周明:未来5-10年,自然语言处理将走向成熟

周明 微软亚洲研究院副院长
近日,微软亚洲研究院副院长周明在「自然语言处理前沿技术分享会」上,与大家讲解了自然语言处理(NLP)的最新进展,以及未来的研究方向,以下内容由CSDN记者根据周明博士的演讲内容编写,略有删减。
周明博士于1999年加入微软亚洲研究院,不久开始负责自然语言研究组。近年来,周明博士领导研究团队与微软产品组合作开发了微软小冰(中国)、Rinna(日本)、Zo(美国)等聊天机器人系统。周明博士发表了120余篇重要会议和期刊论文(包括50篇以上的ACL文章),拥有国际发明专利40余项。
微软亚洲研究院在机器翻译、中国文化、聊天机器人和阅读理解的最新进展
机器翻译
今年微软首先在语音翻译上全面采用了神经网络机器翻译,并拓展了新的翻译功能,我们叫做Microsoft Translator Live Feature(现场翻译功能),在演讲和开会时,实时自动在手机端或桌面端,把演讲者的话翻译成多种语言。
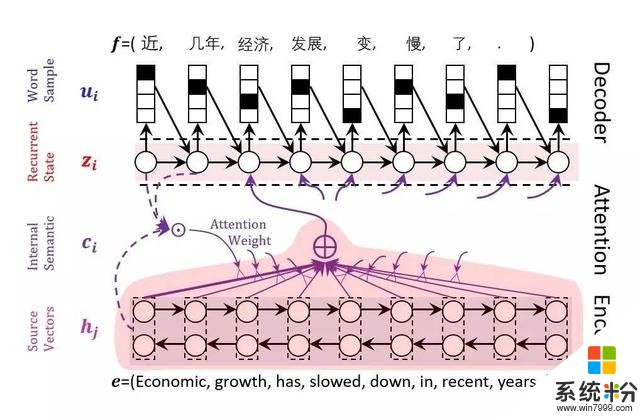
图1 神经网络机器翻译
图1概括了神经网络机器翻译,简要的说,就是对源语言的句子进行编码,一般都是用长短时记忆(LSTM)进行编码。编码的结果就是有很多隐节点,每个隐节点代表从句首到当前词汇为止,与句子的语义信息。基于这些隐节点,通过一个注意力的模型来体现不同隐节点对于翻译目标词的作用。通过这样的一个模式对目标语言可以逐词进行生成,直到生成句尾。中间在某一阶段可能会有多个翻译,我们会保留最佳的翻译,从左到右持续。
这里最重要的技术是对于源语言的编码,还有体现不同词汇翻译的,不同作用的注意力模型。我们又持续做了一些工作,引入了语言知识。因为在编码的时候是仅把源语言和目标语言看成字符串,没有体会内在的词汇和词汇之间的修饰关系。我们把句法知识引入到神经网络编码、解码之中,这是传统的长短时记忆LSTM,这是模型,我们引入了句法,得到了更佳的翻译,这使大家看到的指标有了很大程度的提升。
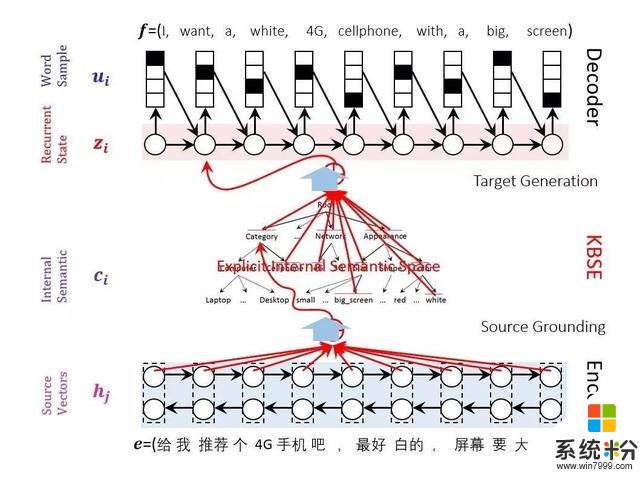
图2 将知识图谱纳入传统的神经网络机器翻译中
此外,我们还考虑到在很多领域是有知识图谱的,我们想把知识图谱纳入到传统的神经网络机器翻译当中,来规划语言理解的过程。我们的一个假设就是虽然大家的语言可能不一样,但是体现在知识图谱的领域上可能是一致的,就用知识图谱增强编码、解码。具体来讲,就是对于输入句子,先映射到知识图谱,然后再基于知识图谱增强解码过程,使得译文得到进一步改善。
以上两个工作都发表在本领域最重要的会议ACL上,得到很多学者的好评。
图3 Microsoft Translator Live Feature工作场景
中国文化
大家会说,中国文化和人工智能有什么关系?中国文化最有代表性的是对联、诗歌、猜谜语等等,它怎么能够用人工智能体现呢?好多人一想这件事就觉得不靠谱,没法做。但是我们微软亚洲研究院就利用然语言处理的技术,尤其是机器翻译的经验,果断进军到中国文化里,这个在全世界独树一帜。
在2004年的时候,当时我们的沈向洋院长领导我们做了一个微软对联:用户输入上联,电脑自动对出下联,语句非常工整,甚至更进一步把横批对出来。这个系统在当时跟新浪进行了合作,做成了一个手机游戏,用户可以通过发短信的方式,将上联发过去,然后通过短信接收下联。当时大家都觉得很有意思。微软对联也是世界上第一次采用机器翻译的技术来模拟对联全过程。过去也有人做对联游戏,都是用规则的方法写很多很多的语言学规则,确保什么样的词跟什么样的词对,并符合对仗、平仄一堆语言学的规则,但是实际效果不好,也没有人使用。
我们把机器翻译技术巧妙用在中国文化上,解决了这个问题。在微软对联的基础上,我们继续去尝试其他的中国文化,其中有一个特色就是字谜。
我们小时候都爱猜字谜,领奖品。字谜是给你谜面让你猜谜底。当然也可以反过来,给定一个谜底,让你出谜面。现在,已经可以用电脑来模拟整个猜字谜和出字谜的过程了,我们也把这个功能放在了微软对联的网站上。
往后,更进一步,我们还会用人工智能技术来发展中国最经典的文化,包括绝句和律诗等。例如宋词有长短句,我们也可以用同样的技术来创作律诗、绝句和宋词。
最近,微软亚洲研究院的主管研究员宋睿华博士就在用这种神经网络的技术来进行诗歌的创作。这件事非常有创意:用户提交一个照片,让系统进行,然后变成一首诗,自由体的诗。写诗是很不容易的,因为要体现意境。你说这是山,这是水,这不叫诗;诗歌必须要升华、凝练,用诗的语言来体现此时的情或者景,由景入情,由情入景,这才是诗。
不久前,微软小冰发布了微软小冰写诗的技能,引起了很多人的关注。我们也在此基础上展示其他的中国文化,把人工智能和中国文化巧妙结合起来,弘扬中国文化。
对话即平台
“对话即平台”英文叫做“Conversation as a Platform (CaaP)”。2016年,微软首席执行官萨提亚在大会上提出了CaaP这个概念,他认为继图形界面的下一代就是对话,它会对整个人工智能、计算机设备带来一场新的革命。

图4 通用对话引擎架构
为什么要提到CaaP这个概念呢?我个人认为,有两个原因。
● 源于大家都已经习惯用社交手段,如微信、Facebook与他人聊天的过程。我们希望将这种通过自然的语言交流的过程呈现在当今的人机交互中,而语音交流的背后就是对话平台。
● 现在大家面对的设备有的屏幕很小,有的甚至没有屏幕,所以通过语音的交互,更为自然直观的。因此,我们是需要对话式的自然语言交流的,通过语音助手来帮忙完成。
而语音助手又可以调用很多Bot,来完成一些具体的功能,比如说定杯咖啡,买一个车票等等。芸芸众生,有很多很多需求,每个需求都有可能是一个小Bot,必须有人去做这个Bot。而于微软而言,我们作为一个平台公司,希望把自己的能力释放出来,让全世界的开发者,甚至普通的学生就能开发出自己喜欢的Bot,形成一个生态的平台,生态的环境。
如何从人出发,通过智能助理,再通过Bot体现这一生态呢?微软在做CaaP的时候,实际上有两个主要的产品策略。
第一个是小娜,通过手机和智能设备介入,让人与电脑进行交流:人发布命令,小娜理解并执行任务。同时,小娜作为你的贴身处理,也理解你的性格特点、喜好、习惯,然后主动给你一些贴心提示。比如,你过去经常路过某个地方买牛奶,在你下次路过的时候,她就会提醒你,问你要不要买。她从过去的被动到现在的主动,由原来的手机,到微软所有的产品,比如Xbox和Windows,都得到了应用。现在,小娜已经拥有超过1.4亿活跃用户,在数以十亿级计的设备上与人们进行交流。现在,小娜覆盖的语言已经有十几种语言,包括中文。小娜还在不断发展,这背后有很多自然语言技术来自微软研究院,包括微软亚洲研究院。
第二个就是小冰。它是一种新的理念,很多人一开始不理解。人们跟小冰一起的这种闲聊有什么意思?其实闲聊也是人工智能的一部分,我们人与人见面的时候,寒喧、问候、甚至瞎扯,天南海北地聊,这个没有智能是完成不了的,实际上除了语言方面的智能,还得有知识智能,必须得懂某一个领域的知识才能聊起来。所以,小冰是试图把各个语言的知识融汇贯通,实现一个开放语言自由的聊天过程。这件事,在全球都是比较创新的。现在,小冰已经覆盖了三种语言:中文、日文、英文,累积了上亿用户。很多人跟它聊天乐此不疲,而平均聊天的回数多达23轮。这是在所有聊天机器人里面遥遥领先的。而平时聊天时长大概是25分钟左右。小冰背后三种语言的聊天机器人也都来自于微软亚洲研究院。
无论是小冰这种闲聊,还是小娜这种注重任务执行的技术,其实背后单元处理引擎无外乎就三层技术:
● 通用聊天,需要掌握沟通技巧、通用聊天数据、主题聊天数据,还要知道用户画像,投其所好。
● 信息服务和问答,需要搜索的能力,问答的能力,还需要对常见问题表进行收集、整理和搜索,从知识图表、文档和图表中找出相应信息,并且回答问题,我们统称为Info Bot。
● 面向特定任务的对话能力,例如定咖啡、定花、买火车票,这个任务是固定的,状态也是固定的,状态转移也是清晰的,那么就可以用Bot一个一个实现。你有一个调度系统,你知道用户的意图就调用相应的Bot 执行相应的任务。它用到的技术就是对用户意图的理解,对话的管理,领域知识,对话图谱等等。
实际上,人类拥有这全部三个智能,而且人知道什么时候用什么智能,就是因为最上头,还有一个调度系统。你跟我闲聊的时候,我就会跟你闲聊;你跟我严肃地问问题,那么我就会回答你的问题。通过一个调度系统,可以想象,我们在做人机对话的时候,其实是在根据用户的提问调用不同的引擎,再根据不同的意图调用不同的Bot。这样整体来实现一个所谓的人机交互全过程。这背后的技术由不同的研究员分别去进行实施,然后再整体通过跟产品组合作体现一个完美的产品流程。
微软想把有关的能力释放给全世界,让每个人都能够体验人工智能的好处,让开发者开发自己的Bot。但是开发者的机器不懂自然语言,怎么办呢?我们就通过一个叫Bot Framework的工具、平台来实现。
任何一个开发者只用几行代码就可以完成自己所需要的Bot。这里有一个简单的例子,这个人想做一个披萨的Bot,他用Bot的框架,这几行语句填入相应的知识,相应的数据,就可以实现一个简单的定披萨的Bot。你可以想象很多小业主,没有这种开发能力,但是就是可以简单操作几下,就可以做一个小Bot吸引来很多客户。
这里面有很多关键技术。微软有一个叫做LUIS(Language Understanding Intelligent Service)的平台,提供了用户的意图理解能力、实体识别能力、对话的管理能力等等。比如说这句话“read me the headlines”,我们识别的结果是他想做朗读,内容就是今天的头条新闻。再比如说“Pause for 5 minutes”,我们理解它的意思是暂停,暂停多长时间?有一个参数:5分钟。所以,通过LUIS,我们可以把意图和重要的信息抽取出来,让后面Bot来读取。
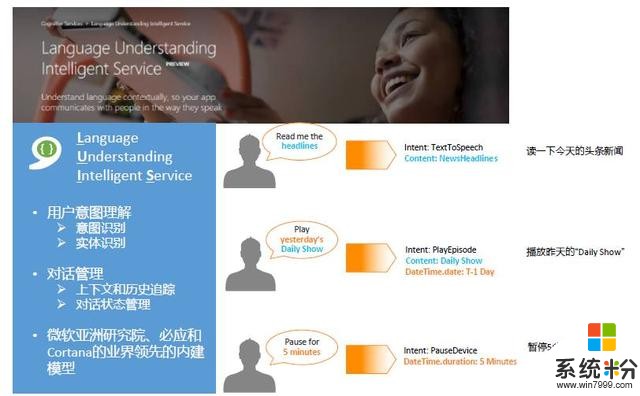
图5 微软语言理解服务
微软的聊天对话技术也在与很多企业合作,赋能这些企业。比如,我们跟敦煌研究院合作。敦煌研究院提供出数据,我们则把我们的引擎加上去,很快就建立了一个敦煌研究院的客服系统,借助敦煌研究院公众号,可以让用户和它聊与敦煌有关的事。用户也可以问问题,例如敦煌研究院什么时候开门、有什么好吃的,他可以把聊天、对话都集成在一个平台上,发挥人工智能在公众号上的作用。
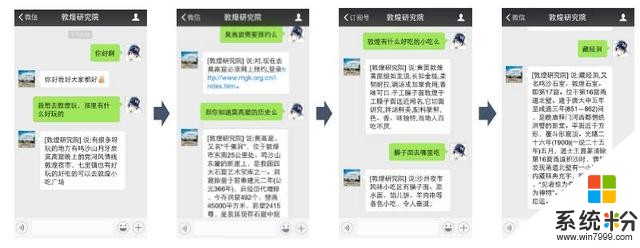
图6 敦煌公众号客服系统
阅读理解
阅读理解顾名思义就是给你一篇文章,看你理解到什么程度。人都有智能,而且是非常高的智能。除了累积知识,还要懂一些常识。具体测试你的阅读能力、理解能力的手段,一般都是给一篇文章,再你一些问题。你能来就说明你理解了,答不上来就说明你不理解。对电脑的测试也是这样。

图7 莱茵河介绍
我给大家举个例子,说明一下阅读理解。图7中,这一段话的大意是在介绍莱茵河,它流经哪些国家,最终在哪里注入大海。莱茵河畔最大的城市是德国科隆。它是中欧和西欧区域的第二长河流,仅次于多瑙河之后,约1230公里。然后,我们问的问题是,什么河比莱茵河长?当你读完了这段话,你就要推断,“after”在这里是什么意思,从而才能得出正确答案是多瑙河。电脑要做这道题,实际上要仔细解析很多问题,最终才能作出回答。
未来5-10年,NLP将走向成熟
最后,再介绍一下我对自然语言处理目前存在的问题以及未来的研究方向的一些考虑,供大家参考。
● 随着大数据、深度学习、云计算这三大要素推动,所谓认知智能,尤其是语言智能跟感知智能一样会有长足的发展。你也可以说,自然语言处理迎来了60余年发展历史上最好的一个时期,进步最快的一个时期,从初步的应用到搜索、聊天机器人上,到通过对上下文的理解,知识的把握,它的处理能力得到长足的进步。具体来讲,我认为,口语机器翻译肯定会完全普及,将来我认为它就是手机上的标配。任何人出国,无论到了哪个国家,拿起电话来你说你的母语,跟当地人交流不会有太大的问题,而且是非常自如的过程,就跟你打电话一样。所以,我认为口语机器翻译会完全普及。虽然这不意味着同声翻译能彻底颠覆,也不意味着这种专业领域的文献的翻译可以彻底解决;但我认为还是会有很大的进展。
● 自然语言的会话、聊天、问答、对话达到实用程度。这是什么意思?这意味着在常见的场景下,通过人机对话的过程完成某项任务。这个是可以完全实现,或者跟某个智能设备进行交流,比如说关灯、打开电脑、打开纱窗这种一点问题都没有,包括带口音的说话都可以完全听懂。但是同样,这也不代表任何话题、任何任务、用任何变种的语言去说都可以达到。目前离那个目标还很远,我们也在努力。
● 智能客服加上人工客服完美的结合,一定会大大提高客服的效率。我认为很多重复的客服工作,比如说问答,还有简单的任务,基本上人工智能都可以解决。但是复杂的情况下仍然不能解决。所以,它实际上是人工智能跟人类智能完美结合来提高一个很好的生产力,这个是没有问题的。
● 自动写对联、写诗、写新闻稿和歌曲等等,今天可能还是一个新鲜的事物,但是5到10年一定都会流行起来,甚至都会用起来。比如说写新闻稿,给你一些数据,这个新闻稿草稿马上就写出来,你要做的就是纠正,供不同的媒体使用等。
● NLP将推动语音助手、物联网、智能硬件、智能家居的普及。
● NLP与其他AI技术一起在金融、法律、教育、医疗等垂直领域将得到广泛应用。
但是,我们也清醒地看到,虽然有一些很好的预期,但是自然语言处理还有很多很多没有解决的问题。以下几个我认为比较重要的。
1.通过用户画像实现个性化服务。现在自然语言处理基本上用户画像用得非常非常少。人与人的对话,其实是对不同的人说不同的话,因为我们知道对话的人的性格、特点、知识层次,我了解了这个用户,知道用户的画像,那么在对话的时候就会有所调整。目前来讲,我们还远远不能做到这一点。
2.通过可解释的学习洞察人工智能机理。现在自然语言处理跟其他的人工智能一样,都是通过一个端对端的训练,而其实里面是一个黑箱,你也不知道发生了什么,哪个东西起作用,哪个东西没有起作用。我们也在思考,有没有一种可解释的人工智能,帮助我们知道哪些地方发挥了作用,哪些地方是错的,然后进行修正,快速调整我们的系统。目前还没有针对这个问题很好的解决方案,尽管有一些视觉化的工作,但是都比较粗浅,还没有达到最精准的判定和跟踪。
3.通过知识与深度学习的结合提升效率。所谓知识和深度学习的结合,有可能很多情况下是需要有人类知识的。比如说客服,是有一些常见处理过程的。那么出现问题我该怎么解决?这些知识如何跟数据巧妙结合,从而加快学习的过程、提高学习的质量,这也是比较令人关注的。
4.通过迁移学习实现领域自适应。如果们想翻某一个专业领域,比如说计算机领域,可能现有的翻译工具翻得不好。所以大家都在研究,有没有一种办法,能够帮助机器进行迁移学习,能够更好的运用到语音自适应上。
5.通过强化学习实现自我演化。这就是说我们自然语言系统上线之后有很多人用,得到了有很多人的反馈,包括显示的反馈、隐式的反馈,然后通过强化学习不断的提升系统。这就是系统的自我演化。
6.最后,我认为也是非常关键的,通过无监督学习充分利用未标注数据。现在都依赖于带标注的数据,没有带标注的数据没有办法利用。但是很多场景下,标注数据不够,你找人工标注代价又极大。那么如何用这些没有标注的数据呢?这就要通过一个所谓无监督的学习过程,或者半监督的学习过程增强整体的学习过程。这里也是目前研究上非常令人关注的。
【本文由CSDN根据周明博士的演讲内容编写,已获授权转载】
你也许还想看:
,共建交流平台。来稿请寄:msraai@microsoft.com。 微软小冰进驻微软研究院微信啦!快去主页和她聊聊天吧。
微软小冰进驻微软研究院微信啦!快去主页和她聊聊天吧。 








