专访微软亚洲研究院副院长张益肇: 我们在为 MSRA 布哪些医疗局?
“作为一个研究人工智能二十多年,同时在医学影像处理方向耕耘八年的过来人。我认为现阶段医疗人工智存在的一大挑战是,从业者们既没捋顺流程,也没想清模式。单纯觉得我有AI技术,有几家合作医院,就能大干一场。现在风口的确很火,很多基金也愿意投钱。但医疗与其他行业不同,它是一个文火慢炖的过程,不见得那么容易。”
在与微软亚洲研究院副院长张益肇博士对话的一个多小时里,他不断在强调人工智能在医疗领域的长期价值,但也有存在一些短期的担忧。

张益肇博士现任微软亚洲研究院副院长,负责技术战略部。他于1999年7月加盟微软亚洲研究院,从事语音方面的研究工作,曾任微软亚洲工程院副院长,是2003年工程院的创建者之一。
微软之前,张益肇博士是全球最大语音识别公司Nuance Communications研究部创始人之一。张博士毕业于麻省理工学院,获电气工程和计算机科学学士、硕士和博士学位。
以下是与张益肇博士的谈话内容:
:您怎么看待今年医学影像+AI大热的现象?
当然是好事。
我经常谈一个观点,人类如果想要健健康康活到100岁,技术,将扮演着非常重要的角色。近几年我也看到不少计算机界精英投入大量人力财力到医疗领域,如此大规模的医工交叉大潮让人非常激动人心。
这里我也不得不提醒大家,在医疗领域,无论是创业者也好,投资人也罢,必须要有愿意长期投入和投资的心态,切勿焦躁,保持平常心。
我个人研究人工智能二十几年,其中八年时间在专攻医疗,我不觉得这个领域很容易出成果。
医学技术的落地,不仅要千辛万苦找对场景,还要说服政策制定者、监管部门、医院采购者、科室主任、临床医生、病人等无数当事人证明技术的有效性、安全性和可行性。最后,你还要明白你的产品谁来买单。
现阶段行业存在的一个挑战在于,很多时候,大家这三大关都没有想清楚。单纯觉得我有AI技术,找到一些合作对象,就能大干一场了。
现在医疗+AI的确很火,很多创投也愿意投这个钱。但从长久来看,不见得那么容易,也没那么快,大家一定要沉下心多调研、多思考、多学习。
美国很多新药研发公司可以获得大量的融资,有些甚至不盈利也能够上市。大家期待它所研发的新药品最终能通过FDA,并且在药效达到预期后,公司市值能够上涨5倍、10倍甚至更多。当然,面临一文不值的风险也非常巨大。
大家在投资时明知道风险很大,明知短时间内账面并不可观,但仍旧愿意投资、愿意长期等待,因为他们能够真正理解风险。
国内医疗人工智能大潮中,我最担心的是国内医疗人工智能创业者和投资者并没有真正理解风险,就开始投入大量资源在其中,这很可怕。
:微软目前在医疗AI方向有哪些研究?
微软其实在医疗领域投入很多,在世界各地的研究院里有不少同事在做相关方面的工作。
医学影像处理这块,微软亚洲研究院和微软剑桥研究院都有在做。不过微软亚洲研究院聚焦在病理切片,英国剑桥研究院专攻CT。
我们微软亚洲研究院近几年开始钻研脑肿瘤病理切片的识别和判断,通过细胞的形态、大小、结构等,去辅助分析和判断病人所处的癌症阶段。近两年在该领域我们基于“神经网络+深度学习”的模式取得了两大突破:
首先,实现了对大尺寸病理切片的图片处理。通常图片的尺寸为224*224像素,但脑肿瘤病理切片的尺寸却达到了20万*20万、甚至40万*40万像素。对于大尺寸病理切片影像的识别系统,我们没有沿用业内常用的数字医学图像数据库,反而在ImageNet的基础之上利用尽可能多的图片,通过自己搭建的神经网络和深度学习算法不断进行大量训练而成,最终实现了对大尺寸病理切片的图片处理。
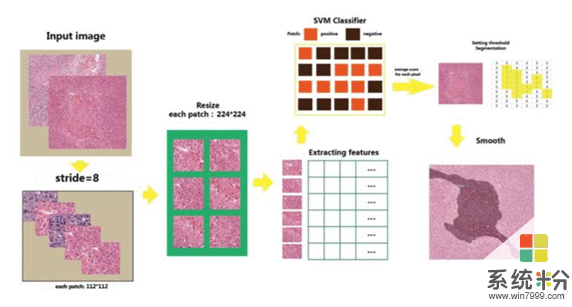
其次,在解决了细胞层面的图像识别之后,又实现了对病变腺体的识别。
对病变腺体的识别,主要是基于医学角度三个可以衡量癌细胞扩散程度和预后能力的指标:细胞的分化能力,腺体的状况和有丝分裂水平。我们针对这三个角度,通过多渠道(Multi-Channel)的数据采集和分析,希望在未来帮助医生实现对病人术后、康复水平乃至复发的可能性做出预估和判断。
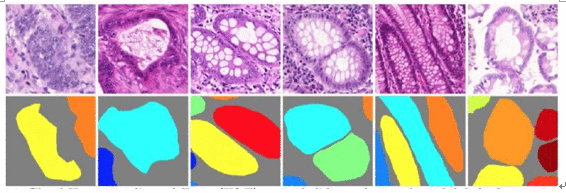
该研究结果也可以扩展至其他疾病的二维医学影像的识别和判断,例如我们正在研究的肠癌等。此外,我们还在研究肝肿瘤患者的CT三维影像。
除了医学图像外,我们在医学文献的处理和理解上也有所研究。
全球平均每年有将近50多万篇医学研究文献发表,这种情况下,医生在查询所需文献时,不可能覆盖到位。
我们微软亚洲研究院具体是如何解决这一问题的呢?比如医生在寻找遗传基因的研究与哪几篇文章相关,我们会通过算法自动对相关文献进行关联。另外也在做不少与医学相关的自然语言处理,比如不同病人想要问相关的医疗问题,可能有很多不同的方法来表达。而在话语里又有像阿莫西林等药物在不同医院里有几十种、上百种叫法。
我们的工作就是用AI技术让这些话语和词汇的不同表达,转换为机器可以理解的统一信号。最终以AI系统的形态解答各种医学问题。
:团队研究医学影像处理这8年间,相比于过去有哪些大的进步?
深度学习算是一个比较大的跨越,坦白讲,2013、2014年前后,深度学习开始被应用到医学影像分析当中。按照传统方式,很多医学影像分析题目要做特征提取,这个特征甚至可能是细胞,过程较为复杂。
而深度学习可以自己学习并提取特征,节省了很多设计特征的时间。
其次就是迁移学习,我们在ImageNet上训练出一个深度学习模型,以它作为基础做医学影像分析,虽然ImageNet上的图像为自然图片,但从中训练出来的特征提取能力,对医学影像也相当有用。
:这个过程中您发现了哪些新的思路,并走过哪些弯路?
2012年我们团队开始用弱监督学习来更好地使用数据,这是一个对我们意义很大的方向。
大家也都知道医生的时间非常宝贵,如果你没办法尽量节省他们的精力与时间,相比而言,你获得数据的能力会更弱。用更优秀的算法去填部分数据的坑,这是一个很好的思路,而不是单纯想着从医院拿更多数据。
弱监督学习在医学影像中的应用会是一个好的开始,也是一个值得长期投入的方向。
找到好的场景,再找到好的数据库,其实比大家想的要耗时。很多时候,找到一个优质数据库外,还要找到一个既懂技术,又能帮忙做标注的医生。
对于我们走过的弯路,更多是认知和思维上的弯路吧:过早觉得我们已较好地解决了医学问题。
包括我们在内的很多公司用Kaggel数据做基础训练,但这种研究仅是长期研究的起步,而且这个起步往往并不见得特别有用,所以大家应理性看待从Kaggle中训练出的结果。
在医疗+AI方向,大家不要迷信短时间内得到的数字结果,一定要做好长期投入的准备。
语音识别从1960年代就开始萌芽,直到1970也还是所谓的非连续性语音识别,离绝大部分使用场景很远。尽管语音识别在今天已经解决得很好,但在复杂环境和语境下的识别率仍旧不是特别理想。
人工智能在医学中的应用亦是如此。
:像您刚提到的深度学习和迁移学习让医疗人工智能大跨步发展,但这两者的不可解释性使得很多医学问题无法询证,这个难题目前微软亚洲研究院有没有一个标准对其进行参考?
深度学习的可解释性确实是一个很热的题目。
算法可解释性通常可以用看边界和颜色特征来判断正负,偏统计学方法,但也很难说出具体原因。
其实很多医学任务也是靠统计来做。之前有医生提到说,假如一个肿瘤小于5厘米和大于5厘米该各应怎么判断。大家提到“5厘米”这个单位也凭经验去描述,为什么是5,而不是5.1或4.9。
我的意思是,医学本身很多判断是依照经验来做,这些经验里,也存在一些无法解释的因素,因此不能完全否定“不可解释性”。
很多AI功能尤其像靠深度学习训练出来的系统,除了给你一个明确的判断外,还会生成百分比形式的“程度值”做参考,这个程度值体现机器对判断的“自信”与否。
现阶段我们希望只做辅助医生的工具,最后的结论还是需要医生自己判断。
任何系统都多多少少会产生一定的误差和偏差,哪怕简单的血压仪也可能存在偏差,所以最终还需让医生把所有信号整合起来判断机器给出的结果是否合理。
:也确实因为深度学习存在的弊病,最近Hinton提出要“抛弃”反向传播,您怎么看待这件事的?
反向传播也有几十年的历史了,这期间陆续有人提出不同的想法、不同的算法。
人的学习能力很强,无需很多数据,往往通过一两个样本就能学习、分类,但现在机器没有办法靠少量不同样本进行驱动。
所以人工智能在算法层面可提升的空间很大,所以要有新的学习方法来做,尤其像可供使用数据量较小的医疗领域。
:相比于医学影像处理,语音电子病历录入服务各方面的条件更为成熟,Nuance和讯飞都已在医院落地,微软亚洲研究院目前有没有切入这个方向?
推出这类产品,需要做的事情就比较专比较细了。
我加入微软之前在Nuance Communications做语音识别,你提到的语音电子病历录入是Nuance的主要业务之一。
但国内很多人可能有所不知,Nuance的业务里,语音转录系统只是一方面,另一方面Nuance还需雇人把机器转好的文字,进行人工整理。所以Nuance提供的是一整套服务,而非单一的语音识别这一环节的产品。与此同时,Nuance针对不同场景、不同科室做不同的产品优化和服务。
所以如果做这类产品,研究之外的任务和工作相对来说会比较多。
:您此前一直研究语音,是什么原因致使您开始做跨度很大的医学影像?
从研究角度讲,无论是语音还是影像,两者之间有很多相通点,都是基于机器学习作为发动机,数据作为汽油来建模、判断。
当然了,医学影像也确实有很多专业知识需要学习,更具挑战性,同时也更有意思。因为你需要跟很多不同领域的人一起学习,这个过程非常有意思。
另一方面,那时候我母亲得了癌症,我当时心想医学如果借助计算机技术一定会找到更多新的方法和新的应用场景。作为普通民众,我觉得这对身边人,对社会非常有意义。作为研究人员,这个研究方向会非常有前景。
:微软亚洲研究院的医学影像数据来自哪些地方?与哪些机构有合作?
主要还是来自于公开数据集,首先这类公开数据标注经过很多人审核。其次,你要发表结果的话,同一类数据集上大家才有可比性。
在某些特定领域,我们与浙江大学前副校长来茂德团队合作探索病理切片分析,来校长在大肠癌方向有着很多积淀。大肠之外也有研究肺癌等国内常见的几个方向。除此之外,生活习惯和饮食健康也所有探究。
:提到肺癌等国内常见的方向,上次我跟讯飞陶晓东博士交流时,他讲到其实目前选择做眼底、肺结节这类常见的、公开数据较多的领域,可以反映出大家创新力不足的现状。微软亚洲研究院在布局常见的方向之外,还在探索哪些挑战性特别大的方向?
我们现在做病理切片的一大原因,就是因为病理切片分析极具挑战性。
首先病理切片单个数据很大,一张图最大可达40万×40万像素,面对这么大的数据该怎么分析?要怎么才能把这个系统应用得很好?这是很有趣的问题。
如此大的图像,单是传输就已是一项很大的挑战,在此基础上还进行分析,计算量会非常巨大。
好在微软亚洲研究院也有很多同事是系统方面的专家,研究高速运算,基于此,我们可以通过整合研究院不同团队的专长来做这件事。
:这个过程当中微软亚洲研究院各个技术部门之间如何打配合?
各部门之间的合作其实蛮多。
2015年我们视觉计算组发明的ResNet大家都很熟悉了,它就是一个特别好的图像特征提取方法,有了它之后,我们就在考虑如何用ResNet提取医学影像特征。
微软亚洲研究院已经在做一些通过看一张图然后对它进行标注的技术,当机器可以给一张图自动标注的话,这就表明机器在一定程度上理解这张图,不仅知道里面有哪些物体,同时也知道里面物体及场景之间的关系。
这属于更高层次的理解。
回到肺结节上,通常情况我们只是去判断某块小区域是不是肺结节。其实有时候通过分析肺本身以及人体的构造,也可以得出其他有用信息,而这些肺结节之外的信息,往往对诊断起到非常重要的作用。
目前大部分系统并没有有效利用到这些“其他”信息,但影像科医生与机器不同,他们在读片时,肯定会对这些信息有宏观的认知。所以我也经常在讲,人工看一张图片时,他不会只看一小部分,而是会形成一个整体的认知去判断。
所以,无论是一张普通海景照片中船和海的关系,还是医学影像中肺结节和其他组织信息的关联度,很多方面是相通的。我们希望把对常规图像的认知和理解,迁移到医学影像中,这是一项非常重要的工作。
:如果还要判断其他组织信息,那么在对众多非目标对象的分割上,是否有产生更多更复杂的新问题?
确实如此,我再举个例子,正常人的心脏在左边,因此做内脏分割时,会有这样的预知。但是也不排除少数人心脏长在右边的可能性,类似这种情况容易让机器产生误判和混淆,因此需要有更高层面的的知识理解。
但总体而言,现在在做的机器学习研究,无论是检测、识别还是分割也罢,很多地方都是相通的。
:除了影像和语音语义之外,微软还有哪些医疗人工智能方面的研究?
我们在大数据处理上探索也非常多。
负责管理微软全球研究院的Eric Horvitz,他既是医学博士,也是哲学博士。Eric Horvitz做了很多非常有趣的研究,通过用户在互联网上的搜索词,来判断你是否有一些疾病和症状。
:那么这个研究的最终形态是以一个什么样的终端功能或者服务去呈现?
我们有一项服务叫微软Health,就是用一些功能,来提供insight,这些insight一方面给用户看,一方面提供给医生参考。
比如通过系统收集到很多人的血糖、血压甚至睡眠和运动量数据后,存储起来进行长期的追踪和分析。基于此,把这些信息全部整合起来后更好地帮助医生、帮助用户自身。
我们也与美国匹斯堡大学医学中心UPMC合作,探讨用AI挖掘有效健康信息。
一方面我们在做很多基础研究,另外一方面,微软也希望寻找更多合作伙伴,探讨可以着陆的场景。
:“长期”大概是多久?
取决于场景本身。
我们与盖茨基金会的合作中,在非洲用机器来判断一个人是否有得疟疾,同时得出病症的严重程度。
在国内大家谈机器与医生的对比,但非洲这些地方连医院医生都没有,相对来讲,有一个工具给病人诊断,已经是一个很大的医疗进步。
这个例子,我相信在未来短期三五年之内,会有着很大的帮助,现在有些产品已经在一些相对落后的国家试用。
但在比较发展的国家,医生已经有比较成熟、习惯的工作方式,供应商的系统要进入到医院,需要想清楚整个环节才有办法帮助到医生。因为多种客观因素,会致使过渡时间更长。
当然了,如果找好场景的话,最快两三年之内就可以安全着陆。
:您觉得哪几个场景前景相比而言会比较明朗?
目前市场上很多企业在做诊断,其实我觉得可以往前探一步:做好分割。
一个医生在做放射性疗法之前,要先把不同放射性疗法所影响到的这些不同区域标出来,并进行分割。分割工作的人力和时间成本很高,如果现在有一个工具能够自动进行分割,再让医生去确认,需求会比较大。
当一个系统先对影像做标注,医生去看的时候已经有90%完成地很好,没做好的地方医生再去修改,最后一关由医生来把守,这种辅助工具医生也很乐意接受。
:谈谈未来微软医疗人工智能的展望?
我们希望能从人一出生开始便了解你的整个健康情况,通过收集身体信息,实时分析你生活和机体哪些地方需要改进,如饮食、睡眠、运动、病痛等等。
我觉得在未来应该会演进为这种形式,每个人都有一个专门属于他的医疗人工智能健康助理。
:产品形态是2C的形式吗?
这个倒不见得是2C,更多是2B2C模式,产品在面向终端用户时也要有医生的参与。像美国就有很多家庭医生,可通过家庭医生把系统推向病人。
:哪些新的人工智能技术将会对医疗行业带来巨大变革?
其实“如何把不同的信息在不同层次进行整合”这一认知层面的课题,整个行业仍旧存在很多不足,现阶段单是把知识结构化就是一项很复杂的任务。如果解决了上述问题则对技术体系和行业的推动力将非常大。
我们先以机器翻译为例,大部分机器翻译还是单句单句翻,但一段段翻跟一句句翻就很不一样了,它涉及到“理解”。再以图像识别为例,机器识别出图像中有蓝色的天空和蓝色的海和帆船,但如果突然出现图像中的天空为红色,而它过去的训练集中没有对红色天空进行标注,那机器能懂得红色的天空代表是晚霞吗?
因此我们要让机器建立起一个对故事、对世界、对环境的认知能力。
这里的难点在于,它有很多很多参数的变化,你不可能让机器学习把整个世界的种种元素挨个看一遍才能理解。而是应该创建一种新的方法,把不同地方学到的知识给整合起来,从而解释出图像看起来是合理的。
医学影像的解释同样如此,医生在看MRI影像时,基于经验判断某个人是女性,但有一些地方却不像女性(如变性人等)。这时候要有更高层的知识能力、知识架构,也就是用Mental Mode去解释去理解,这会是一个很大的挑战,同时也是一个很大的机会。
:当前很多像医院等传统机构对AI处于观望状态,市场还需教育。企业应该如何让各行各业的人更快了解人工智能?
为什么互联网兴起后能迅速影响到各行各业?因为那时候大家即便不懂互联网,但至少有浏览器产品供我们使用,虽然有别于可触摸的实体物品,但我们可以看到互联网产品的界面,也可在上面进行操作和交互,这才使得人们对互联网的认知建立的如此之快。
人工智能普及进度慢,一大原因就是没有一些典型的终端产品让大家直接感受。要想教育一个市场,最好的方式就是让他们去体验AI的能力。
:您在微软亚洲研究院任职18年,谈谈这里留住您最大的一个原因是什么?
在这18年里,我最大感触是微软亚洲研究院为很多优秀的研究员创建了能够长期钻研细分领域课题的极佳环境。在微软亚洲研究院这样的基础研究机构里,好比在MIT、斯坦福,我们在长时间探索各式各样的有趣题目。
近两年量子计算很火,但很多人所有不知,我们研究院从十几年前便开始做量子计算了。除此之外,也有美国的同事在探索用DNA来存储信息,人体中一个DNA大概有4GB内存,你想想,一个细胞大小的体积便能存储4GB的内容,密度远高于我们用的SD卡。
像这种看得很远的方向,只有在研究院才有机会去接触,这对任何一位研究者都极具吸引力。
盖茨早在26年前便建立微软研究院,并且在同期启动三大研究组:自然语言处理组、语音组、计算机视觉组。
这些研究在当时来看,离落地非常遥远。
但微软今天能够站在人工智能最顶端,不是因为我们体量多大,也不是我们人才够多,而在于研究院和热爱研究的这一批批人早已为此准备26年之久。










