微软亚洲研究院梅涛博士:机器也能看懂视频,还能给“影评” ?| CCF-GAIR 2017
AI科技评论按:7月7号,全球人工智能和机器人峰会在深圳如期举办,由CCF主办、与香港中文大学(深圳)承办的这次大会共聚集了来自全球30多位AI领域科学家、近300家AI明星企业。最近将会陆续放出峰会上的精华内容,回馈给长期以来支持的读者们!
本次介绍的这位嘉宾是微软亚洲研究院资深研究员梅涛博士,分享主题为「视频内容的生命周期:创作,处理,消费」。

梅涛博士,微软亚洲研究院资深研究员,国际模式识别学会会士,美国计算机协会杰出科学家,中国科技大学和中山大学兼职教授博导。主要研究兴趣为多媒体分析、计算机视觉和机器学习,发表论文 100余篇(h-index 42),先后10次荣获最佳论文奖,拥有40余项美国和国际专利(18项授权),其研究成果十余次被成功转化到微软的产品和服务中。他的研究团队目前致力于视频和图像的深度理解、分析和应用。他同时担任 IEEE 和 ACM 多媒体汇刊(IEEE TMM 和 ACM TOMM)以及模式识别(Pattern Recognition)等学术期刊的编委,并且是多个国际多媒体会议(如 ACM Multimedia, IEEE ICME, IEEE MMSP 等)的大会主席和程序委员会主席。他分别于 2001 年和 2006 年在中国科技大学获学士和博士学位。
为什么要以「视频内容」为主题做分享?梅涛博士从三个方面讲了他为什么想和大家分享「视频内容」这个话题。首先视频跟图像相比信息更丰富,处理起来也更富挑战性;其次,计算机视觉技术领域,如人脸识别,人体跟踪等研究的比较多,而互联网视频内容相对来说研究的比较少;最后,他说在十年前就开始做视频方面的研究,所有人都说视频是下一个风口,今天看来这个说法也是对的。
在传统的视觉理解(2012年以前)的方法里,要做视觉问题基本上分三个步骤:
第一,理解一个物体,比如说识别一个桌子,首先要检测一个关键点(比如角、边、面等);
第二,人为设计一些特征来描述这些点的视觉属性;
第三,采用一些分类器将这些人为设计的特征作为输入进行分类和识别。
而现在的深度学习,尤其是在2012年开始以后:
“图像理解的错误率在不断降低,深度神经网络也从最早的8层到20多层,到现在能达到152层。我们最新的工作也表明,视频理解的深度神经网络也可以从2015年3D CNN的11层做到现在的199层。”
梅涛博士也在演讲中表示,视频内容的生命周期大致可以分为三个部分,即视频的创作、处理和消费。
Creation(创作)关于怎么去创造一个视频,梅涛博士给了一个基本概念。“Video的产生是先把Video切成一个一个的镜头,可以看成是一个一个断码,然后每一个镜头再组合编成一个故事或场景,每一个镜头还可以再细成子镜头,每个子镜头可以用一个关键帧来代表。通过这种分层式结构可以把一段非线性的视频流像切分文章一样进行结构化,这种结构化是后面做视频处理和分析的基础。通过这种结构化将视频分解成不同的单元,就可以做视频的自动摘要,即将一段长视频自动剪辑为精彩的短视频,或将一段长视频用一些具有高度视觉代表性的关键帧表示。这些摘要使得用户对长视频的非线性快速浏览成为可能。”
梅涛博士表示,微软目前将视频摘要的技术用在了Bing的视频搜索里,现在全世界有八百万的Bing用户通过一种叫multi-thumb的技术,可以快速预览每一个视频搜索结果。
Curation(处理)当用户有了视频之后,研究者要做的事情是给视频片段打上标签,这样后面的搜索就可以基于标签搜到视频的内容里面去。“我们最近的工作可以对视频内容打上1000多个静态标签和超过500个以上的动作标签。我们设计的P3D(pseudo 3D resent)是专门为视频内容理解而精心设计的3D残差网络。”
做图像分析目前最好的深度神经网络是微软亚洲研究院在2015年提出的152层的残差网络(ResNet),目前最深可以做到1000层。但是在视频领域,专门为视频设计的最有效的3D CNN目前才11层。
为了解决这一问题,梅涛博士表示,团队最近借用ResNet的思想,将3D CNN的层数做到了199,识别率能在UCF 101数据集上比之前的3D CNN提高6到7个百分点。这一对视频进行自动标签的技术,将会被用在微软的Azure云服务中。
实现了视频自动标签技术外,梅涛博士还阐述了团队“更进一步”的研究工作:用一段连贯通顺的自然语言,而不是孤立的单个标签,来描述一段视频内容。
“比如给定这段视频,我们能不能生成一句话来描述这个Video?以前我们说这个Video是一个舞蹈,现在可以告诉你这是一群人在跳一段什么舞蹈,这个技术就叫Video Captioning(视频说明)。这个技术使得自动生成视频的标题成为可能。”
微软亚洲研究院目前把这个技术用在了聊天机器人的自动评价功能里,例如微软小冰,当用户上传视频给小冰,它会夸赞对方。在这个技术上线一个月后,小冰在某视频网站上的粉丝数涨了60%。当然,小冰现在还可以根据图片内容写现代诗,将来我们希望小冰能够根据视频来写诗。
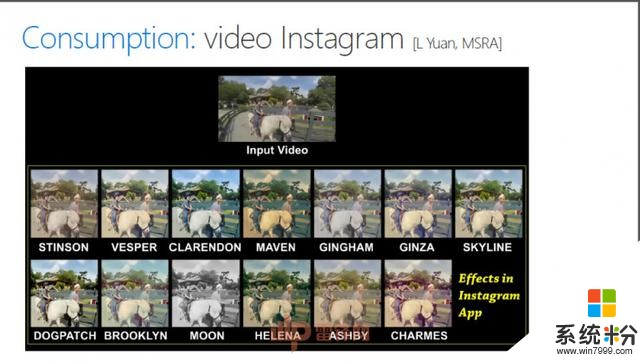
“我们也可以将Video进行编辑,加上滤镜,或是做风格的转换,把自然的Video变得非常卡通。视频中的人物分割出来可以放到另外一个虚拟的场景里面去。你可以想象,当两个人在异地谈恋爱的时候,我们能够给他一个房间,让他们在同一个房间里、在星空下、在安静湖面上的一艘小船上进行聊天。另外,我们也可以提供storytelling的服务,让原始的、没有经过任何编辑和处理的image、video集合变成一段非常吸引人的、有一定设计感和视觉感的故事,这段视频demo就是机器自动产生的效果。加上人工的处理,视频就可以变得更加时尚。”
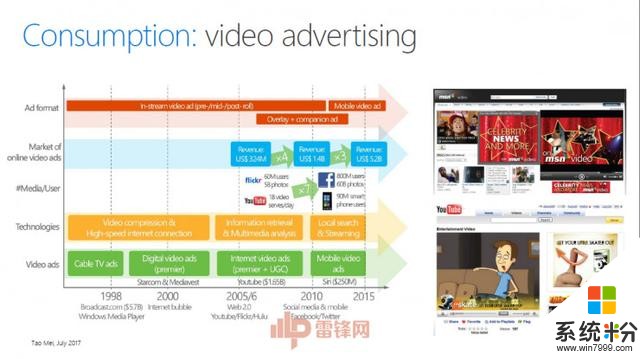
Consumption(消费)视频的消费往往和广告紧密相关。梅涛提到,做视频广告有两个问题需要解决:第一个问题是广告到底放在视频的什么位置;第二个问题是选什么样的广告,这个广告跟你插入点的信息是不是相关,使得用户接受度更加好。
他们的解决方案是将视频进行分解,并计算出两种度量,一个是discontinuity(不连续),衡量一个广告插入点的故事情节是否连续;另一个是attractiveness(吸引力),衡量一段原始视频的内容是否精彩。对这两种度量进行不同的组合就可以满足符合广告商(advertiser)或用户(viewer)的需求。
最后梅涛总结道,在做科研的人看来,AI也好,深度学习也好,落地都有很长的路要走。“虽然计算机视觉已经发展了50多年,虽然现在AI炒的很火热,但做科研和技术的,还是要脚踏实地去解决一个个的场景和一个个底层的基础难题。”
以下是梅涛博士的现场分享实录,做了不改动原意的整理和编辑
很高兴跟大家聊一下视频内容领域。为什么讲视频内容呢?有三个原因:第一个原因是视频跟图像相比更加深入,视频是信息领域的东西,研究视频是一个非常大的挑战。第二是大家在很多专场看到视觉领域,人脸、安防方面的进展,视频领域对大家来说是相对比较崭新的东西。第三是我本人在十年前做视频方面的研究,所有人都说视频是下一个风口,今天看来这个说法也是对的。

计算机视觉(CV)可以认为是人工智能的一个分支,1960年代CV的创始人之一Marvin Minsky说,“给计算机接上一个相机,计算机可以理解相机所看到的世界。”这是做CV人的一个梦想。到最近的50年,CV领域发展有很多成果,如果来总结一下,从视觉理解角度来看,要做视觉问题基本上分三个步骤:首先,理解一个东西,比如说识别一个桌子,我们要检测一些线条,一些拐角。第二,人为设计一些特征来描述所检测的特征。第三,设计一些分类器。这是我们2012年以前大家做CV的三个步骤。

大家可以从这个图中看到CV的一些进展,举几个例子,比如说这篇论文SIFT(Scaled Invariant Feature Transform)文,已经被引用55000次了。另外,如果大家做人脸识别就会知道,需要定位人脸的区域。我们2001年有一个方法是Boosting +Cascade,做快速的人脸定位。到今天为止,虽然大家知道做人脸定位有很多深度学习的方法,但是这个方法依然是最先的必经的步骤之一。这个论文到目前为止已被引用了30000次,在学术界有一篇论文被引用超过10000次已经是相当了不起了。到了2012年以后,基本上所有人都在用深度学习,从Hinton的学生用AlexNet在ImageNet上面能得到近乎15%的错误率,从那开始,所有视觉的东西都在用CNN,代表性的有GoogLeNet,AlexNet等等,我们的任务也会越来越多,越来越有挑战,比如现在正在做的从图片中生成语言,不仅要在图片或视频中打上一些标签,还要把这些标签变成能用自然语言描述的一句话。
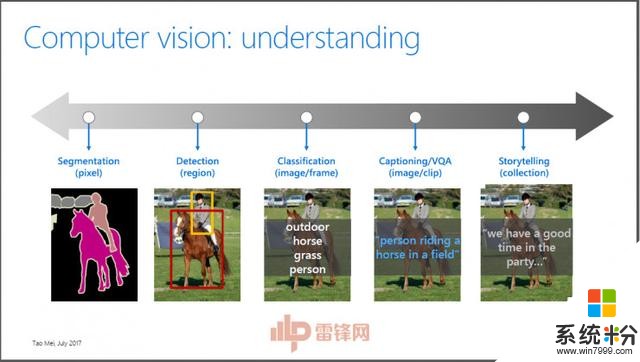
我们今天讲的是视频理解,如果从理解一个像素或理解一个图片或视频来说,可以把这个理解问题分成几个层次。最难的是需要理解图片或视频里面每个像素代表什么标签。再往上是我们关心每一个物体在什么位置、属于什么类别。第三部分是不关心这个物体在什么地方,你给我一图片或者视频,我就知道这个图片或者视频里面有什么标签。再往前走一步,比如说我给你一个图片,要求不仅要生成单独的标签,还要看你能不能生成一个非常自然的语言来描述这个图片。再往上,我给你一个图片,能不能给我一个故事,比如说现在机器能不能产生这样一个故事。

大家看一下这个图(见PPT),Image Classification(图像分类)从最早8层到20多层,到现在我们的152层。我们在微软做了很多工作,image里面有很多image recognition computational style transfer(图像识别计算的风格转换)等等。微软跟这个相关的产品有很多,比如说小冰不仅可以跟你用文字聊天,还可以通过图片和视频跟你交流。
从图像到视频,理解一个视频必须理解每一个帧里面的运动。为什么今天要谈论视频呢?

全世界现在每天有超过50%的人在线看视频,每天在Facebook上会观看37亿个视频,YouTube上每天会观看5亿小时时长的视频。我们做视频,大家首先想到的就是做广告,视频上面的广告每年都是30%的速度递增的,在YouTube上面也是每年30%的增长态势。人们在视频上花的时间是图片上的2.6倍。视频的生成比文字和图片要多1200%。2016年中国视频用户超过7亿。
今天从另外一个角度来看视频内容的产生、编辑、管理会经历哪些过程,有哪些技术来支撑,我们从Creation(创作)到Curation(处理)、到Consumption(消费)的顺序来讲。
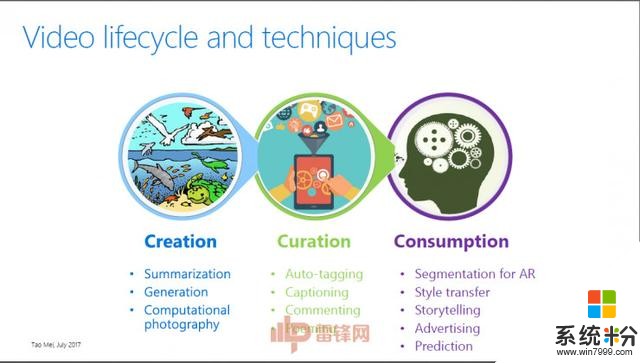
怎么去创作一个视频?这里面有一个基本概念,视频的产生是先把视频切成一个一个的镜头,你可以看成是一个一个断码,然后每一个镜头再编成一个故事,每几个语言可以放成一个故事。每一个镜头可以分成子镜头,然后有一个数据,这是我们做视频的前提。
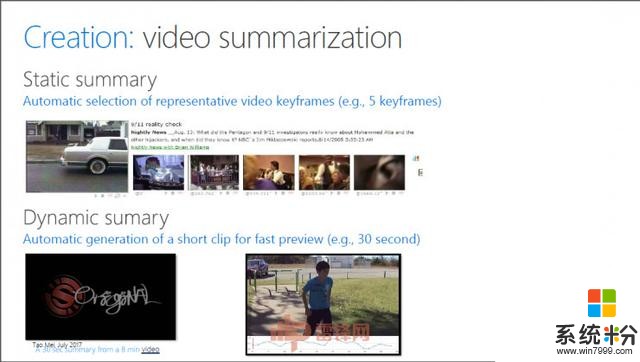
今天一个视频,可能15分钟,可能是1个小时,能不能给你5个关键帧你就知道这个镜头。一个8分钟的视频能不能生成30秒的内容,比如说来了一个运动视频,通过智能分析知道这个运动视频里面哪个部分最应该看,这是它的重点。
另一个话题是视频生成,今天我给你一段文字,你给我生成一个新的视频,这个事情听起来天方夜谭,但是值得挑战。我告诉你生成一个视频,也就是一个数字8在上面不停的游动。另外给你数字6和0,能不能让数字6和0在这里面游动,这个事情是非常难的。最近我们做了研究,发现可以做一些简单的事情,比如说一个人在烤牛肉。实际上这还是很难的,因为我们生成的视频准确性非常低,所以这是非常难的事情。

当有了视频之后要做的事情是给视频打标签,至今为止可以打上1000个的静态标签,你有了这些静态的标签就可以设置到内容里面去。比如说视频里面出现一个桥,这个桥的位置在哪里。比如说一些运动,这是我们能够识别出来的运动,左边都是运动的视频,右边是我们日常生活中的一些行为。有两个动作最难识别,一个是跳跃,一个是三级跳,但是我们现在已经可以区分出这些非常细微的差别。

这是我们今天讲的唯一的一个技术性的部分。我们最近做的一个非常好的工作,就是可以做深层次的网络,我们可以通过一些方式使得深层次的网络是可行的。比如说这个到现在可以做到152层,也可以做到1001层,性能超过了任何网络。我们能不能从这个网站的图片扩展到视频?我把二维的卷积盒变成三维的,当它卷积的时候是沿着X、Y和T这个方向卷积的。C3D模型是可以做到13层,它非常复杂。我们有一个想法,把它进行分解,一个是可以找出这个物体的数量,使的这个过程可行,另外还可以在图像上进行处理。我们做了很多工作,比如说这个视频是一个太极的动作,我们通过P3D可以找出来4个点,这个已经非常了不起了。

我们可以很精确的告诉你这个视频中每一个关节是怎么运动的(见PPT),比如说我今天做一个智能的健身教练,可以把你的动作进行分解,告诉你哪个动作是不准确的。
还有一个是Video captioning(视频说明),给你一个视频,能不能生成一句话来描述这个视频。以前我们说这个视频是一个舞蹈,现在可以告诉你说这是一个什么舞蹈。

这是我们生成的一个视频(见PPT)。小冰能够做auto-commenting(自动评论),不仅告诉你很美,还能告诉你美在什么地方。后面是一个小孩子,它说你的女儿很漂亮、很时尚。基本上它可以给自拍的视频做评论,给小孩的视频做评论,也可以给宠物视频做评论。

小冰还可以写诗,最近我们发表了一个小冰诗集。小冰说:“看那星,闪烁的几颗星,西山上的太阳,青蛙儿正在远远的浅水,她嫁给了人间许多的颜色”。

我们另外还做style transfer(风格转移),给你一个油画或者卡通,能不能把这个风格转移到视频中,可以把这个水的波纹表达出来。

下面这幅图是某个娱乐节目,我们可以把这个人物分割出来放到另外一个虚拟的场景里面去。你可以想象,当两个人在异地谈恋爱的时候,我们能够给他一个房间,让他们在房间里面进行聊天。
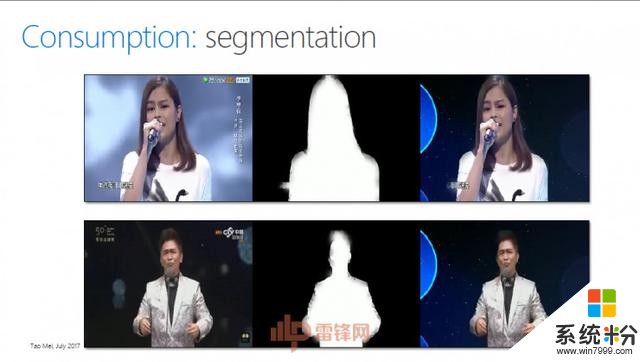
还有Storytelling(讲故事),我能不能给你提供服务,让你的图片、视频变得更好,这都是机器产生的效果(见PPT)。这个风格叫Fashion,我们只要加上人工的处理,视频就可以让你的图片变得更加时尚。这很容易用在一些to C(针对消费者的市场)的场景里面。
讲一下最后一个题目,这个广告是我十几年前加入微软的项目。那时候我们做的视频广告有两个问题需要解决:第一个问题是广告到底放在视频的什么位置;第二个问题是选什么样的广告,这个广告跟你插入点的信息是不是相关,使得用户接受度更加好。这两个问题怎么解决?当时我们提出一个方案,我来了一个视频,把这个视频分解,我们有几个值,第一个是discontinuity(不连续),看每一段是不是可以做广告,它的间断点使得用户的接受度更好。还有就是在是激动人心的阶段放广告。另外一个是Attractiveness(吸引力),让它变得可计算,当时我们有两个曲线,这两个曲线有不同的方式,第一种方式是要符合广告商的需求。

这个视频里面,当出现车子爆炸的镜头,我们可以识别出来这个内容,可以在这里放广告,使得广告和内容无缝连接在一起。我们也可以在故事需要的地方放广告。
刚才讲了很多场景和技术,但是在做科研的人看来,AI也好,深度学习也好,落地有很长的路要走,我们要脚踏实地的一个一个的去实现。
这就是我今天的演讲,谢谢大家!
整理编辑









