学界 | 中科大与微软提出Adversarial-NMT: 将生成对抗网络用于神经机器翻译
机器之心编译
参与:吴攀
生成对抗网络(GAN)与神经机器翻译(NMT)是当前人工智能研究的两个热门领域。近日,中国科学技术大学与微软亚洲研究院的研究者提出了一种新的框架 Adversarial-NMT,将这两者结合到了一起。机器之心对该研究的论文进行了摘要介绍,论文原文可点击文末「阅读原文」查阅。

摘要
在本论文中,我们研究了一种新的神经机器翻译(NMT)的学习范式。我们没有像之前的研究一样最大化人类翻译的似然(likelihood),我们是最小化人类翻译与 NMT 模型的翻译之间的差异。为了实现这个目标,受生成对抗网络(GAN)近来成功的启发,我们实现了一种对抗训练架构并将其命名为 Adversarial-NMT。在 Adversarial-NMT 中,NMT 模型的训练会得到一个对手的协助,这是一个精心设计的卷积神经网络(CNN)。这个对手的目标是找到该 NMT 模型所生成的翻译结果与人类翻译结果之间的区别。该 NMT 模型的目标是生成高质量的能够欺骗其对手的翻译。我们还采用了一种策略梯度方法来联合训练该 NMT 模型及其对手。在英法翻译和德英翻译任务上的实验结果表明 Adversarial-NMT 可以实现比几种强基准显著更好的翻译质量。
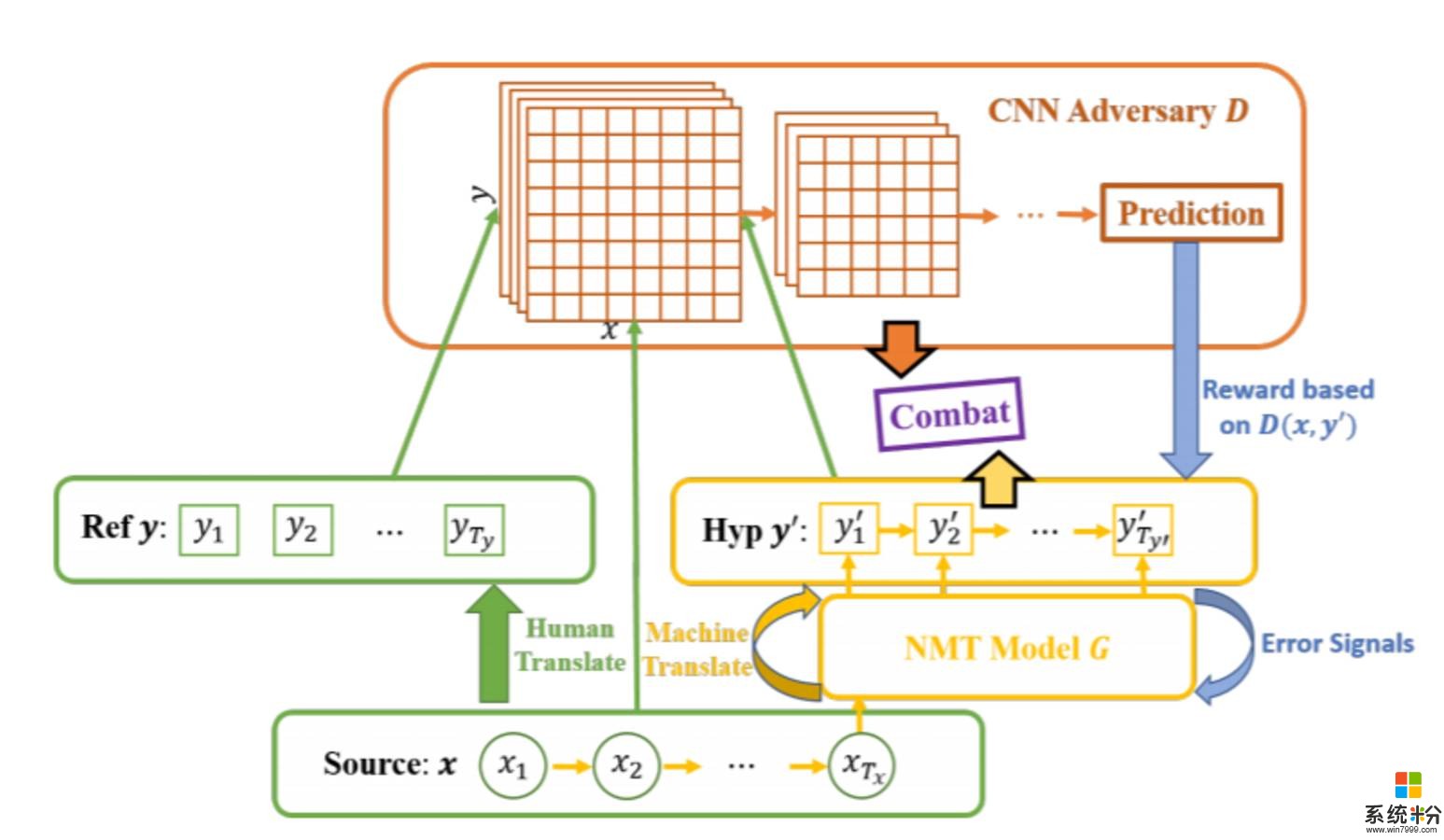
图 1:Adversarial-NMT 框架。Ref 是 Reference 的缩写,表示 ground-truth 翻译。Hyp 是 Hypothesis 的缩写,表示模型翻译的句子。所以的黄色部分表示 NMT 模型 G,其将源句子 x 映射成翻译句子。红色部分是对手网络 D,其预测给定的目标句子是否为给定源句子 x 的 ground-truth 翻译。G 和 D 互相战斗,通过策略梯度生成采样过的翻译 y' 来训练 D,生成奖励信号来训练 G。
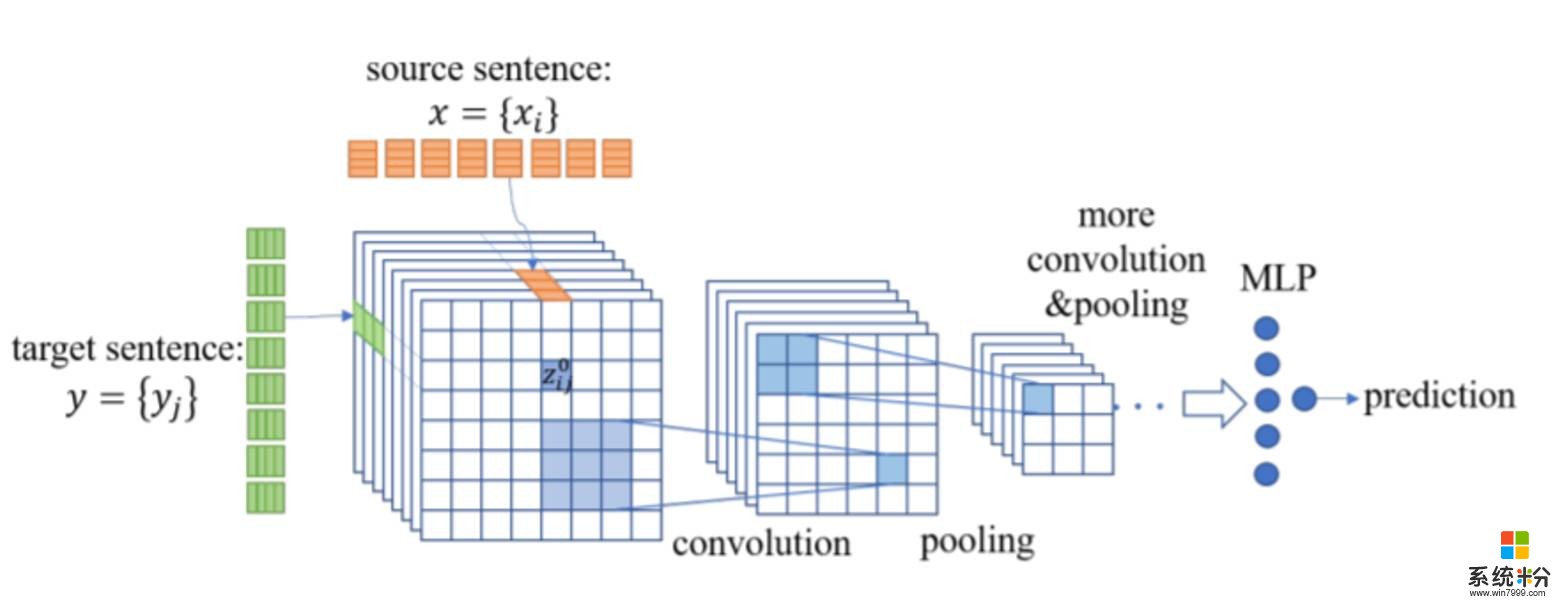
图 2:CNN 对手网络的框架
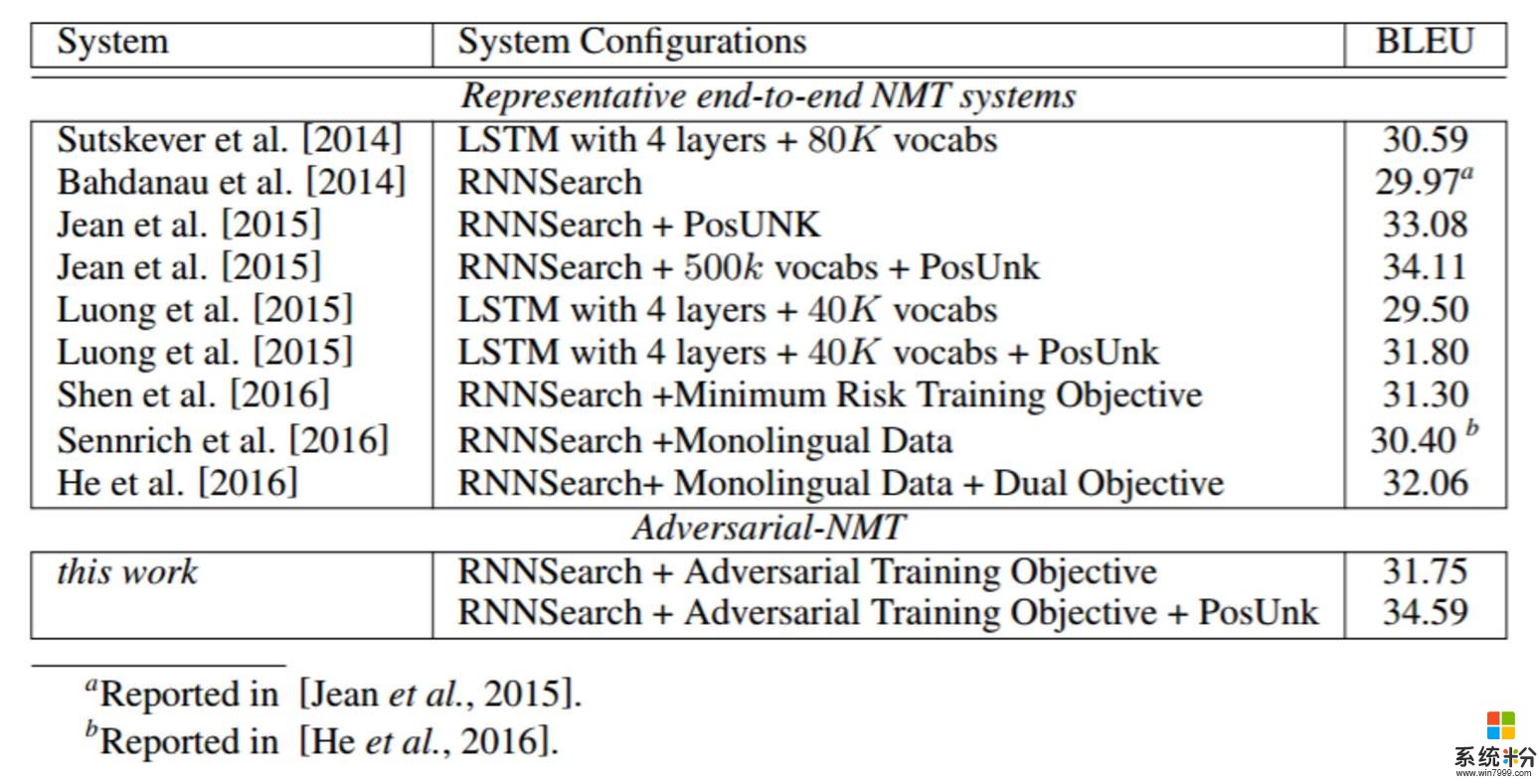
表 1:在英法翻译上不同 NMT 系统的表现。其默认设置是一个单层的 GRU + 30k 词汇+ MLE 训练目标,使用的是 no monolingual data 进行训练,即 Bahdanau et al. [2014] 提出的 RNNSearch 模型

表 2:在德英翻译上不同 NMT 系统的表现。其默认设置是一个单层的 GRU 编码器-解码器模型+ MLE 训练目标,即 Bahdanau et al. [2014] 提出的 RNNSearch 模型
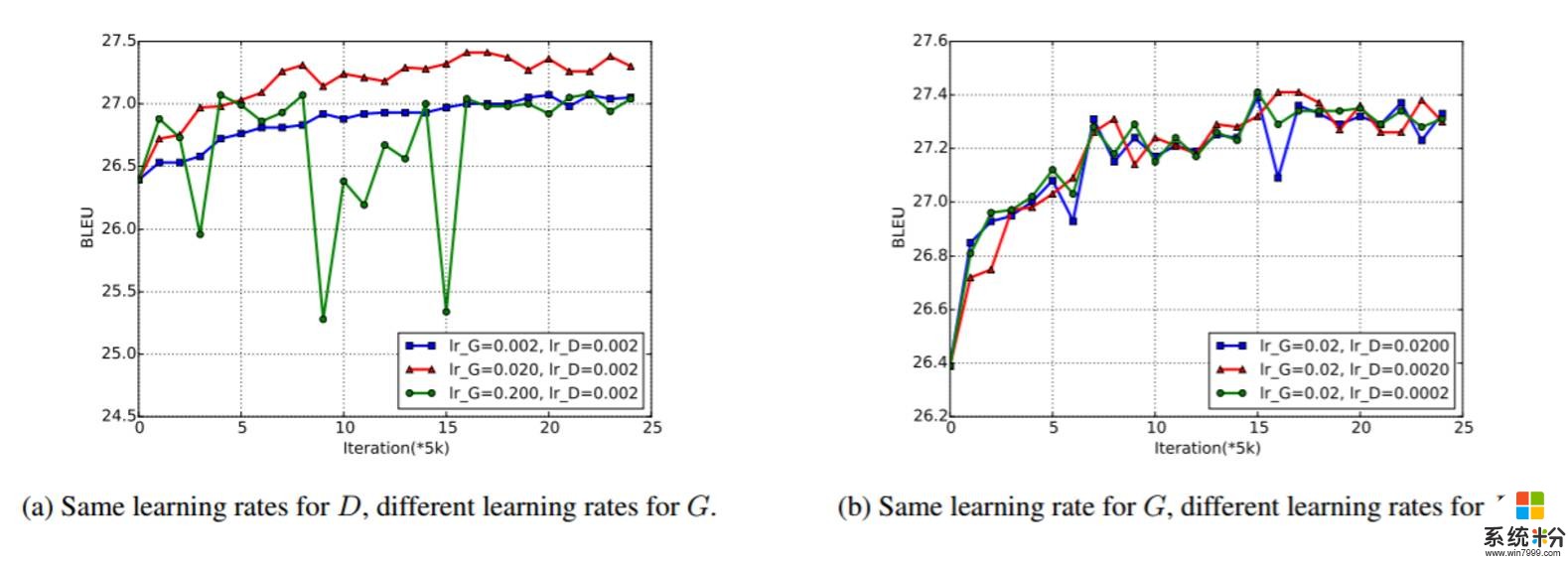
图 3:在英法 Adversarial-NMT 训练过程中的 Dev set BLEU。图 3(a) 中 D 使用了一样的学习率,G 使用了不同的学习率。图 3(b) 中 G 使用了一样的学习率,而 D 则使用了不同的学习率。










