我们近期的工作「对偶监督学习」就希望将它应用于图像分类与图像生成中,这个工作可以参考我们ICML2017的论文。目前我们也正在研究如何利用对偶学习的思想针对图像分类和生成进行无标注学习。现在有一些初步的想法,但还没有一个成熟的结果。我们当前的结果表明,如果没有信息损失,那么可以采用对偶无监督学习。而不论是否有信息损失,都可以采用对偶监督学习。
2. 对偶学习还有哪些可能的应用和方向?是否能谈谈研究院最近所做的一些进展?
我在前面的 PPT 也列举了一些应用,比如研究院的同事正在研究的方向,包括问题的生成与回答、语音合成与语音识别等。实际上,对偶学习的适用范围很广,研究和应用空间很大,感兴趣的朋友们可以和我们邮件联系。
3. 在人工智能的学习过程中,如何看待大数据及小数据各自所起的作用?
简单讲来,如果我们有大量标注数据的话,自然我们会想办法充分利用,但如果没有大数据的话,小样本学习的重要一点在于如何利用 domain knowledge 或先验知识进行学习。包括对偶学习在某种程度上,需要利用两个任务的对称性,实际上这也是人类的一种先验知识,以加强学习。
4. 如何评价最近挺火的DiscoGAN/DualGAN跟对偶机器翻译之间的异同?
DualGAN 和对偶学习的思想非常类似,但他们的成果算是一个加强版,学习过程的反馈包括两部分,一个是重构误差,另一部分是判别器判断真假的反馈。
5. DualGAN连一小部分有监督数据都不需要,对偶机器翻译有可能也做到吗?
我们做了一些简单尝试,初步发现,如果完全不用标注数据,对偶机器翻译收敛会变得很慢,在资源比较有限的情况下,很难在几个月里达到一个好的结果。
我们组现在也在研究一个课题,即完全没有标注数据,是否能只通过一本英汉词典(先验知识)结合对偶学习思想进行学习。
6. actor critic是否也算有duel learning思想?对偶学习收敛性如何优化?
actor critic 有点像对偶模型,actor 负责 take action,而 critic 负责给这个 action 的好坏进行反馈,这样两者可以一起优化。但是 actor critic 不是利用了结构对称性,而是为了优化 actor 而构建一个 critic,因此我觉得 GANs 与它更相似。
优化也是我们现在对偶学习遇到的主要问题之一,也是深度学习算法普遍会遇到的一个问题。这是一个很复杂的过程,目前我们有一些经验,但通用性不强,因此也处于一个摸索过程。如果朋友们有什么想法,也欢迎一同讨论。
今天的直播就到这里结束。如果大家想看课程总结文章,可以关注的公众号,里面有很多很好的内容,建议大家平时可以多关注。如果想看具体课程,可以回复「167」进入行业微信群讨论,也欢迎大家和我们交流,谢谢大家。









