猿辅导登顶MSMARCO:机器阅读理解超过人类水平、力压百度微软

*本文经AI新媒体量子位(公众号 ID: QbitAI)授权转载,转载请联系出处。
这可能不在大多数人的意料之中。
在著名的微软MSMARCO(Microsoft MAchine Reading COmprehension)机器阅读理解测试排行上,现在排名第一的团队,已经悄然变成了猿辅导。
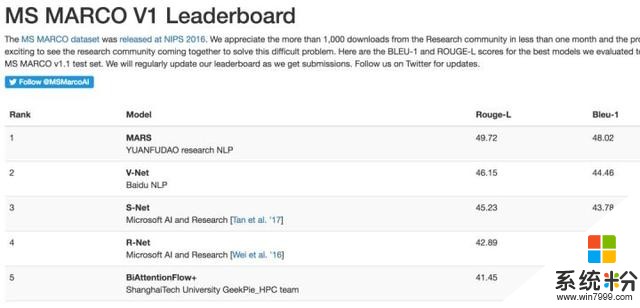
这意味着,一家提供中小学在线辅导的创业公司,在这场机器阅读理解实力比拼中,战胜了百度、微软这两个强劲的对手。
不止于此,猿辅导这个AI系统的表现,也超过了人类水平。
这是MSMARCO排行榜上首次出现的情况。猿辅导团队的两项测试得分为:49.72、48.02。而人类基准为47、46。
什么是超过人类水平?猿辅导给了一个解释:
MSMARCO数据集包含微软BING搜索的query以及query对应的top 10的搜索结果。超过人类的意思就是说,给定query和top 10搜索结果,机器找出的答案比普通人找的更准。
 MSMARCO官方发来贺电
MSMARCO官方发来贺电实际上,MARCO是微软基于搜索引擎BING构建的大规模英文阅读理解数据集,包含10万个问题和20万篇不重复的文档。
MARCO数据集中的问题全部来自于BING的搜索日志,根据用户在BING中输入的真实问题模拟搜索引擎中的真实应用场景,是该领域最有应用价值的数据集之一。
此前百度提供的信息称,在机器阅读理解领域,研究者多参与由斯坦福大学发起的SQuAD挑战赛。但相比SQuAD,MARCO的挑战难度更大,因为它需要测试者提交的模型具备理解复杂文档、回答复杂问题的能力。
今年2月,百度NLP团队在这个排行榜登顶时,得分为46.15、44.46。百度之前凭借的是V-NET单一模型。
而这次猿辅导使用的一个名为MARS(Multi-Attention ReaderS)的模型。这个模型采用层叠式的注意力机制,在多候选文档采样出多个候选答案区域,并在此基础上使用交叉投票模型,优化最终的答案。
这套系统来自猿辅导的NLP团队,主要成员包括柳景明、赵薇等人。
不瞒你们说,量子位当时就脑补了一句话:“赵薇团队击败了百度”。
不要当真、不要当真。据了解,这个赵薇是一位真汉子,加入猿题库前曾经供职过微软,就是那个AI黄埔军校一般的微软。
其实,猿辅导在NLP领域的成绩,不止这一件。更早一些时候,量子位还在arXiv上看到过一篇来自猿辅导的论文。这篇论文的作者是猿辅导NLP团队的王亮。
题目很直白:
Yuanfudao at SemEval-2018 Task 11: Three-way Attention and Relational Knowledge for Commonsense Machine Comprehension.
简单来说就是,猿辅导的NLP团队在SemEval-2018(国际语义评测)的一个任务上,获得了一个第二名的成绩。
这个任务名为Machine Comprehension using Commonsense Knowledge,意为:使用常识的机器阅读理解。
这个任务排名第一的是哈工大讯飞联合实验室团队。

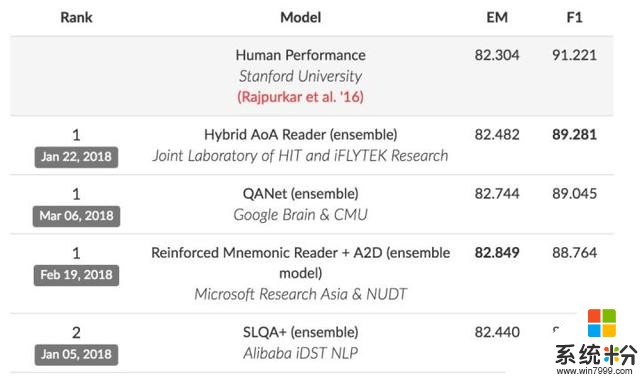
在另一个著名的机器阅读理解排行榜SQuAD上,目前猿辅导NLP团队的成绩排在第六名。
目前SQuAD有三个并列第一,除了哈工大讯飞联合实验室团队、微软亚洲研究院和国防科大联合团队之外,还有一个新面孔挤了进来:Google Brain和CMU联合团队。
看来,NLP领域的争夺会更激烈、更好玩了。
最后,量子位联系上了猿辅导,官方给出一些正式的回应。我们也列在下面,供参考。
1、猿辅导为什么要做机器阅读理解
从公司组建起,我们就有自己的应用研究部,AI做为教育未来应用的底层技术,我们公司也在着重打造自己在这方面的能力,包括猿辅导在线课程在内的公司各项业务,也都享受着AI技术带来的推动和变革。
机器阅读理解、语音识别、手写识别、图像识别等技术,分别被应用在了猿辅导的在线辅导课程,小猿搜题、小猿口算、斑马英语等等产品中,诸如小猿搜题的搜题功能,英文作文的手写识别及打分,小猿口算的拍照批改,斑马英语的绘本朗读打分等等。
机器阅读理解只是这个团队众多AI技术方向中的一支,公司一直在技术层面上做更多的尝试,这次取得第一也是阶段性的成果之一
2、研发团队的成员组成
猿辅导应用研究团队成立于2014年年中,一直从事深度学习在教育领域的应用和研究工作。团队成员均毕业于北京大学、清华大学、上海交大、中科院、香港大学等知名高校,大多数拥有硕士或博士学位。
研究方向涵盖了图像识别,语音识别、自然语言理解、数据挖掘、深度学习等领域。团队成功运用深度学习技术,从零开始打造了活跃用户过亿的拍照搜题APP——小猿搜题,开源了分布式机器学习系统ytk-learn和分布式通信系统ytk-mp4j。
3、此次提交给微软的模型是怎样的?为何会超过百度?
此次我们提交的MARS(Multi-Attention ReaderS)模型,采用层叠式的注意力机制在多候选文档采样出多个候选答案区域,并在此基础上使用交叉投票模型,优化最终的答案。
在可评测的指标上,猿辅导此次上传的MARS是MSMarco的数据集上首次超过人类的模型,并且大幅超过第二名百度。根据团队介绍,这个数据集包含微软bing搜索的query以及query对应的top 10的搜索结果,超过人类的意思就是说,给定query和top 10搜索结果,机器找出的答案比普通人找的更准。
【关于超过人类数据,微软方面给出的说法是:Can your model read, comprehend, and answer questions better than humans? The below is current human performance on the MS MARCO task (which we will improve in future versions). This was ascertained by having two judges answer the same question and measuring our metrics over their responses.】
另外,我们的模型在semEval(国际语义评测)上的阅读理解task上,获得了第二名。此前曾在SQUAD数据集上,单模型第三。
本文转自量子位,作者允中。









