解读R-Net:微软“超越人类”的阅读理解人工智能
人工智能的阅读能力在某些方面已经超越了人类,微软的 R-Net 就是达到了这一里程碑的人工智能之一。近日,谷歌工程师 Sachin Joglekar 在 Medium 上发文对 R-Net 进行了直观的介绍。
R-Net 论文:https://www.microsoft.com/en-us/research/wp-content/uploads/2017/05/r-net.pdf
今年 1 月 13 日,很多媒体的新闻报道称微软和阿里巴巴开发的人工智能在 SQuAD 数据集测试上,阅读能力上超越了人类。尽管这并不完全准确,但这些公司所开发的模型确实能在某些阅读任务的某些指标上超越人类水平。这篇文章为微软实现这一成果背后的人工智能 R-Net 提供了一个直观的介绍。
首先,给出阅读问题……
给定一个段落 P:
「特斯拉于 1856 年 7 月 10 日(旧历法的 6 月 28 日)出生于奥地利帝国斯米连村(现属克罗地亚)的一个塞族家庭。他的父亲米卢廷·特斯拉是一位塞尔维亚东正教神父。特斯拉的母亲是久卡·特斯拉(娘家姓为 Mandić),她的父亲也是一位东正教神父;:10 她非常擅长制作家庭手工工具、机械器具并且具有记忆塞尔维亚史诗的能力。久卡从没接受过正规教育。尼古拉将自己的记忆和创造能力归功于他母亲的遗传和影响。特斯拉的祖先来自塞尔维亚西部靠近黑山的地方。:12」
然后询问一个问题 Q:
「特斯拉的母亲具有怎样的特殊能力?」
然后提供一部分连续文本作为答案 A:
「擅长制作家庭手工工具、机械器具并且具有记忆塞尔维亚史诗的能力」

斯坦福问答数据集(SQuAD)包含大约 500 篇文章,涉及的问答对数量接近 10 万(上面给出的例子就取自其中)。
在我们介绍微软的用于阅读理解的方法之前,我们先简要介绍一下他们论文中大量使用的两个概念:
1. 循环神经网络(RNN)
RNN 是一种特殊的神经网络,可用于分析时间(或序列)数据。标准的前馈神经网络没有记忆的概念,而 RNN 则通过使用「反馈的」语境向量(context vector)而将这一概念整合了进来:
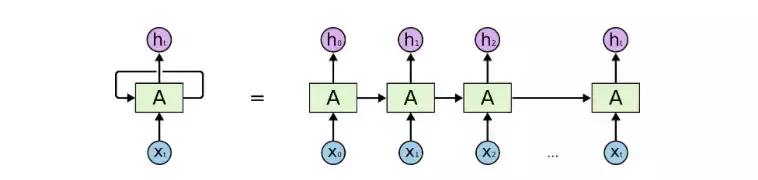
图 1:一种典型的 RNN
从本质上讲,其在任何时间步骤 t 的输出都是过去语境和当前输入的一个函数。
双向 RNN(BiRNN)是一种特殊的 RNN。标准 RNN 是通过「记忆」过去的数据来记忆历史语境,而 BiRNN 还会从反方向进行遍历以理解未来的语境:
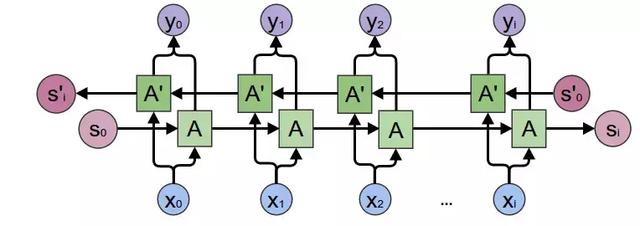
图 2:BiRNN
需要指出,尽管 RNN 理论上可以记住任何长度的历史,但通常来说整合短期语境比整合长期信息(相距 20-30 步以上)更好。
注:R-Net 使用 RNN(更具体来说是门控循环单元)的主要目的是模拟「阅读」文本段落的动作。
2. 注意力(attention)
神经网络中的注意力是根据人类重点关注视觉输入中的特定部分并大略查看其余部分的观看方式而建模的。
注意力可以用在这样的应用中:你的数据点集合中并非所有部分都与当前的任务有关。在这样的情况下,注意力是作为该集合中所有点的 softmax 加权平均而计算的。其权重本身则是作为 1)向量集和 2)某个语境的某个非线性函数而计算的。

图 3:在「飞盘」的语境下,网络会重点关注实际的飞盘和与之相关的对象,同时略过其余部分。
注:R-Net 使用了注意力来在另一些文本的语境下突出文本的某些部分。
R-Net
从直观上讲,R-Net 执行阅读理解的方式与你我进行阅读理解的方式相似:通过多次(准确地说是 3 次)「阅读」(应用 RNN)文本以及在每次迭代中越来越好地「微调」(使用注意力)各词的向量表征。
让我们分开解读其中的每一次过程……
第一次阅读:略览
我们从标准的 token(即词)向量开始,使用了来自 Glove 的词嵌入。但是,人类通常理解一个词在其周围词所构成的语境中的含义。
比如这两个例子:「May happen」和「the fourth of May」,其中「May」的含义取决于周围的词。另外也要注意背景信息可以来自前向,也可以来自反向。因此,我们在标准词嵌入之上使用了 BiRNN,以得到更好的向量。
问题和段落上都会应用这个过程。
第二次阅读:基于问题的分析
在第二次阅读中,该网络会使用文本本身的语境来调节来自段落的词表征。
让我们假设你已经在该段落的重点位置了:
「……她非常擅长制作家庭手工工具、机械器具并且具有记忆塞尔维亚史诗的能力。久卡从没接受过正规教育……」
在有了「制作」的前提下,如果你在问题 token 上应用注意力,你可能会重点关注:
「特斯拉的母亲具有怎样的特殊能力?」
类似地,网络会调整「制作」的向量,使之与「能力」在语义上靠得更近。
该段落中的所有 token 都会完成这样的操作——本质上讲,R-Net 会在问题的需求和文章的相关部分之间形成链接。原论文将这个部分称为门控式基于注意力的 RNN(Gated Attention-based RNN)。
第三次阅读:有自知的完整的段落理解
在第一次阅读过程中,我们在 token 临近周围词的语境中对这些 token 进行了理解。
在第二次阅读过程中,我们根据当前问题改善了我们的理解。
现在我们要鸟瞰整个段落,以定位那些对回答问题真正有帮助的部分。要做到这一点,光是有周围词的短期语境视角是不够的。考虑以下部分中突出强调的词:
特斯拉的母亲是久卡·特斯拉(娘家姓为 Mandić),她的父亲也是一位东正教神父;:10 她非常擅长制作家庭手工工具、机械器具并且具有记忆塞尔维亚史诗的能力。久卡从没接受过正规教育。尼古拉将自己的记忆和创造能力归功于他母亲的遗传和影响。
这都是指特斯拉的母亲所具有的能力。但是,尽管前者确实围绕描述该能力的文本(是我们想要的),但后面的能力则是将它们与特斯拉的才能关联了起来(不是我们想要的)。
为了定位答案的正确起始和结束位置(我们会在下一步解决这个问题),我们需要比较段落中具有相似含义的不同词,以便找到它们的差异之处。使用单纯的 RNN 是很难完成这个任务的,因为这些突出强调的词相距较远。
为了解决这个问题,R-Net 使用了所谓「自匹配注意力(Self-Matched Attention)」。
为什么需要自匹配?
在应用注意力时,我们通常会使用一些数据(比如一个段落词)来衡量一个向量(比如问题词)的集合。但在这个迭代过程中,我们会使用当前的段落词来衡量来自该段落本身的 token。这有助于我们将当前词与段落其余部分中具有相似含义的其它词区分开。为了增强这个过程,这个阅读阶段是使用一个 BiRNN 完成的。
在我看来,使用自匹配注意力这个步骤是 R-Net 最「神奇」的地方:使用注意力来比较同一段落中相距较远的词。
最后一步:标记答案
在最后一步,R-Net 使用了一种指针网络(Pointer Networks)的变体来确定答案所处的起始和结束位置。简单来说:
我们首先根据问题文本计算另一个注意力向量。这被用作这一次迭代的「起始语境(starting context)」。使用这个知识,再为该起始索引计算一组权重(为该段落中的每个词)。得到最高权重的词作为其答案的「起始位置」。
除了权重之外,这个两步 RNN 还会返回一个新的语境——其中编码了有关该答案的起始的信息。
再将上述步骤重复一次——这一次使用新的语境而不是基于问题的语境,用以计算该答案的结束位置。
搞定!我们得到解答了!(实际上,我们上述例子中给出的答案就是 R-Net 实际得出的答案。)
如果你对 R-Net 的详细细节感兴趣,请阅读他们的论文。如果代码能帮助你更好地理解(至少对我而言是如此),请参阅 YerevaNN 试图用 Keras 重建 R-Net 的精彩博文:http://yerevann.github.io/2017/08/25/challenges-of-reproducing-r-net-neural-network-using-keras/。









