机器这次击败人之后,争论一直没平息|SQuAD风云
夏乙 发自 凹非寺
量子位 出品 | 公众号 QbitAI
又吵起来了。
只因为最近在阅读理解这件事上,人类又被机器给超越了。
哈?人类又一阵地失守了?AI对鲁迅作品的理解超过我了?
щ(゚Д゚щ) 可怕可怕……
就为了这件事,争吵一直没平息。

机器阅读理解,是一场竞争激烈的比拼。
竞技场是SQuAD。
尤其是中国团队开始“刷榜”之后。过去一年,大部分时间都是科大讯飞团队和微软不同团队的竞争。7月微软登顶,8月科大讯飞首次折桂,9、10两月基本是微软天下,11月讯飞再次创出最佳成绩。
然后风云突变。先是腾讯突然杀入,并成功在12月底霸榜。然而“好景不长”,微软亚洲研究院和阿里巴巴iDST团队今年初先后发力,再次创出历史最好成绩,并且首次“超越人类”。讯飞的成绩实际已经被甩在第12位了。
SQuAD被称为行业公认的机器阅读理解顶级水平测试,可以理解为机器阅读理解领域的ImageNet。它们同样出自斯坦福,同样是一个数据集,搭配一个竞争激烈的竞赛。
这个竞赛基于SQuAD问答数据集,考察两个指标:EM和F1。
EM是指精确匹配,也就是模型给出的答案与标准答案一模一样;F1,是根据模型给出的答案和标准答案之间的重合度计算出来的,也就是结合了召回率和精确率。
目前阿里、微软团队并列第一,其中EM得分微软(r-net+融合模型)更高,F1得分阿里(SLQA+融合模型)更高。但是他们在EM成绩上都击败了“人类表现”。
这就是最近讨论特别激烈的阅读理解机器击败人类。
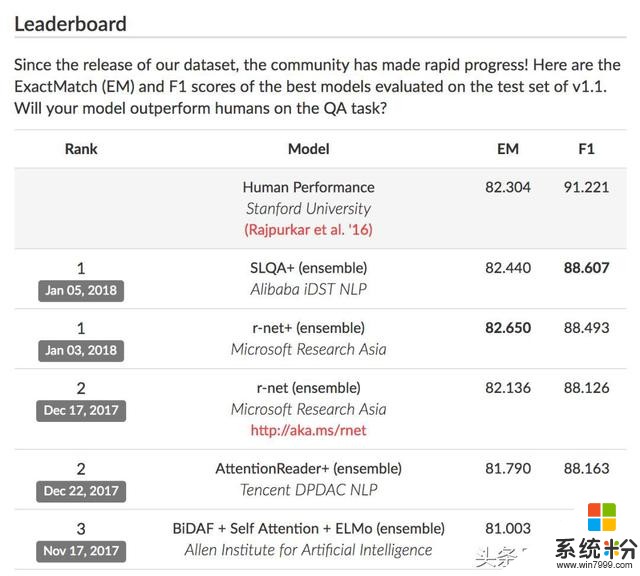
注意看,在F1得分上,代表了目前机器最先进水平的阿里和人类还有4.614分的距离。
好了,成绩公布完了,我们来讲讲试卷。
试题太简单了实打实的科学结果,看起来人类真的又败了。
别慌别慌。
“机器超越人类”的新闻每次铺天盖地出现,都会搭配着一波祛魅的声音,这次也不例外。比如说斯坦福NLP小组的官方twitter,就转发了这么一条:
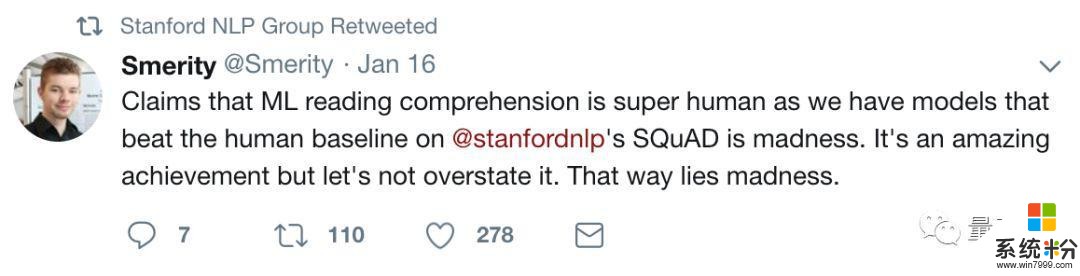
有几个模型在SQuAD数据集上超过了人类基线,就说机器学习在阅读理解上超过人类,简直是疯了。这个进展很棒,但是咱们别夸大好么~
机器取得了这么好的成绩,比赛主办方斯坦福NLP小组大概心里也不踏实。他们在Twitter上转发了一条回复:
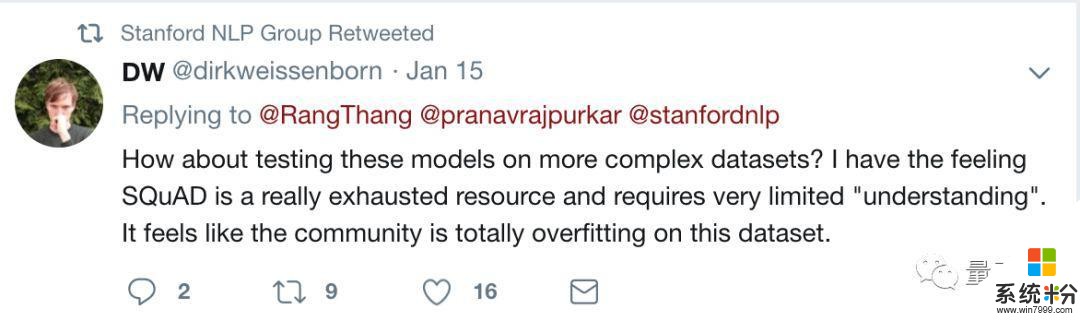
在更复杂的数据集上测试一下这些模型怎么样?我感觉SQuAD已经被探索得差不多了,也不需要什么“理解”。好像整个研究界都在这个数据集上过拟合了。
那么,这套可能已经被学术圈玩透了的测试究竟什么样?
2016年,斯坦福大学从维基百科上随机选取了536篇文章,随后采用众包的方式,由人类阅读这些文章后,提出问题并人工标注出答案,构成了包含10万多个问题的阅读理解数据集SQuAD。
对于这样一个数据集,以色列巴伊兰大学的著名NLP研究者Yoav Goldberg的评价是太局限(restricted)了。
早在好几个月之前,AI在SQuAD上接近人类得分的时候,Goldberg就专门写了个PPT,把SQuAD批判了一番。

他列举了SQuAD的三大不足:
受限于可以选择span来回答的问题;
需要在给定的段落里寻找答案;
段落里保证有答案。
对于这些不足,DeepMind前不久发布的NarrativeQA论文做了更详细的说明。
他们认为,由于SQuAD问题的答案必须是给定段落中的内容,这就导致很多评估阅读理解能力应该用到的合情合理的问题,根本没法问。
同时,这种简单的答案通过文档表面的信号就能提取出来,对于无法用文中短语来回答、或者需要用文中几个不连续短语来回答的问题,SQuAD训练出来的模型无法泛化。
另外,SQuAD虽然问题很多,但其实用到的文章又少又短,这就限制了整个数据集词汇和话题的多样性。
因此,SQuAD上表现不错的模型,如果要用到更复杂的问题上,可扩展性和适用性都很成问题。
DeepMind的论文说,包括SQuAD在内的很多阅读理解数据集都“不能测试出阅读理解必要的综合方面”。
Goldberg还从SQuAD中随机抽取了192个例子,具体分析了这个数据集的缺陷。他想看看,这些问题的答案是不是过于简单,需要经过怎样的推理。
结果是,有33.3%的问题需要同义词替换,9.1%的问题需要一些常识,64.1%的问题需要对句子结构做一些变换,13.6%的问题需要通过多个句子进行推理。
但这些问题所需的“推理”,其实也都不难。比如说下边这个例子,抓住了Shakespeare scholar这个关键词,就迎刃而解:

需要多个综合多个句子的,其实也不难:
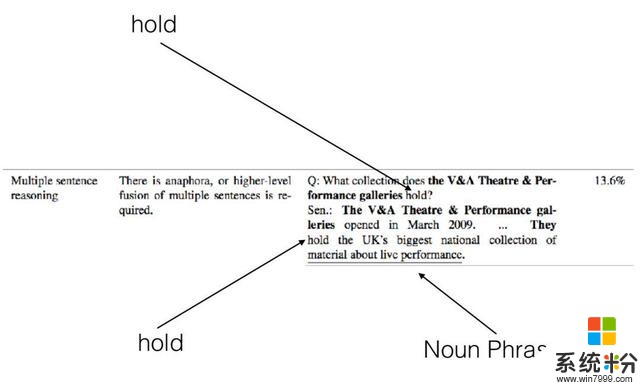
所以他说,SQuAD中的问题,只要找到合适的模板匹配方法,都能蒙混过关。
这基本上相当于,你家AI已经上初中了,你却还在考它两位数的加减法。
人类代表好像也不太行SQuAD虽然对AI来说简单,但对于人类来说却不见得。
我们知道,人类在这个阅读理解数据集上,EM分数是82.304,F1得分是91.221。不过,这个“人类代表”的分数究竟是怎么算出来的呢?
在评估人类成绩的时候,SQuAD团队从每个问题的3+个答案中,选择第二个作为人类答案,其他答案作为正确答案。在EM结果上,如果第二个答案和其他答案中的任何一个完全相同就算对,不同就算错;在F1结果上,会根据第二个答案与其他答案的重合度,得出一个0-1之间的分值。
很不幸,作为人类,我们各有各的习惯。就算是从文章中选择短语来回答,选择的内容长度也不一样。
Goldberg说,人类的“错误”,大部分都“错”在了选择的内容边界不一样,如果让几个人投票选出支持率最高的答案,人类的得分就会大幅提高。
在“输给AI”的时候,我们人类也会有这样一个疑问:这场比赛是谁代表了我们?
还是很不幸,代表人类的是SQuAD团队在众包平台MTurk上招募的兼职人员,他们需要在两分钟内回答5个问题,每个问题赚16美分。不得不说,量子位是不太相信这波人类代表对待比赛的认真程度……
微软亚洲研究院团队也说,SQuAD的成绩并不能代表计算机超越了人类的阅读理解水平,“超越人类”也不该作为媒体报道的噱头。
AI还是值得表扬的虽说“超越人类”有点夸大了,但是,这两年AI在SQuAD上的成绩的确进步神速。
这个数据集2016年10月发布时,斯坦福的团队自己也建了个逻辑回顾模型,在SQuAD上的F1得分是51%。
经过科研界一年多的折腾,前三名的EM得分已经全数超过80,F1得分也在向90分逼近,在这个数据集上全面超越人类指日可待。
最后,为了给人类增强信心,我们挑了几个AI出错的地方。
来让大家“嘲讽”一下,缓解下紧张的情绪……
请听题。

这是个跟氧气有关的词条。其中有个问题是:What is the second most abundant element?(含量排名第二的元素是什么?)
这个答案在文中有明确的表述:By mass, oxygen is the third-most abundant element in the universe, after hydrogen and helium. (氧元素排第三,前面是氢、氦)
很清晰对么?
但是微软和阿里巴巴模型的回答都是:氧。
……
再看一个例子。
这是一个与华沙有关的词条。其中有个问题是:What is one of the largest music schools in Europe?(欧洲最大的音乐学校之一是哪个?)
答案在原文中是这么说的:…the Fryderyk Chopin University of Music the oldest and largest music school in Poland, and one of the largest in Europe, the Warsaw School of Economics, the oldest and most renowned economic university in the country…
微软的回答是:Warsaw School of Economics。
这……
好在,阿里回答对了。
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态









