百度NLP团队新成绩:微软MARCO机器阅读理解排行第一
允中 发自 凹非寺
量子位 出品 | 公众号 QbitAI
百度宣布了一项AI方面的新成绩。
昨天,百度自然语言处理(NLP)团队研发的V-Net模型以46.15的Rouge-L得分登上微软的MS MARCO(Microsoft MAchine Reading COmprehension)机器阅读理解测试排行榜首。
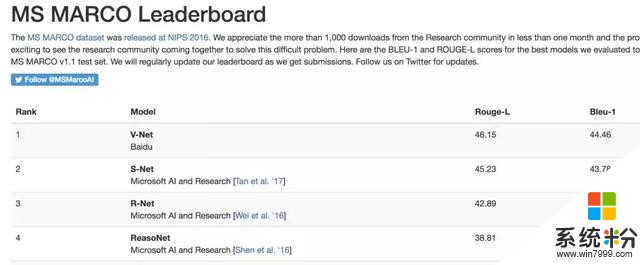
MARCO是微软基于搜索引擎BING构建的大规模英文阅读理解数据集,包含10万个问题和20万篇不重复的文档。MARCO数据集中的问题全部来自于BING的搜索日志,根据用户在BING中输入的真实问题模拟搜索引擎中的真实应用场景,是该领域最有应用价值的数据集之一。
此次百度NLP在MARCO提交的V-NET模型,使用了一种新的多候选文档联合建模表示方法,通过注意力机制使不同文档产生的答案之间能够产生交换信息,互相印证,从而更好的预测答案。
值得注意的是,此次百度只凭借单模型(single model)就拿到了第一名,并没有提交更容易拿高分的多模型集成(ensemble)结果。
百度提供的信息称,在机器阅读理解领域,研究者多参与由斯坦福大学发起的SQuAD挑战赛。但相比SQuAD,MARCO的挑战难度更大,因为它需要测试者提交的模型具备理解复杂文档、回答复杂问题的能力。

据了解,对于每一个问题,MARCO提供多篇来自搜索结果的网页文档,系统需要通过阅读这些文档来回答用户提出的问题。但是,文档中是否含有答案,以及答案具体在哪一篇文档中,都需要系统自己来判断解决。
更有趣的是,有一部分问题无法在文档中直接找到答案,需要阅读理解模型自己做出判断;MARCO也不限制答案必须是文档中的片段,很多问题的答案必须经过多篇文档综合提炼得到。这对机器阅读理解提出了更高的要求。
目前MARCO的排行榜上主要是百度、微软等玩家。而SQuAD的参与者包括:科大讯飞、阿里巴巴、微软、腾讯、Facebook、三星、复旦、CMU等众多机构。
百度表示,在自然语言处理领域已经过十余年积累与沉淀,更致力通过技术应用解决实际问题。这也是百度此次选择MARCO数据集而不是SQuAD的主要原因。
目前,百度的阅读理解、深度问答等技术已经在搜索等产品中实际应用。
“此次在MARCO的测试中取得第一,只是百度机器阅读理解技术经历的一次小考,”百度自然语言处理首席科学家兼百度技术委员会主席吴华表示,“我们希望……AI能够理解人类的语言、用自然语言与人类交流,让AI更‘懂’人类。”
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态









