讲堂|CMU计算机学院院长:未来24个月,机器学习领域将可能有哪些重大突破

近日,卡内基梅隆大学(CMU)计算机学院院长Andrew W. Moore和副院长Philip L. Lehman来到微软亚洲研究院,与研究员们分享了过去两年中人工智能领域的一些技术突破,并从业界和学界两个角度,探讨了他们对于人工智能接下来发展方向的看法。
今天,我们就在这里与大家分享此次演讲~以下为Andrew W. Moore演讲的精简版文字整理。
2005到2015年间,我们见证了数据科学在学术界和商业界的发展,学会了如何正确地使用分布式计算、GPU,如何很快的建立抽象模型等等。仿佛AI完全转化成了机器学习,每个人都在处理数据、基于数据为复杂的世界建模……
大约2014年,许多人开始意识到这些工作还远远不够,它们仅能实现改变世界蓝图的一半,而另一半则是被我们视为数据科学最顶层的决策系统。上世纪90年代,我们对所建立的系统都十分乐观。但渐渐地,我们发现,这些系统在应用到实际生活中时并没有效果,比如在优化城市交通数据时,一个完美的优化算法并没有帮助,因为那时我们没有任何关于城市交通的数据。所以现在,我们严肃认真地考虑重新回到基于数据科学的大规模优化和决策上。
而在大学里,我们会思考更多的可能性。有些教授认为自主性(autonomy)是最重要的,是AI的真正目标,对此观点我们十分尊重。它在很多方面,比如深空探索或需要快速决策的情况下,都将有重要的应用。当然,自主性不是AI最终唯一的目标。它还包括其他方面,例如增强人类(augmented humans)等等,在我看来这和微软的核心任务,如何更好地帮助人类工作、生活,有着很大的重合度。我们需要帮助人类更好地工作、生活,同时也需要自主性。
在数据科学方面,我们需要关注三个部分。首先是人工智能的基础建设,包括大型优化策略,它需要我们擅长大规模线性规划问题和随机梯度下降等问题。其次,是自主性(autonomy),最后是增强人类(augmented humans)。
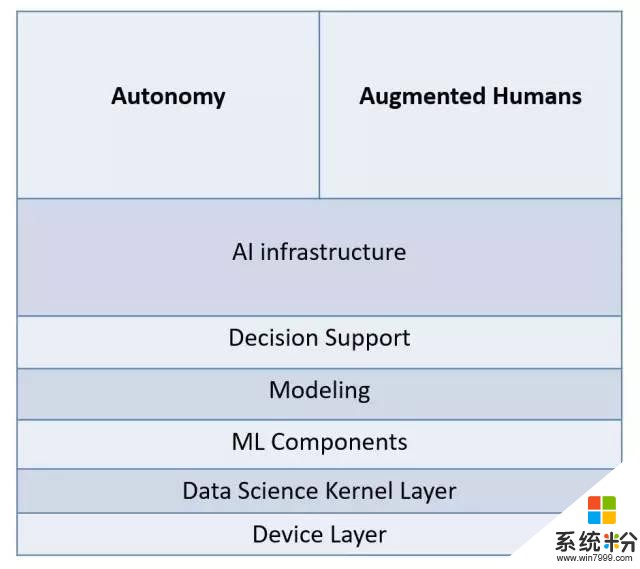
接下来,我将会谈到四个主题:
1
大型网络公司的视角
首先,谈谈我在工业界和学术界所见的不同之处。在工业界,我们会非常关注机器学习模型的高效性。虽然一个高效的机器学习模型很好,但仍需要做到每秒钟完成数百万的预测量。所以,即使我们的算法能够高效的完成训练,然而在实际应用时,花费依旧很大。尤其是当你想在本地设备上使用它而不是通过云端时,这仍然是个问题。
2
过去24个月,机器学习领域的最大变化
对于许多大型搜索引擎公司来说,机器学习超过百分之五十的工作在于测试和验证。因此,我对未来稳定、可靠且经过长期验证的机器学习模型充满期待,以及如何确保深度学习算法不会在运行几个月后走向奇怪的方向。对于机器学习算法,会有工具帮助快速诊断目前正在发生什么以及如何解决。例如,你有一些系统问题导致了随机梯度下降的更新,并带来了额外的延迟等,而对于这些问题你都可以很快地理解,并改进。但在我的学术生涯中,还没有看到过类似的技术,所以我希望接下来的几年,我们的机器学习模型可以在稳定性、安全性和长时间的可靠性上有更大的突破。
在这里我想展示一下我们一位同事最近的研究成果。他研究的是针对如飞机和汽车动力系统的操纵系统前期和后期条件类型分析,这曾经被认为是最重要的证明软件正确性的方法之一。我的这位同事采用老式方法将系统与控制系统中的统计和数值方法结合,来证明如果有一个机器人控制算法,即使是一个非线性的算法,它也会按照所说的来做。现在,美国许多的自动驾驶系统研究在提高系统安全的问题上停滞不前,因此,这项工作将非常具有实用意义。
在军事方面,使用自动驾驶技术可以避免很多不必要的牺牲,仅仅使用一辆车就可以带动其余的自动驾驶车辆。虽然听起来很简单,但这项应用实现的最大阻碍还是证明我们所使用的机器学习系统和这些自主驾驶场景的可靠性。所以,当我们在新的研究领域找寻策略时,自适应算法的安全性验证相比于增加现有算法速度的准确性,可能会更重要。
此外,我还想和大家分享一些有趣的研究。如今,人类生物识别也已成为一个科学研究方向。与从演讲录音中提取演讲内容相反,我的一位同事,Rita尝试了从中提取其他的声音信号,进而得到关于演讲者的信息。我们可以从低分辨率的数据中准确的预测出人的气管形状和大小,同时,这些信息与人的身高、体重等其他身体特征也密切相关。简而言之,她可以在一场演讲录音中了解演讲者的身高、体重、成长地等等。这也是机器学习新应用的一个例子。
还有一个例子,是一台特殊的相机,它可以根据红外光谱在20米内聚焦。它的特别之处在于移动快速、准确,可以在三十分之一秒内停在目标地点。同时,基于它的高分辨率,我们可以准确地完成生物识别,识别每个人。这一技术,将来或许可以应用在商店购物,我们不再需要收银员,当你从货架上去拿商品时,付款就已经通过你的虹膜支付完成了。其实,这类应用从技术上是可行的,但它究竟是好事还是坏事,我们还不得而知。
此外,一个研究的重要领域是逆向强化学习(Inverse Reinforcement learning)。众所周知,在强化学习中,我们会定义一个奖励函数(reward function),然后尝试寻找最大化奖励函数长期结果的策略。而在逆向强化学习中,我们则是尝试根据其他个体选择的行为来推断它们的奖励函数。
比如,根据车流和行人已有的移动轨迹我们可以预测每个人、每辆车的移动可能。所以,当我们把目光投向计算机视觉的未来时,实际上我们已经将重心从观测即时信息,转向了预测将来15秒的状态信息。这对于自动驾驶和人群的安全都将有重大意义。
我们关注的另一个领域是,自主平台在机器人相关方面的成熟应用。预测空间的3D模型在机器人技术进步的基础上,也已经非常成熟了,而这也是将来机器人发展的基础。如果你熟悉这一成熟技术背后的计算模型,从获取数据到传送到云端,它使用了大量的EM 算法以加速前后的推理。而我的一位同事的研究突破在于使算法有了一个非常准确的增量,不再需要上传数据到云端。通过简洁的代数技巧(algebra trick),我们可以模拟整个EM算法的运行。更有意义的是,低功耗的远程设备就可以完成。

Andrew W. Moore 卡内基梅隆大学计算机学院院长
3
接下来的24个月,机器学习领域将可能有哪些重大突破
情绪压力测试是一个快速成长的领域,微软是这方面的专家。在匹兹堡,我们也对这一领域充满兴趣。这里有一个重要的应用,我们可以通过观察人们说话时的面部特征,评估他们对于某件事情情绪波动的程度。举个例子,当用于医疗时,我们可以通过观察病人的反应,判断治疗是否有效。一年前,我们曾有实验表明,在医生可以判断病人生理特征表现的六周前,我们就成功判断了治疗的效果,通过对面部肌肉的检测我们可以获得许多情绪信息。因此,未来我们或许可以更快捷、有效地帮助患有精神疾病的病人。
同时,对于大家关注的用户和电脑间的对话系统,我们的两位同事发现,对于复杂对话,病人谈论到一些疾病症状,或者学习上有疑问想获得反馈的孩子们,机器能够对对话产生更快、更成功的结果,因为机器可以根据用户情绪调整反馈结果。
所以,通过这些客观证据我们可以看出,如果想建立一个优秀的对话系统,则需要考虑到实际情绪的相互作用。现在在CMU,我们有计算机视觉实验室,有对于语言技术的研究,我相信在不久的将来,情绪认知也会是我们的研究重心。
接下来,我想谈谈知识图谱。在美国,许多企业和大学包括微软,以及一些政府机构经过一系列的会议讨论一致认为,我们需要分享构建的大型知识图谱。因为对于对像阿里巴巴、亚马逊这样的零售公司来说,为各种产品构建单独的知识图谱是非常困难的,同样的,对于做地图的公司来说,为城市地标构建单独的知识图谱也非常困难。
患者想要讨论医疗健康问题、学生想讨论关于学习的问题等等,在未来,商业领域之外的对话系统构建方面,我们还有很多工作可以做。医疗、教育、政府等,如果每个公司都单独构建知识图谱,那么这将消耗大量资金,同时,不同的语言也会带来很多不必要的资源浪费。因此,我们强烈认为,合作将是未来工作的基础,我们将一起构造开放的知识网络。
首先,我们可以将各种实体作为知识图谱的节点,这些实体可以是埃菲尔铁塔、CMU音乐学院、甚至可以是一个投影仪等等。对于这些数以万亿的实体,目前我们有很多类型的实体工具,它们各有利弊。成本高、针对性强的图谱难以大范围应用,通用的图谱又过于耗时。例如GIS系统虽然已经很完善但仍难以应用到其他领域。所以,将来我们在构建和存储实体时,需要在数据库中为他们和其他实体建立对话联系。
然后,我们要匹配引擎(matching engine)。这与搜索引擎非常相似,同样需要快速的深度学习能力。匹配引擎从演讲、文本、可视范围中选取内容,以构建知识图谱中实体的概率分布,这对于构建一个准确的匹配非常重要。所以,对基于知识图谱实现具体应用的人们来说,他们需要处理概率集合以形成总体结论。
大家都知道,现在大部分的知识图谱是基于三元组的,三元组是一种原始的表达事实的方式。除了科学实验,它还出现在一些与科学相关的领域,如经济、金融等。专家们发现,因为缺乏统一的数据模式,即使有很好的数据集,它们还是很难在数据间建立连接。这也是我们希望通过构建全局知识图谱来帮助我们的地方。
有趣的是,在构建全局知识图谱中,我们还有很多机器学习的问题需要解决,比如合并指向同一实体的不同对象或者区分相像但不同的对象等。虽然我们有很不错的概率模型,但是在公共领域之外,它们无法像成熟的算法一样处理数万亿的内容(mentions)以建造理想的对话系统。发现问题,解决问题,这是一件非常令人兴奋的事情。
4
一些近期机器学习不那么显著的应用
我还想谈谈我们另一位同事的工作,这可能是一个大多数人都没有想过的领域。一个大型代码库,不论开源还是公司内部的代码库,都是非常丰富的数据资源,你可以获得大约千万到数十亿行的代码量用以统计分析。你会有一个关于代码库的完整的历史记录表,换句话说,我们实际上有一个关于人们何时做决定,出于什么原因作出改变的日志。现在大多数的代码库中,这些记录里有30%都是关于错误修改的,而不是重构或改进的。这是一个很好的机器学习任务,如果你拥有这些训练数据,那是否可以再次预测出代码库中的错误出现在哪里?哪部分数据是最有可能被修改的?
目前,这项研究进行的十分顺利,预测效果也比较理想。我们可以拓展一下应用场景,你可以将它用于错误预测。从修改日志中,可以预测自己的代码有哪些是可能需要改变的。更有意思的是,我们可以将这一在自然语言中有重大突破的技术应用于自我重写的代码。
最后我想回到低功耗设备的自主性上,它仍是一个种重要的主题。它与不依靠云的单一低功耗平台的视觉处理有关。考虑到计算代价和延迟等因素,我们通常不将云与计算机视觉等研究结合。现在我展示的是一个无人机上的单个摄像机,它能在飞行时及时推断树木的位置,并计算飞行路线。这是一个很好的关于实时系统的例子,系统工作中不允许有停止和延迟。我们成功地将传统计算机视觉算法运用在了低功耗的设备上。
最后一个问题,我称之为皇冠上的珠宝,谁将为自主性(autonomy)编写操作系统?CMU是世界最先进的机器人研发基地之一,我们有超过3000个已经投入使用的机器人平台。有了这些经验,每当有人需要我们做一种新的机器人时,我们都能很快的完成。但目前我们仍旧是根据经验在做,没有人真正建立一个实际操作软件工具的操作系统。本世纪的前半叶,谁将为自主性(autonomy)编写所有的操作系统?
希望我的分享对接下来二十年学术界可以专注的AI发展方向有所帮助。
Andrew W. Moore个人介绍

Andrew W. Moore是卡内基梅隆大学(CMU)计算机学院的第十五位院长。他的研究领域主要有统计机器学习、人工智能、机器人技术以及大数据统计计算。他曾在机器人控制、制造、强化学习、天体物理算法、电子商务领域都有所建树。他的数据挖掘教程下载量已达100多万。他建立了Auton Lab研究组,该研究组设计了有效的关于大型统计操作的新方法,并在多种情况下都实现了几个数量级的加速效果。Auton研究组的成员与许多科学家、政府机构、技术公司都有着密切的合作,旨在不断寻求在计算、统计数据挖掘、机器学习和人工智能领域中最函待解决的问题。2006年,Andrew加入谷歌,参与Google Pittsburgh的建立。同时,他也参与了包括Google Sky和Android SkyMap的相关事宜。2014年8月,Andrew重返卡内基梅隆大学(CMU),继续担任计算机学院院长。
你也许还想看:
,共建交流平台。来稿请寄:msraai@microsoft.com。
 微软小冰进驻微软研究院微信啦!快去主页和她聊聊天吧。
微软小冰进驻微软研究院微信啦!快去主页和她聊聊天吧。









