微软提出新型通用神经机器翻译方法,挑战低资源语言翻译问题
近日微软发布博客,提出一种半监督通用神经机器翻译方法,解决低资源语言机器翻译的问题,帮助解决方言和口语机器翻译难题。该研究相关论文已被 NAACL 2018 接收。
机器翻译已经成为促进全球交流的重要组成部分。数百万人使用在线翻译系统和移动应用进行跨越语言障碍的交流。在近几年深度学习的浪潮中,机器翻译取得了快速进步。
微软研究院近期实现了机器翻译的历史性里程碑——新闻文章中英翻译达到人类水平。这一当前最优方法是一个神经机器翻译(NMT)系统,该系统使用了数千万新闻领域的平行句子作为训练数据。如此巨量的训练数据仅仅在少数语言对可以获得,也仅限于少数特定领域,例如新闻领域或官方记录。
事实上,尽管全球共有大约七千种口语,但是绝大多数语言都不具备训练可用机器翻译系统所需的大量资源。此外,即使具有大量平行数据的语言,也并没有口语对话或者社交媒体文本等非正式风格的数据,这通常和正式的书面风格大有不同。对任何语言对而言,获取数百万平行句子的数据都是相当困难的。而为任何语言寻找单语数据都会容易一些。
微软使用半监督通用神经机器翻译的方法解决了平行数据不足的挑战,对于极低资源的语言而言,这种方法仅仅需要数千个平行语句就可以实现高质量的机器翻译系统。这项令人激动的研究(https://www.microsoft.com/en-us/research/publication/universal-neural-machine-translation-extremely-low-resource-languages/)将在 NAACL 2018 上展示。
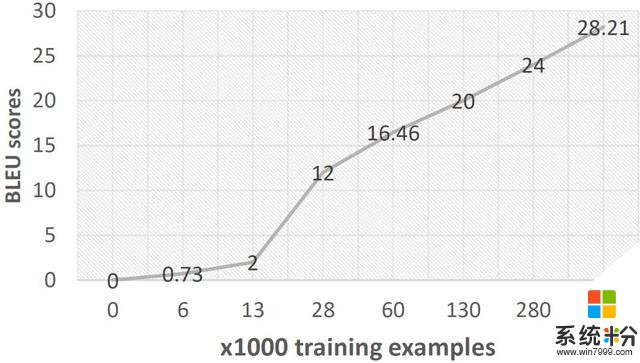
图 1:训练数据较少的情况下不可能获得较高的 BLEU 得分。
如图 1 所示,使用有限数量的训练样本不可能达到高质量的翻译准确率。所以微软提出的方法着重于只有有限数量训练样本的情景,例如,只有 6000 个训练样本。

图 2: 神经机器翻译编码器-解码器框架中编码器方面的改进。
微软提出的系统使用迁移学习方法将不同源语言中词汇级别和句子级别的表征共享到一个目标语言中。该设置假设多种源语言包括高资源语言和低资源语言。微软的主要目标是能够共享所学的模型,以便帮助低资源语言。该系统架构对神经机器翻译(NMT)的编码器-解码器框架新增了两个修改,以实现半监督通用神经机器翻译。主要修改了编码器部分,如图 2 所示。
1. 为了支持多语词级别的共享,词汇部分通过一个通用词汇表征(ULR)来共享。
2. 专家模型表征所有源语言句子级别的共享,与其他语言共享一个源编码器。
这两种修改使低资源语言能够利用与较高资源语言相关联的词级和句子级表征。
ULR 利用预投影步骤,将在单语语料库上训练的所有词嵌入投影到统一的通用空间中。预投影可以使用种子词典、小型并行数据或无监督方法来实现。如图 3 所示,研究者最终得到了所有语言的统一表征:在这个例子中,所有语言都投影到英语表征中。值得注意的是,统一嵌入空间是使用 word2vec 学习到的单语嵌入投影而得的,这对于翻译任务而言并不是最佳的。
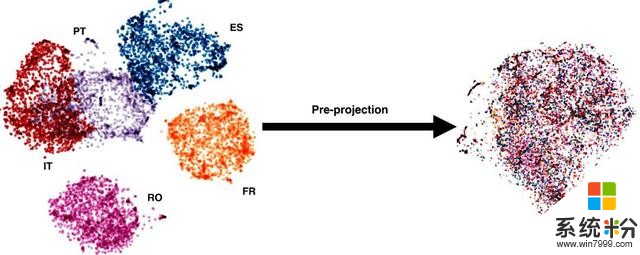
图 3:ULR 使得为任何语言中的任意单词实现统一嵌入成为可能。
使用 ULR 可以为任何语言中的任意词生成统一的嵌入。神经机器翻译系统使用有限的多语言数据和可选的来自低资源语言的少量数据进行训练。给定在训练数据中从未观察到的任何语言中的任意单词,目标是对该单词有合理的表征,以便能够翻译这个单词。微软提出了一种新型多语言嵌入表征方法,来自任何语言的每个词都可被表示为通用空间词嵌入的概率混合。这样,来自不同语言的语义相似的词自然就具有相似的表征。该方法基于嵌入空间上的 Key-Query-Value 表征,详见图 4。
为表述简便,假设这么一个场景,一个使用四种平行语言训练的多语言系统:西班牙语(ES)、法语(FR)、意大利语(IT)和葡萄牙语(PT)。我们希望使用这个系统来翻译罗马尼亚语(RO),它是一种平行数据不足的低资源语言。
研究者对任意给定的罗马尼亚单词(例如「pisicile」)执行查询(query),以从通用嵌入空间中找到类似的单词,如图 3 所示。query 是单语嵌入中的词嵌入;key 是通用嵌入空间中的单词。value 是在通用空间中表征给定单词的加权嵌入。ULR 可以处理在平行训练数据中从未观察到的任意单词的无限多语言词汇表。
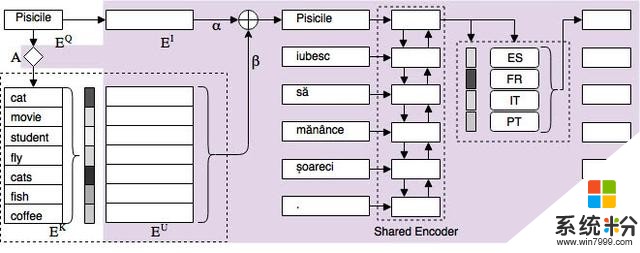
图 4:使用 MoLE 和 ULR 的系统架构。
一个关键问题是,词嵌入是在单语数据上训练的,不是针对翻译任务所进行的优化。微软研究者向查询匹配机制添加了一个可训练的变换矩阵(见图 4 左上角的 A),其主要目的是针对翻译任务调整相似度得分。如图 5 所示,从单语嵌入的角度来看,「autumn」、「fall」、「spring」、「toamnă」(罗马尼亚语中的秋天)等词非常相似,而对于翻译任务来说,「spring」应该不那么相似。变换矩阵实现了这个目标。
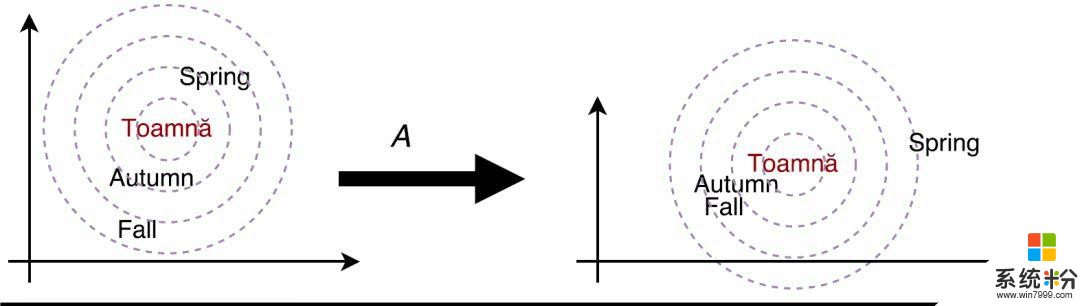
图 5: 针对翻译任务调整相似度得分。
当我们朝着通用嵌入表征的目标前进时,编码器具备语言敏感模块是至关重要的,这将有助于对不同的语言结构进行建模。微软的解决方案是用语言专家混合(MoLE)模块给句子级通用编码器进行建模。图 4 在编码器的最后一层之后增加了 MoLE 模块。用门控网络和一组专家网络来调整每个专家的权重。换句话说,训练该模型来学习在翻译低资源语言时从每种语言需要的信息量。MoLE 模块的输出将是这些专家的加权和。
NMT 模型学会了在不同的情况下使用不同的语言。在图 6 中,正方形的颜色越深,任意给定词条的罗马尼亚语和其他语言之间的关联性就越大。很明显,MoLE 在处理低资源语言单词时,在语言专家之间进行了有效的转换。在图的上半部分,该系统更多地利用了希腊语和捷克语的知识,从德语中利用的知识较少,几乎没有利用芬兰语知识。而在图的下半部分,意大利语是相关性更强的语言,被使用得更多。有趣的是,该系统学习到,意大利语和捷克语在翻译罗马尼亚语时都是有用的,前者和罗马尼亚语同属于罗曼语族,而后者不属于罗曼语族,但由于地理上的接近,它和罗马尼亚语有显著的重叠,因而在翻译罗马尼亚语时利用度很高。
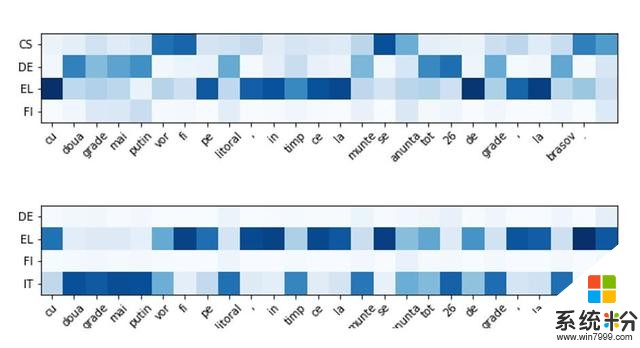
图 6:MoLE。
在实验中,研究者在三个场景中尝试了所提出的模型。第一种是多种语言翻译场景,该场景中模型仅使用每个语言对的 6000 个平行句子就学会了罗马尼亚语—英语和拉脱维亚语—英语的翻译。
在第二个场景中,研究者首先在高资源语言上训练模型,然后在低资源语言上微调模型。在实验中,该模型成功地利用 6000 个罗马尼亚语-英语平行句子对使用零罗马尼亚语-英语平行数据训练的多语言系统进行了微调。该系统的 BLEU 值接近 20,只需两分钟就可以在零资源翻译设置中将预训练模型微调为适合新语言的模型。
在第三种情况下,研究者调整了一个经过标准阿拉伯语到英语翻译训练的系统,使之在完全不使用口语方言平行数据的情况下,就能适用于阿拉伯语口语方言(黎凡特语)。
这些方法帮助微软扩展 Microsoft Translator 的功能,以支持口语方言和低资源语言(如印度语)。
相关论文将会在 2018 年于新奥尔良举办的 NAACL HLT 2018 上展示。
论文:Universal Neural Machine Translation for Extremely Low Resource Languages

摘要:本论文提出了一种新型通用机器翻译方法,该方法主要针对平行数据有限的语言。该方法利用迁移学习在不同源语言到目标语言的翻译中共享词级和句子级表征。词级表征通过通用词汇表征(ULR)来支持多语言词级共享。通过专家模型表征所有源语言句子级别的共享,与其他语言共享一个源编码器。这使得低资源句子可以利用更高资源语言的词级和句子级表征。
该方法使用只有 6000 句子的小型平行语料库在罗马尼亚语-英语 WMT2016 中取得了 23 的 BLEU 得分,而使用多语言训练和回译的强大基线系统的 BLEU 值是 18。此外,我们证明了该方法在同样的数据集上、zero-shot 设置中,通过调整预训练多语言系统达到了接近 20 的 BLEU 值。









