谷歌首次透露TPU细节:处理速度是GPU/CPU的15-30倍
在2016年5月的I/O开发者大会上,谷歌首次向外透露了其机器学习专用芯片Tensor处理单元(TPU)。之后,谷歌除了公布它们是围绕公司自身进行优化的TensorFlow机器学习框架之外,就再未透露更多的细节。今日,谷歌的硬件工程师Norm Jouppi首次向外分享了更多关于该项目的细节和测试结果。

如果你是一个芯片设计师,你可以在谷歌公布的研究报告里找到很多关于这一TPU如何运作的细节。
在此次测试中,谷歌基于自己的基准测试对自研芯片进行了测试。测试结果表明,TPU在执行谷歌常规机器学习工作负载方面,比一个标准的GPU/CPU组合(一般是Intel Haswell处理器和Nvidia K80 GPU组合的情况下)平均要快15-30倍。另外,由于数据中心的功耗计算,TPU还能提供高达30-80倍瓦特的速率。研究报告作者表示,如果将来使用更快的内存,该TPU还有进一步优化的空间。
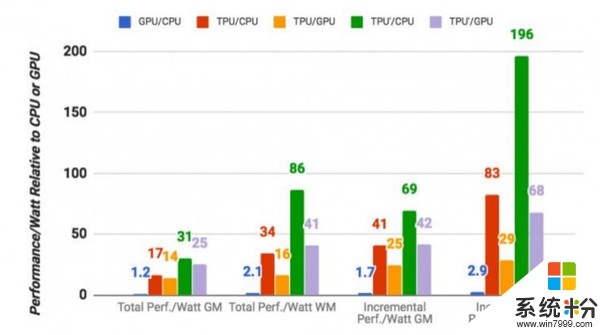
值得注意的是,这些数字是关于在生产中使用机器学习模型的,而不是首次创建模型。
谷歌还指出,虽然大多数架构师为卷积神经网络(convolutional neural networks,例如,对于图像识别工作良好的特定类型的神经网络)优化了其芯片。然而,谷歌表示,这些网络只占其数据中心工作负载的5%左右,而大部分应用使用的是多层感知器( multi-layer perceptrons)。
机器学习的本质是密集计算,比如 Google 工程师举的例子 —— 如果人们每天用三分钟的语音搜索,但运行没有 TPU 加持的语音识别人物的话,该公司将需要建造两倍多的数据中心。
事实上,据谷歌表示,该公司在2006年就已开始研究如何其数据中心中使用GPU,FPGA和自定义ASICS(其实质上是TPU)。然而,由于他们所需的大量工作负载,可能只能利用数据中心里面已经可用的多余硬件,而当时并没有那么多的应用程序真的可以在这种特殊硬件中受益。
据悉,谷歌已经将TPU用于许多内部项目,如机器学习系统RankBrain、Google街景、以及AlphaGo等。但Google尚未给出将TPU应用于外部项目的计划。
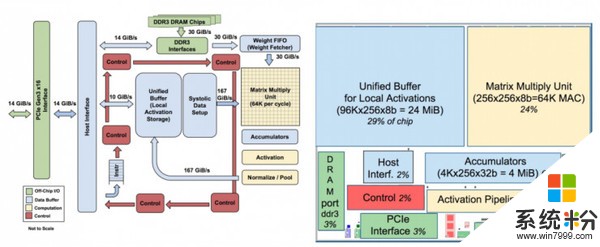
谷歌在其研究报告里表示:2013年,我们预计到DNN或许在将来会成为非常受欢迎的方向,而这可能会使数据中心的计算需求增加一倍,如果要满足传统的CPU将会需要高昂的价格。“因此,我们开始了这个高度优先的项目,以快速生成用于推理的定制ASIC(并购买了现成的GPU来进行培训)。”谷歌一位工程师表示。
据雷锋网(公众号:雷锋网)了解,谷歌不太可能在其云端之外提供TPU。不过谷歌表明,预计将来会有其他人采用我们所学到的知识,并“成为更高水准的继任者”。
来源:雷锋网









