学界 | 机器理解中的迁移学习, 斯坦福联合微软提出SynNet网络
机器之心编译
参与:李亚洲、Smith
近日,斯坦福大学、微软联合发表了一篇论文,提出了一种在机器理解(MC)中使用 2-阶段合成网络(SynNet) 进行迁移学习的技术。论文作者之一、前微软人工智能首席科学家邓力已经离职,加入对冲基金巨头 Citadel。

我们开发了一种在机器理解(MC)中使用一个全新的 2-阶段合成网络(SynNet) 进行迁移学习的技术。在某个领域中给定一个高性能 MC,我们的技术旨在回答有关另一领域文档的问题,其中我们使用的是无标记数据问答对。不使用提供的注释的情况下,在 SQuAN 数据集预训练的模型上使用我们提出的 SynNet,能够在 NewsQA 数据集挑战赛上取得 46.6% 的 F1 测量结果,接近领域内(in-domain) 模型的表现(F1 结果为 50.0%),超过域外(out-domain) 基线 7.6%。
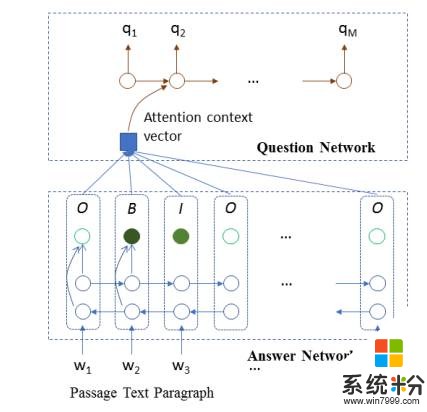
图 1:2-阶段 SynNet 的图释。给定段落的情况下,训练 SynNet 的目的是对问题与答案进行合成。模型的第一阶段是一个答案合成模块,使用一个双向 LSTM 在输入段落上预测 IOB 标签,标记出可能是答案的关键语义概念。第二个阶段是一个问题合成模块,使用一个单向 LSTM 来生成问题,同时顾及段落中词汇与 IOB id 的嵌入。尽管段落中的多个跨度(span) 可以被认为是潜在答案,但我们只选择了一个 span 来生成问题。

表 1:随机采样的段落和对应的来自 NewsAQ 训练集的合成问题与人类问题的对比。

表 2:主要结果。使用我们的 SynNet 精调的 BIDAF 模型在 NewsQA 测试集上的精度匹配(EM)和 span F1 结果。

表 3:NewsQA 到 SQuAD。在 SQuAD 上开发的一系列 NewsQA BIDAF 模型与使用由 2-阶段 SynNet 生成的数据精调的模型的 EM 和 span F1 结果对比。

表 4:Ablations Studies。使用一个 2-阶段 SynNet 精调的 BIDAF 模型在 NewsQA 测试集上的精确匹配和跨距 F1 结果。
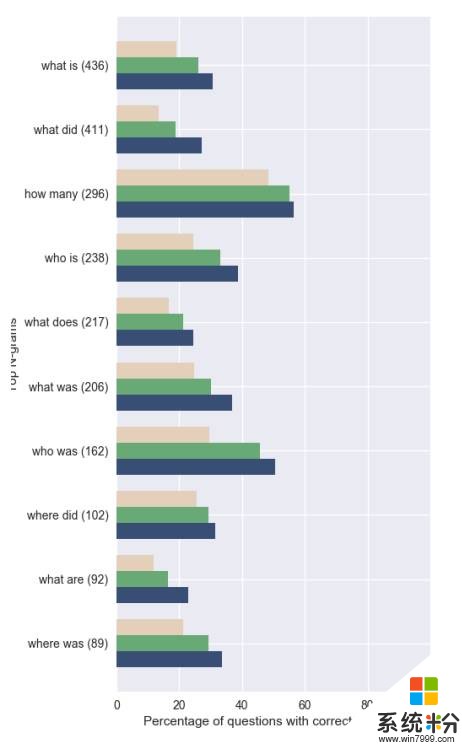
图 2:在 SQuAD(黄色)上训练的 BIDAF 模型基准的 NewsQA 准确率对比使用我们方法精调的模型对比在 NewsQA 上从头开始训练的一个模型(深蓝)。










