首发: 人脸识别世界杯榜单出炉, 微软百万名人识别竞赛冠军分享
1 新智元报道报道:闻菲
[新智元导读]业界公认人脸识别“世界杯”的微软百万名人识别竞赛 MS-Celeb-1M 结果出炉:百万名人识别子命题,Panasonic-新加坡国立大学合作夺得第一,CIGIT和中科院合作队伍与美国东北大学位列第二第三。MS-Celeb-1M 数据集有效填补了工业界跟学术界的空白,通过有针对的评估指标设计,竞赛实现了人脸“端到端”识别,有助于参赛模型投入现实应用。最后,竞赛识别单一训练样本的名人子命题的冠军团队成员分享了他们的思路方法和参赛经验。
2016 年 6 月,微软向公众发布了大规模现实世界面部图像数据集 MS-Celeb-1M,含有 10 万个名人的约 1000 万(10M)张脸部图片,鼓励研究人员开发先进的人脸识别技术。
同时宣布的还有 MS-Celeb-1M 百万人脸识别挑战赛。参赛者需要根据(但不限于)挑战赛提供的数据集作为训练数据,开发图像识别系统,从脸部图像中识别 100 万个名人。
今天,竞赛结果公布,其中:
百万名人识别子命题,
无限制类(可以自由使用外部数据),Panasonic-NUS(新加坡国立大学)获得第一名,中科院重庆绿色智能技术研究院(CIGIT)与中科院合作团队第二,美国东北大学第三;
有限制类(只使用竞赛提供数据),第一名是 Beijing Orion Star Technology Co., Ltd.
识别单一训练样本的名人子命题,
无限制类(可以自由使用外部数据),第一名是 NUS-Panasonic
有限制类(只使用竞赛提供数据),第一名是美国东北大学
优胜团队在技术上都采用了基于深度学习的方法,以及网络大数据。从中可以看出,网络大数据是发展趋势,多模型融合是现在各个比赛得奖的利器。
微软百万名人识别竞赛 MS-Celeb-1M:填补学术界与工业界的空白
人脸识别竞赛有很多,微软的百万名人识别挑战赛与已有的竞赛有什么不同?
据微软技术与研究院(Microsoft Technology and Research)首席研究员/研究经理张磊博士介绍:首先,MS-Celeb-1M 的目标是识别百万人脸,是计算机视觉内最大规模的分类问题,并且其中一个人物对应一个 entity,绑定了知识库,并且知识库中提供了每个人的职业,性别等等丰富的信息,从而解决了人物重名的问题,可以从识别达到认知。“最开始我们是面向学术界做的这个数据集,”张磊告诉新智元:“但后来很多工业界的同行也表示我们的数据集对他们的研究工作很有帮助。”
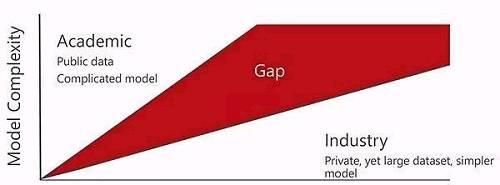
深度学习算法的进步使视觉识别在过去几年中取得了很大的进步。但是,学术上的创新和实际投入生活使用的智能服务间仍然存在巨大差距,主要因为:
(1)学术研究缺乏现实世界的大规模数据,从而阻碍了有效训练和评估算法;
(2)缺乏公开透明的平台进行公正、高效的评估,使识别结果可复现,容易获得。
目前,几个主要的人脸识别数据集,公开获取的(下图绿色)有:
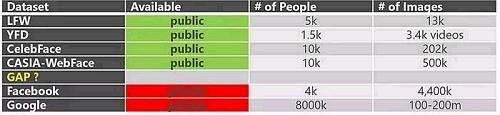
LFW 是美国马萨诸塞大学的一个数据集,规模在万这个级别(13k);
YFD 是耶鲁人脸数据集,由耶鲁大学计算视觉与控制中心创建,有不同的光照、表情和姿态的变化,但数量较少;
CelebFace 含有 20 多万张图片;
CASIA WebFace 是中科院自动化研究所的几种数据集,里面包含掌纹、手写体、人体动作等 6 种数据集;需要按照说明申请,免费使用。
接下来,Facebook 和谷歌的数据集规模虽大,但都无法公开获取。
这些无不体现了存在于学术界和产业界之间的一道明显的鸿沟。

竞赛指标设计:实现端到端识别,有助于现实应用
在竞赛指标设置方面,微软的 MS-Celeb-1M 也针对现有竞赛做了填补。
目前,数据能够公开获取的比较著名的人脸识别竞赛有 LFW 和 MegaFace。LFW 的规模在万这个级别,由于训练数据不共享等原因,近年来已经呈现出容易过拟合的趋势,而且微软的研究人员发现,LFW 的最佳算法往往难以完全复现。此外,LFW 竞赛是比对两张图像的相似度,距离实际应用还有一定距离。
MegaFace 是美国华盛顿大学发布的数据集,内容是几十位互联网明星照片加上普通人的一百万左右的图片的干扰数据。但是,MegaFace 的目标设定有所不同,相比“识别”,更倾向于“在大噪声情况下的人脸验证”(face verification)。具体来说,MegaFace 竞赛的目标则是在上百万人中识别出特定的几十人。几十个人对人脸识别性能评估作用很难非常全面,与实际应用尚有一些距离。此外,MegaFace 的测试数据没有经过人为标注,含有噪声。测试数据的噪声在衡量高性能的模型时干扰很严重。

“我们这个任务是端到端的任务,具体的说,任务是从图像到知识库中的名人识别码。这样的话,很自然而然引入了很多有价值的研究问题,比如如何有效从网络有效获取数据(我们允许自己增加训练数据),如何利用好有噪音的标注训练数据(规模巨大,超过人工标注的成本核算),如何处理海量数据(目标一百万人,千万级别的图),当有些人的数据特别少,数据不均衡的时候怎么办等等,这些都是 CV 里面有意思的问题。”郭彦东说。
参赛队伍的目标是识别出混百万人中的 1000 个人,但具体是哪 1000 人参赛者并不知道。因此,为了实现尽可能高的召回率和准确度,参赛模型需要覆盖尽可能多的人,乃至全部百万规模。这就对模型提出了很高的要求。此外,微软的研究团队非常仔细地人工标注了测试集合,在测试集合上保证了非常高的准确度,这样对衡量高性能模型以及模型在几乎 100% 的准确率下的表现(recall@high precision)就非常有效。

在这里,参赛队伍需要从 2 万 1000 人中识别 1000 人。但是,这 1000 人都每个人都只有 1 张用于训练的图片。在很多情况下,比如公安人脸识别,犯罪嫌疑人只有 1 张模糊的或有遮盖的图片,要将其在茫茫人海中找出来,就属于小样本学习。
这在一定程度上倡导了当今人工智能的另一个垂直方向:从有限样本中学习视觉概念。
冠军团队技术分享:Low-shot Learning 环节
竞赛结果公布后,新智元采访了 Low-shot Learning 竞赛冠军新加坡国立大学与新加坡松下研究院合作团队,成员赵健作为代表分享了他们的思路方法和参赛经验。
冠军队伍:NUS-Panasonic,成员:赵健(NUS),程禹(Panasonic),王哲灿(NUS),徐炎(Panasonic),Karlekar Jayashree(Panasonic),Shen Shengmei(Panasonic),冯佳时(NUS)。
新智元:为什么要参加微软 MS-Celeb-1M 百万名人识别竞赛?
NUS-Panasonic:微软百万名人识别竞赛是业界公认的人脸识别年度“世界杯”。本次竞赛由微软研究院主办,借助计算机视觉领域顶级会议 ICCV 2017的平台,级别之高、难度之大备受瞩目。全世界人脸识别的顶尖团队都希望能够在这次比赛中一展身手、显露头角。本届竞赛既包括了与上届类似的大规模人脸识别竞赛(Hard Set 及Random Set),同时也提出一个全新的、更具挑战性的 Low-Shot Learning 竞赛。主办方希望参赛队伍既能够做到大规模人脸的精准识别,同时也能够有效解决稀缺人脸训练样本的精准识别难题。
NUS LV 组由颜水成教授创建、由冯佳时教授领军,是目前各大学术机构在深度学习与计算机视觉领域的顶级团队之一。其人脸识别团队一直是LV组中不可或缺的顶梁柱,屡创佳绩——在 LFW 人脸识别数据集首次达到 99.7% 的识别精度、在 NIST 2017 IJB-A 人脸匹配与识别两项竞赛中与新加坡松下研究院合作一起夺得冠军。我们选择参加本届(2017)微软百万名人识别竞赛希望能够在人脸识别的最高平台上证明自己,并助推大规模人脸识别技术的长足进步与发展。
新智元:从技术的角度讲,参赛得到的最大启发是什么?
NUS-Panasonic:本次竞赛得到的最大启发是精准高效的人脸识别系统设计通常需要将一个复杂问题进行模块化,从数据收集、清理、预处理,到模型设计、训练、测试,再到不同模型的融合、度量学习、性能评估,每个模块都不断去尝试一些新的想法和不同的策略,将每个模块的效果调试到最优后,再进行系统级接合。
新智元:能介绍一下你们的思路、方法和获胜的原因吗?
NUS-Panasonic:Low-Shot Learning 重点考察参赛队伍能否有效解决稀缺人脸训练样本的精准识别难题。Low-Shot Learning 比赛分别提供两个数据集——Base Set 和 Novel Set。其中,Base Set共包含 20k 个名人,每个名人提供 50-100 张样本数据;Novel Set 共包含 1k 个名人,每个名人仅提供 1 张样本数据。在测试时,主办方提供的测试集中会混合 Base Set 与 Novel Set 的名人数据,并重点考察算法在 Novel Set 稀缺人脸训练样本的表现。
为了解决这一难题,我们基于大规模人脸识别竞赛提供的 100k 名人的训练数据,移除掉其中包含的 Novel Set 中 1k 个名人的数据来构建一个“增强版”数据库,训练几种不同结构的网络模型,使得网络学到的特征具有足够的区分度、鲁棒性以及泛化性能,不同的网络模型学到的特征也具有互补效应。我们采用特征检索的方法对每个模型进行测试,在测试时通过交叉验证的方法确定了一些有效的策略。
相比于其他参赛队伍的方法以及传统 Low-Shot Learning 的解决办法而言,我们的主要改进在于符合比赛规定的额外数据的使用与构建、多模型的度量学习、启发式投票融合以及测试阶段的数据增强。
比赛取得的好成绩也依赖于新加坡松下研究院充足的硬件设备,比如大规模的 GPU 集群和最新的 DGX。新加坡松下研究院一支数据标注团队也在这次比赛中发挥了很大作用。
新智元:比赛中遇到的最大困难是什么?如何解决的呢?
NUS-Panasonic:百万名人识别的难点如何高效利用已有数据高效训练效果最优的模型。为了解决稀缺人脸训练样本的难题,我们基于大规模人脸识别竞赛提供的 100k 名人的训练数据,移除掉其中包含的 Novel Set 中 1k 个名人的数据,构建一个“增强版”数据库,训练几种不同结构的网络模型。训练过程中,网络最后一个全连接层(FC)的神经元数量与分类类别数量相等,大量级的训练参数往往导致网络很难直接训练,损失函数波动震荡不降。我们在这里进行了一些调整,将整个训练过程分为两个阶段,首先训练网络来区分 1/10 样本类别,在网络趋于收敛后,将最后一个 FC 层替换掉,并进行第二阶段的训练和调优,从而解决大样本类别的网络高效训练难题。
新智元:你们提出的算法有什么实际应用?
NUS-Panasonic:我们所提出的算法能够有效解决稀缺人脸训练样本的精准识别难题,这对于安防系统、智能家居系统、无人驾驶以及人机交互等领域具有很高的应用价值和商业前景。我十分看好未来算法的落地,如可以结合人脸识别算法研究、网络压缩技术和FPGA相关技术进行系统级设计,为人们的生产生活提供更多便利。
虽然目前人脸识别的准确率已经很高,但大多主流技术和算法需要以预定姿态或条件为前提,如正脸或近似正脸,图像清晰无遮挡,表情、背景单一等。未来的真正意义上的智能人脸识别将可以很好地解决上述问题,并在大规模、非限制条件以及稀缺训练样本的人脸识别问题中不断取得新的突破。
新智元:祝贺你们取得好成绩,最后分享一下获胜感受吧。
NUS-Panasonic:通过 NUS LV 组与 Panasonic 的竭诚合作,历经三个月的共同努力与奋斗,我们终于成功拿下微软名人人脸识别三项竞赛(Hard Set, Random Set, Low-Shot Learning)的冠军。很庆幸能够成为冠军团队的一员,能够取得这样的成绩,离不开 NUS 与 Panasonic 两个单位的竭诚合作,离不开团队每名成员的齐心协力、共同拼搏。感谢我的导师冯佳时教授、颜水成教授的培养、指导和信任,感谢中科院自动化所兴军亮老师的帮助与指导,感谢国防科技大学和中国留学基金委的资助,我会继续努力,希望能够在人脸识别领域再创佳绩,助推相关技术发展和进步。









