学术盛宴:微软亚洲研究院CVPR 2017论文分享会全情回顾
机器之心原创
作者:Smith
今年 7 月,世界顶级计算机视觉会议 CVPR(计算机视觉与模式识别会议)将在美国夏威夷举行。在此之前,「微软亚洲研究院创研论坛——CVPR 2017 论文分享会」近日已在北京中关村微软大厦举办。与会嘉宾不仅包括来自北京大学、清华大学、上海交大等各高校的教授与在读博士生,也有来自微软亚洲研究院、中科院、英特尔中国研究院及商汤科技等的研究人员;会议期间,这些国内外计算机视觉领域学术界、工业界的优秀代表们携各自在 CVPR 2017 发表的最新研究结果和相关技术观点,在此次论坛上进行了分享与探讨。

本次活动的组织者之一, 微软亚洲研究院视觉计算组研究员王井东博士主持了开幕环节,微软亚洲研究院的副院长潘天佑博士和中科院自动化研究所的王亮博士先后为此次会议致开幕词。潘天佑博士表示此次活动有三个重要意义:
分享——来自不同高校、研究机构及企业的国内业界代表汇聚一堂,分享自己的成果;
推动——此次活动受到了各高校师生的强烈回响,20 余位老师及 200 余位与会学生积极参加,现场也提供了网络直播,这些都推动了计算机视觉的普及与传播;
思考——「学而不思则罔」,希望大家在总结过去成果的同时,也对计算机视觉未来的发展进行思考与展望
王亮博士表示,此次「CVPR 2017 论文分享会」将会提升国内视觉学者在国际上的影响力,并希望大家充分地交流沟通,擦出思想的火花。
而清华大学的温江涛教授则从硬件的角度阐述了我们现在所应用的计算机系统其实远远不够完善,并且还有很大的开发潜力。他的观点是:要从视频编码(video coding)和超大规模集成电路设计(VLSI Design)的角度进行进一步的研习,并且把相关理念应用到整个系统当中。他还把自己团队所研发的视频转码软件的最新成果展示给了大家。温教授表示这是第一个也是唯一一个应用基于实时 VR 系统的光流法的软件,其转码率可比其他方法高出 60%。

整个论坛共包括 6 个不同主题的 session 和一个圆桌讨论环节:
Session 1—Captioning and Computational Photography ;
Session 2—Learning (I)
Session 3—Detection and Parsing
Session 4—Learning (II)
Session 5—Face, Action, and Person Re-identification
Session 6—Hasing and Retrieval
Session 1:Captioning and Computational Photography
首先微软亚洲研究院的廖菁带来了题为 StyleBank:An Explicit Representation for Neural Image Style Transfer(StyleBank:神经图像风格迁移的外显表征)的相关内容。她的团队在这一设计中运用卷积神经网络作为基础,在通过卷积作用得到特征层后,加入风格化分支——StyleBank 层作相应处理,可以得到很好的图像效果。

而北京大学的刘家瑛教授演讲的题目为——Awesome Typography and Awful Rain Removal(文字风格化与去雨研究)。主要介绍了基于统计数据的文字效果迁移——即以斑块图形(patch pattern)和文本骨架距离(distances to the text skeleton)的高度相关性为出发点,对局部多尺度纹理(local multi-scale texture)、全局纹理分布(global texture distribution)和视觉逼真度(visual naturalness)进行目标函数构造。这一方法可以在贴合文字形状的基础上进行文字特效风格化,也生成了大量的艺术字体库。除此之外,刘家瑛教授还介绍了她的「去雨」研究(Deep Joint Rain Detection and Removal from a Single Image)——基于多任务学习的方法对图像中的「雨线」和「雨雾」进行检测和去除,从而使图像的主题内容呈现的更加清晰。这项研究有着重要的实际意义,可应用于恶劣天气情况下的道路监控以及自动驾驶等领域。

英特尔中国研究院的李建国展示了其 Weakly Supervised Dense Video Captioning(弱监督影像的字幕生成)的相关成果。(相关论文链接:https://arxiv.org/abs/1704.01502)
此项研究的目的是:在仅有影像级句子注释(video level sentence annotations)的情况下,对每个输入素材都生成多个不同且能提供有用信息的句子。此结构包括三个重要组成部分:1. 用词库进行区域等级(region-level)编码的 Lexical FCN;2. 句子到区域序列的关联(sentence to region-sequence association);3. 用序列到序列(sequence to sequence)的学习方法进行句子的生成。在这种方法中,Lexical FCN 用来进行弱区域建模(weakly region modeling);用 Lexical FCN 的输出使句子和区域序列(region-sequence)相结合;仅用影像级的句子注释来生成影像字幕;避免了 1:N(特征:句子)的匹配问题。
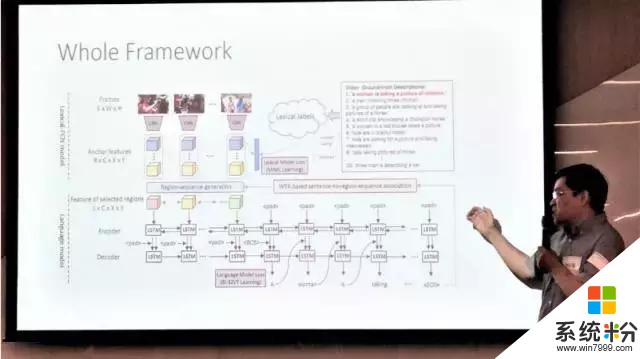
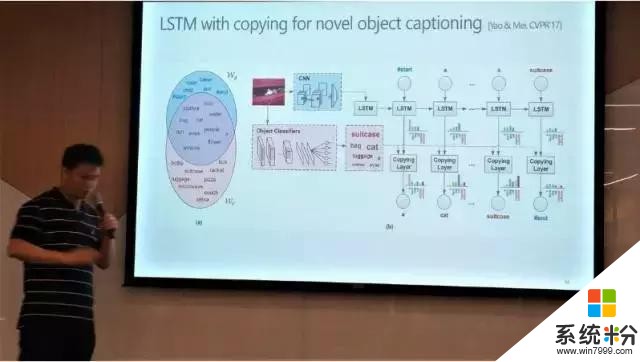
而微软亚洲研究院的姚霆带来的相关研究成果为 Image Captioning with Attributes,通过利用属性(attributes)对图像标注进行改进,这种方法有很大的潜力可以成为生成开放性词汇句子(open-vocabulary sentences)的有效方法。这种以搜索为基础的方法,应用卷积神经网络加循环神经网络,可以使图像标注系统更加实用。
Session 2:Learning (I)
来自成都电子科技大学的宋井宽则带来了理论性极强的内容——Matrix Tri-Factorization with Manifold Regularization for Zero-shot Learning。这种对矩阵进行因式分解的框架可以有效地在特征(features),属性(attributes)和类别(classes)之间架起关系桥梁;利用测试数据的流形结构(manifold structure)可以增加精度,并且克服投影领域的移位(shift)问题;这种方法在「常规」和「一般化」的 Zero-shot Learning 设定中都很稳定。

Session 3 :Detection and Parsing
来自微软亚洲研究院的辛博带来了 Collaborative Deep Reinforcement Learning for Joint Object Search(用协作式深度强化学习进行连结式物体的搜索)。他提出了一种新的多智能体间的 Q-学习的方法,即门控选通式连接(gated cross connections)的深度 Q 网络——给交流模块设计一个门控结构,可以让每个智能体去选择相信自己还是相信别人。这是一种对虚拟智能体进行联合训练的高效方法。它有效地利用了相关物体间的有用的上下文情境信息(contextual information),并且改进了目前最先进的主动定位模型(active localization models)。

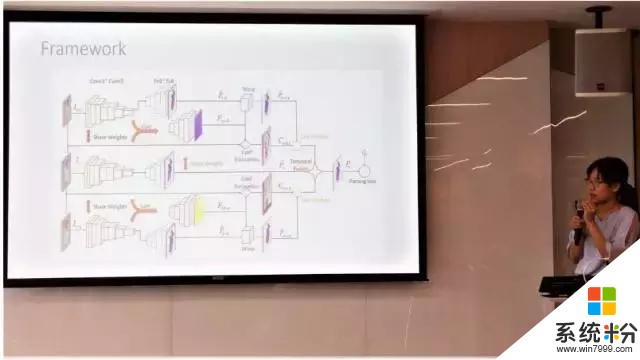
然后,华中科技大学的王兴刚教授带来了 Multiple Instance Detection Network with Online Instance Classifier Refinement(多实例检测网络与在线实例分类器改进)。而商汤科技的石建萍研究员则带来了 Pyramid Scene Parsing Network(金字塔型情景解析网络),这项研究成果也在去年的 ImageNet 比赛中摘得桂冠。

中科院信息工程所的刘偲研究员演讲的题目是 Surveillance Video Parsing with Single Frame Supervision(基于单帧监督的监控录像分析)。这种方法是第一个实现在每一段录像仅标注一帧的情况下对监控录像中的人进行分析的;而且由于提出的方法是端到端(end-to-end)的,因此非常适用于实际应用;此方法也有很好的延展性,可以对其它任务产生帮助,如行人再识别和人类特征预测等。(相关链接:http://liusi-group.com/projects/SVP)
Session 4: Learning (II)
来自北京大学的王亦洲则带来了题为 Agent in the Environment 的演讲。他表示现在的机器视觉研究已经在图像检测识别算法以及静态图像理解方面取得了不错的成果,而接下来则需要将更多的精力投入到环境(Envrionment)、智能体(agents)、主动感知和学习、自适应、多任务学习(multi-task)以及自进化(self-evolution)当中去。
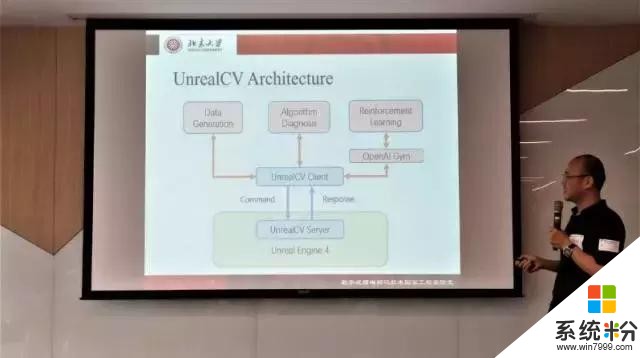
王亦洲教授所带领的团队研发出了一种先进的开发环境——UnrealCV Environment,这种开发环境有如下优点:
精准及实用的标注真值(ground-truther):生成可控数据(controllable data)用来进行训练,并且用于评估智能体、算法(摄像头、光源等);以任务驱动为基准。
这是一个连接智能体和环境的平台:提供试验和错误的交互性环境(interactive Environment)以供智能体从经验当中进行学习;智能体在保证成本最低(包括能源及损坏率)的情况下,可以很容易地从该平台中获得常识性信息(common sense knowledge)。
环境的丰富度决定了智能水平的复杂度。
王教授又解释了交互(interaction)是如何提高学习水平的:1. 可以避免一些静态的观点和图像环境;2. 可以学习一些隐藏的属性(比如惯性、硬度、新鲜度等);3. 获得学习能力更强的学习者。
UnrealCV Environment 的一些优点:1. 现实性;2. 易于使用;3. 模型库;4. 功能强大而且可以延伸;5. 相关文件齐全而且经过了检验。
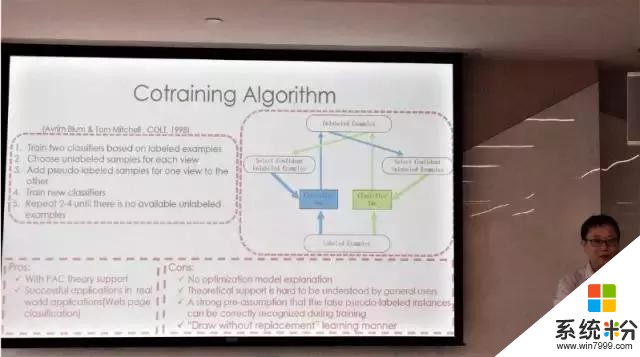
接下来,来自中山大学的袁淦钊教授介绍了 A Matrix Splitting Method for Composite Function Minimization(用于复合函数最小化的矩阵分解方法)的相关内容。而来自西安交大的孟德宇教授则介绍了一种新型的 Self-Paced Cotraining 模型和算法。这是一种「抽出后放回」(「draw with replacement」)的学习方法;它是用连续训练(serial training)的方式来进行的。其合理性可以在没有主观假设的情况下被理解。
中科院自动化所的程健团队则带来了 Fixed-Point Factorized Neural Network(定点分解神经网络)。一般的方法都是先做矩阵(张量)分解然后做定点运算(fixed point); 而这种方法是先进行不动点分解,然后进行伪全精度权重复原(pseudo full precision weight recovery),接下来做权重均衡(weight balancing),最后再进行微调(fine-tuning)。

Session 5:Face , Action , Person Re-identification
清华大学的鲁继文教授率先进行了题为 Consistent-Aware Deep Learning for Person Re-identification in a Camera Network(用一致性感知的深度学习方法在照相机网络中进行人体再识别)的演讲。这也是首次将端到端(end-to-end)的方法应用于照相机网络行人再识别领域当中。
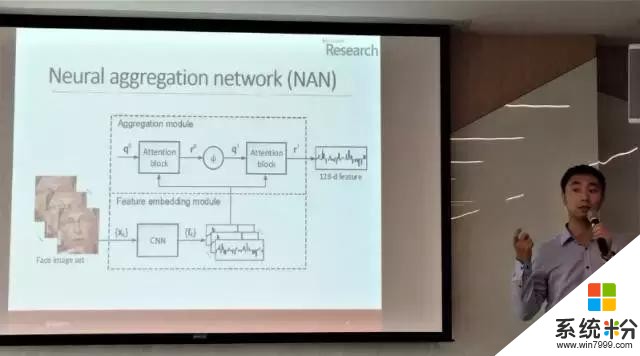
微软亚洲研究院的杨蛟龙的相关研究是 Neural Aggregation Network For Video Face Recognition(用于视频影像中人脸识别的神经聚合网络)。传统的深度学习方法在进行人脸识别时需要对每一帧都进行特征提取,这样的效率是很低的。而 NAN 网络可以对视频或目标对象进行高度紧凑(highly-compact)的表征(128-d);利用注意力机制(attention mechanism)进行学习型聚合(learning-based aggregation);这种网络在三个关于人脸视频的基准中都有着一流的表现。杨蛟龙研究员表示这种聚合网络是简单并且通用的,今后也会用于其它一些视频识别的任务当中。
来自上海交大的林巍峣教授演讲的题目是 Action Recognition with Coarse-to-Fine Deep Feature Integration and Asynchronous Fusion(用 Coarse-to-Fine 深度特征集成和非同步结合的方法进行动作识别)。这是通过把粒度不同的多动作类别(multi-action class granularities)的特征进行集成来实现的。

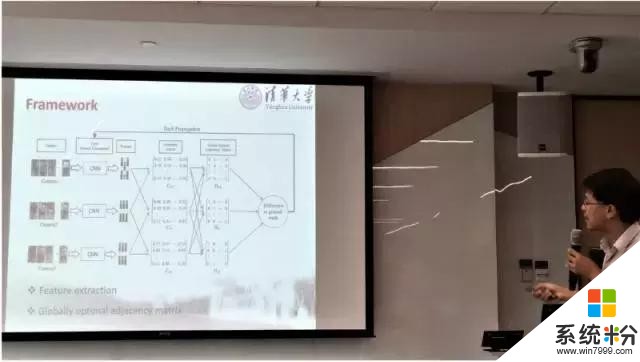
而清华大学的龙明盛的研究题目为 Spatiotemporal Pyramid Network for Video Action Recognition(用于影像动作识别的时空金字塔型网络)。如下图所示,该网络称之为金字塔型是因为其由下到上融合了三个处理阶段。最下面一层采用 CNN 在时间流 T 上获取全局的运动特征。而向上第二层的注意力模型采用下层提供的全局运动特征作为向导。而最上面的处理层则将视觉、注意力机制和运动特征结合起来计算损失函数。

Session 6:Hashing and Retrieval
西安交大的薛建儒教授的学生高占宁和北京航空航天大学的刘祥龙教授分别带来了 A Unified Framework for Event Retrieval, Recognition and Recounting 和 Deep Sketch Hashing:Fast Free-hand Sketch-Based Image Retrieval 的精彩内容。

而厦门大学的纪荣嵘团队和中科院计算所的王瑞平教授则分别带来了 Cross-Modality Binary Code Learning via Fusion Similarity Hashing 和 Learning Multifunctional Binary Codes for Both Category and Attribute Oriented Retrieval。

其中王瑞平教授表示:同时对图像表征(image representation)和哈希函数(hash function)进行学习能显著提高性能(CFW-60K);而对特征属性(attributes)和类别(classes)进行联合学习(joint learning)也是可行的。(相关代码和数据资料已经开源:http://vipl.ict.ac.cn/)。
在此次会议中期的圆桌讨论环节,
陈熙霖,中国科学院计算技术研究所研究员
王蕴红,北京航空航天大学计算机学院副院长
曾文军,微软亚洲研究院首席研究员
林宙辰,北京大学信息科学技术学院教授
齐国君,美国中佛罗里达大学计算机系助理教授
五位计算机视觉领域的资深专家分别对:
「深度学习热」对于计算机视觉领域的冲击;
arXiv 对于领域发展的影响;
华人在 CVPR 2017 中的卓越表现;
以及在视觉领域应该怎样设计一个真正可行的奖励函数,来解决物体的检测、分割、视频捕捉等工作
等问题进行了十分精彩的解答与讨论,详情见《观点 | 计算机视觉,路在何方》
附:CVPR 2017(国际计算机视觉与模式识别会议) 将于7月22号到7月25号在美国夏威夷举行。今年的 CVPR 共收到有效提交论文共计2680篇。总计783篇被正式录取(占总提交数的29%)。据统计,其中有华人参与的论文共占到总数的45%左右。详细论文列表见官方网址:http://cvpr2017.thecvf.com/program/main_conference
感谢微软亚洲研究院对本次报道的大力支持。









