微软亚洲研究院郑宇: 为什么柯洁又输了, 专业棋手反而觉得有希望了?

按:本文由郑宇博士受之邀,特约撰写。郑宇博士为微软亚洲研究院主管研究员,上海交通大学讲座教授。
5月25日,AlphaGo 2.0版本在人机围棋比赛第二局中盘战胜柯洁。相比第一场比赛的沉闷,此次对弈中,柯洁下得非常积极,多次下出好手和狠手,把局面搅得很乱,多块棋的命运都连在了一起,场面一度非常复杂,过程惊心动魄,跌宕起伏。
据AlphaGo工作人员介绍,此次比赛人机双方都展现了强大的水平。AlphaGo后台的计算量急剧增加,如果不能及时剪枝,可能很快就要算不过来了。无奈柯洁在关键时刻出现明显失误,痛失好局,这可能也是人类的弱点(疲劳和情绪的波动)。
与上一局观战专业棋手集体悲观相比,这次大家普遍认为局势一直在向着有利于柯洁的方向发展,非常有希望获胜。专业棋手的信心也在悄然复苏。
昨天第一局比赛后,中国计算机学会向我约稿。我发表了第一篇评论,在网上引起了不小的讨论,因此,本次评论也顺便解答网友们提出的疑问。
还是先上观点,再解析。先重申一下昨天的几个观点:
1. 在围棋这个项目上,AlphaGo的综合实力目前走在了人类的前面,但并没有完全攻克围棋这项运动。
一方面,能通过短短几个星期的学习就能击败学棋二十多年的顶尖围棋选手,已经证明了人工智能的强大。因此,即便AlphaGo日后万一输了,我们也仍然应该为人工智能点赞,切不可再次否定人工智能的力量。
另一方面,AlphaGo采用这样的技术线路其实是根据人类自身对围棋的理解来设计的,即搜索+价值评判。也就是说我们先假设各种走法(执行下去),再评判这样走可能赢的机会大小。由于索搜空间巨大,即便用尽地球上所有的资源,也不能找到最优解。此时,在某个局面下对(未来输赢)价值的判断就变得尤其重要。在深度学习没有出现之前,这点一直是机器的弱项,因此,早年间人在这方面占有巨大优势。
从专业的角度来讲,AlphaGo用深度学习去逼近了一个价值判断函数,然后再跟蒙特卡洛搜索树结合的方法。这个近似解比目前人类的价值判断(可能)接近或者要略强一些,加上机器不知疲倦的搜索效率和无情感波动,综合来看走在了人的前面。
但AlphaGo得到的这个解远不是最优解法,围棋未来可探索的空间还很大,还没有被攻克。打一个不恰当的比喻,好比我们现在发明了一种新的抗癌药品,比以前的药物能更好的延缓癌细胞的扩散,但还是不能完全杀死癌细胞,治愈人类。因此,我们不能说这个药品已经攻克了癌症。
其实,机器和人可以互相帮助提高水平。当人们对围棋有了更深入的了解之后,又会设计出更好的人工智能算法。两者其实并不矛盾,相辅相成,互相促进,不管谁输谁赢都是人类文明进步的体现。客观认识这一点很重要。
2. 人类也是在进步的,我们也不要低估了人类后天的快速(小样本)学习能力,这点AlphaGo基于现在的学习方法还做不到。
短期来看人获胜概率小,但长远来看(未来5-10年)人还有机会,因为人也有很强的学习能力,可以从少量跟AlphaGo的对弈的棋局中快速学习。尤其是在价值判断这块,人和机器都还没有弄明白怎么回事,在没有明确的规则时,人相对于机器还有机会。
另外,如果还是基于现有的学习体系,即便再给AlphaGo一亿副棋谱,再添加一万块GPU,它进步的速度也终将放缓,因为新增的棋谱和计算资源相对于2*10171这个搜索空间来说只是沧海一粟。
现在人类跟AlphaGo处在一个信息不对称的局面。人类跟AlphaGo对弈的次数还太少,获得的信息反馈也还远远不够。如果能够把AlphaGo开放出来,让更多的职业高手跟它对弈,让年轻的棋手来学习它的下法和招数,相信人类棋手也能够从中学习到很多,从而再次进步。
3. AlphaGo不可能让专业棋手3子,目前人类职业棋手跟AlphaGo的差距也就在一个贴目的水平,没有大家想象的那么大。
即便AlphaGo 2.0能让之前的版本3子,也不能代表它能让职业棋手3子。 因为,AlphaGo的价值判断里只有输赢,没有赢多少一说。在做价值判断时,它也不知道自己是被让了子,它会根据当前(把让子优势算在一起的)盘面,去尽量选择获胜概率最大(风险最小)的一条路径走下去(哪怕只赢半目),这样就很容易下出缓手,从而给对手机会把让子的优势给捞回来。因此,AlphaGo 2.0让之前版本2子、3子的区别可能不会太大。
而职业棋手则不会这样,他们(在判断形式时)会忘记这两子的优势,(至少在前期会)继续用最强的招式来下,而不会让优势付之东流。加之AlphaGo的价值判断也不是精确解,之前下得过缓,后面一旦有一点估计不准确,就可能会输(机器不会累,情绪也不会波动,所以一台机器不会给另一台机器机会)。
其实贴目的差距(按中国标准7目半),在职业棋手看来,已经是非常大的差距了。很多职业高手,进入官子阶段后发现自己还落后对方7-8目,就会主动投子认输了。很多通过数子来决定胜负的比赛,输赢往往都在1-2目之间(比如柯洁就输给AlphaGo半目)。否则会被其他专业棋手笑话,自己落后那么多都不知道,点空能力太弱了。
4. 人类也有弱点,输在综合实力
人类会疲劳、面临心理压力和情绪波动。AlphaGo下棋没有连贯的思路,也没有表情,这让很多已经习惯跟人下棋的专业棋手很不适应。此外,人类在压力状态下容易犯错(比如今天柯洁在关键时候下出明显的败招),这些机器不会,有优势。所以,我只能说AlphaGo在综合实力上超过了职业选手,在对围棋的理解上,AlphaGo可能已经接近或者略微超过了人类。在后半部分,人类还有希望。
总结
AlphaGo体现了人工智能的强大,但并没有攻克围棋这个难题。但它可以作为一种工具帮助人们更加深入的去理解围棋,其中的技术甚至可以应用到其它领域。人类可能现阶段仍然会输给人工智能,这是人与机器对比综合实力的落后。但人类也在进步,通过跟AlphaGo的对弈,人类也在重新认识围棋。
人脑复杂程度远远超过了AlphaGo现在使用的深度神经网络,而人类敏锐的抽象思维能在价值判断这个规则不明确的领域仍有希望。当人们对围棋有了更深入的了解之后,又会设计出更好的人工智能算法。两者相辅相成,互相促进,不管谁输谁赢都是人类文明进步的体现。人类的智能也将始终走在机器的前面,而不会被机器取代。
回答几个网友疑问
1. 如果人有快速小样本学习能力,人类在国际象棋这个项目上已经败给深蓝很多年了,为什么还没有反超深蓝?
答:国际象棋搜索空间小(2*1050),并且价值判断容易。这是因为各个棋子功能和活动范围差异很大,当棋子剩余不多时,根据剩余棋子就可计算出大概的得分,从而在不用下完的情况下就能基本判断出局面的好坏。
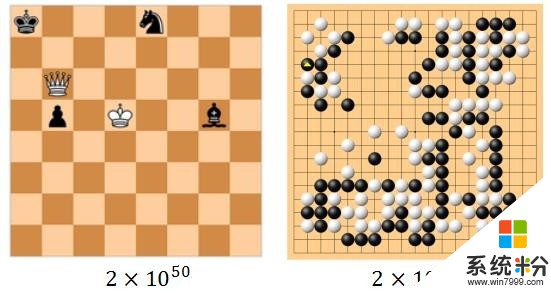
基于以上两个条件,国际象棋已经被人工智能算法攻克了,机器可以无限接近的找到最优解,所以人没希望反超了。但围棋空间大(2*10171),价值判断难(单个棋子在功能上没有任何区别,在棋没有下完之前如何判断优劣也没有明确的规则),现在人工智能的方法只得到一个粗糙的近似解,离最优解的距离还很大。还有很大的探索空间,因此,围棋和国际象棋不一样。
2. 机器越来越快,人哪里能算过机器,所以差距只有越拉越大。
答:首先,这个世界上最快的速度不是光,更不是计算机,而是人类的思维;最复杂的不是那些庞大的工程,而是人脑。我们有不少人已经清楚了AlphaGo的工作原理(因为它本来就是人类设计的),但世界上还没有人能清楚解释人类的思维和人脑的奥妙。因此,我们不能太早否则这两个未知物体的潜能。
机器重复规则明确的事情(比如搜索)速度比人要快,因为人会疲劳,需要补给。如果给定有限空间,机器会比人类更快的完成索搜,这也是人跟机器比的劣势。但围棋不是有限空间,机器能够投入到搜索的资源,相对于这个空间来说远远不够,光靠搜索不行(这也是早年间围棋AI水平太低的原因)。
因此,价值判断就变得很重要。但价值判断没有明确的规则,目前仍是一个说不清、道不明的东西,机器联想、抽象和穿梭不同时空和任务之间的能力未必比人要强。由于学习了比一般人类远远多的棋谱,AlphaGo的深度神经网络目前获得了跟人类接近(也许略微超过的)价值网络。但不要忘了,人脑的结构比现在AlphaGo的深度神经网络要复杂的太多了,其抽象能力也比现在的深度神经网络要强太多了。一个专业棋手一生所见的棋谱也不到AlphaGo的万分之一,但已经跟AlphaGo达到了非常接近的水平,如果人类棋手能看到更多有价值的棋谱,那又会如何呢?为什么说人类日后就没机会呢?
回顾历史,中国围棋曾有一段时间被韩国压制,韩国流在各种国际大赛上盛行一时。后来,中国国家队专门组织学习和研讨,吸取经验,近几年中国围棋又重回巅峰。这就是人类在围棋上学习进步的一个例子。
当前人类的围棋水平也比30年前强大太多了,历史也就是这样在进步。此外,人类多次从很少的事件中就快速获得丰富的经验,从而让整个人类的文明得以进步,这点能力不仅在AlphaGo之上,也远在任何的机器之上。
在获得更好的价值网络这方面,人类面临的问题是获取的学习样本还不足够,跟AlphaGo对弈的次数还太少。如果能有机会学习更多的样本,人类可以在价值判断上快速赶上或者超越AlphaGo,也是人类机会所在。在获得的更好的价值网络之后,如何抵抗自己的疲劳和情绪波动确实也是一个难点。因此,这是一个综合实力的比拼。
3. 机器越能存那么多东西,人脑才能存多少啊,所以差距只有越拉越大。
答:人脑真的不如机器能存东西吗?这点我很怀疑。人的一生所见、所闻、所感、所处环境都一一存储在大脑里(至于怎么存,怎么调出这都仍待探索),信息量之大完全不亚于世界上任何一台超级计算机和云计算平台。我们平日里能记起的只是其存储的非常少的一部分,并不是所有的信息。而且,人脑要处理人体这么多器官和细胞之间的协同,期间传输的信息量也比任何一个系统都要复杂。人脑从众多信息中快速调出自己想要的内容也,令人惊叹,信息访问速度超过世界上任何一个搜索引擎。因此,只能说我们还没有搞清楚人体(尤其是人脑)这个极其复杂的系统,而不能说人不如机器能存东西。
其次,AlphaGo根本也没有记忆功能。每次训练后,模型的参数都要被全部修改。训练调参数时,也只基于当前这一批训练样本,新增的几幅棋谱对提高它的棋力起不到任何作用。其实AlphaGo是通过自我对弈来生成很多棋谱,然后利用棋谱中的(两个连续的)盘面跟最后的胜负对应关系训练出价值网络来。因此,AlphaGo并没有大家想象的那种自我博弈就能自己不断进步的能力。









