讲堂|黄学东:微软是如何利用人工智能技术做好语音识别的

前不久,微软人工智能及微软研究事业部技术院士、微软首席语音科学家黄学东博士,作为清华大学的校友在母校举办了一场讲座,为大家回顾了微软在人工智能领域的最新成就,并详细解释了微软是如何使用微软认知工具包CNTK在语音识别和机器翻译研究中取得最新进展的。
想知道微软语音识别技术达到人类专业水平背后的惊天大秘密么?快来一起听听黄学东博士的分享。
今天我想给大家分享一下微软在人工智能领域取得的一些最新突破,也分享一下我们在20多年的历程中,是怎样持之以恒取得这些突破的。
先看看今年《经济学人杂志》的封面故事——我们终于可以和机器讲话了。里面有一个很有名的图表总结了整个领域从1954年IBM科学家第一次进行机器翻译的探索,到2016年微软第一次在会话语音识别上达到人类水平的历史性突破。
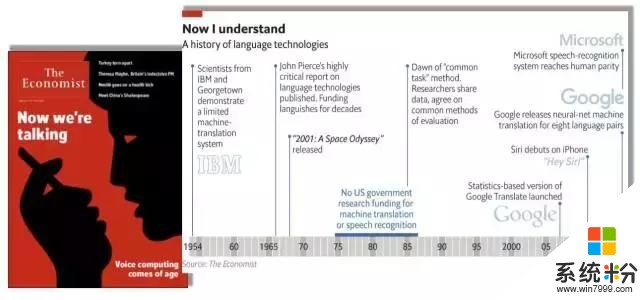
在几十年的历程中,有非常多优秀的公司在语音和语言领域进行了不懈地探索,终于在今天,达到了和人一样精准的语音识别,这是非常了不起的历史性突破。
1982年我在清华做硕士论文时,做的就是语音识别。硕士毕业读博士时,我在计算机系方棣棠先生的带领下,继续做这方面的研究。很难想象在我的有生之年,我们能让计算机语音识别可以达到如此精准的水平。所以想跟大家分享一下,我们是怎样追求这个梦想,持之以恒,通过不懈的努力达到历史性突破的。
近两年人工智能受到热议,其实人工智能包括了两个主要的类别以及三个主要的因素:
第一,平台。比如我要到清华演讲,一定会有个场地,有一个舞台,而这个舞台就相当于计算。今天的计算通过英特尔、英伟达等公司的不懈努力和1982年我们在苹果、IBM PC/XT上面做的语音识别是有天壤之别的。当时我们在IBM PC/XT上用了德州仪器公司的TMS320,我还用汇编语言在上面写了第一个开发程序。如今,要做先进的语音识别训练也需要GPU,这和当年的TMS320有异曲同工之妙。这是第一,要有一个平台。
第二,数据。我在这里讲话要有氧气。人工智能和语音识别也是一样的,要有大数据才能把算法做得精准。
第三,算法。算法很重要,要有内容。
这三点,缺一不可。
再来人工智能包括感知和认知这两大块。可以毫无疑问地说,在感知这个领域,人工智能已经几乎达到人类同样的水平,但这当然是在特定任务的情况下。在认知领域,包括自然语音理解、推理、知识学习等,我觉得还差的很远。所以大家在说人工智能达到了前所未有的高度时,一定要搞清楚,说的是在认知领域还是在感知领域。
下面让我们来看看微软在人工智能领域所取得的一些成果。首先,微软有二十多年的积累,微软研究院在建院时的第一个愿景就是希望让计算机能听、能看、能说、能够学习。这和现在人工智能所发展的方向以及能做到的工作基本上是一模一样。
2015年,微软亚洲研究院率先在计算机视觉领域有了很大的突破。研究员们在当年的ImageNet图像识别挑战赛中使用了神经网络有152层的深度学习,这是非常了不起的突破。而去年微软在语音识别的Switchboard上再次取得重大突破,使得计算机的语音识别能力超过世界上绝大多数人,与人类专业高手持平。
语言是人类特有的交流工具。今天,计算机可以在假定有足够计算资源的情况下,非常准确地识别你和我讲的每一个字,这是一个非常大的历史性突破,也是人工智能在感知上的一个重大里程碑。
所以,我想简单回顾一下语音识别的发展历程。几年前我和James Baker,Raj Reddy合写了一篇文章。Raj Reddy是图灵奖得主,James Baker是第一个用马尔可夫模型做语音识别的人,当年创建了Dragon公司并一直担任CEO,我最年轻。所以文章可以说表达了我们三代人在语音领域过去40年里的一些追求。虽然文章发表在两年前,但现在看里面讲的很多东西已经过时了,因此可以看出这个领域的进展有多么神速。

再看看Switchboard,这是整个工业界常用的一个测试数据集。很多新的领域或新的方法错误率基本都在20%左右徘徊。大规模标杆性的进展是IBM Watson,他们的错误率在5%到6%之间,而人的水平基本上也在5%到6%之间。过去20年,在这个标杆的数据集上,有很多公司都在不懈努力,如今的成果其实并不是一家公司所做的工作,而是整个业界一起努力的结果。
各种各样的神经网络学习方法其实都大同小异,基本上是通过梯度下降法(Gradient Descent)找到最佳的参数,通过深度学习表达出最优的模型,以及大量的GPU、足够的计算资源来调整参数。所以神经网络对计算机语音识别的贡献不可低估。早在90年代初期就有很多语音识别的研究是利用神经网络在做,但效果并不好。因为,第一,数据资源不够多;第二,训练层数少。而由于没有计算资源、数据有限,所以神经网络一直被隐马尔可夫模型(Hidden Markov Model)压制着,无法翻身。
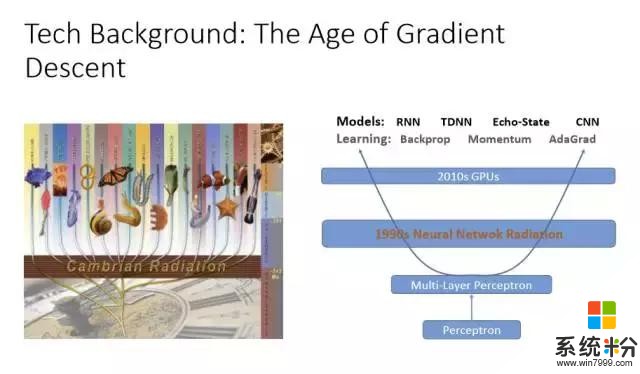
深度学习翻身的最主要原因就是层数的增加,并且和隐马尔可夫模型结合。在这方面微软研究院也走在业界的前端。深度学习还有一个特别好的方法,就是特别适合把不同的特征整合起来,就是特征融合(Feature Fusion)。
如果在噪音很高的情况下可以把特征参数增强,再加上与环境噪音有关的东西,通过深度学习就可以学出很好的结果。如果是远长的语音识别,有很多不同的回音,那也没关系,把回音作为特征可以增强特征。如果要训练一个模型来识别所有人的语音,那也没有关系,可以加上与说话人有关的特征。所以神经网络厉害的地方在于,不需要懂具体是怎么回事,只要有足够的计算资源、数据,都能学出来。
我们的神经网络系统目前有好几种不同的类型,最常见的是借用计算机视觉CNN(Convolution Neural Net,卷积神经网络)可以把不同变化位置的东西变得更加鲁棒。你可以把计算机视觉整套方法用到语音上,把语音看成图像,频谱从时间和频率走,通过CNN你可以做得非常优秀。另外一个是RNN(Recurrent Neural Networks,递归神经网络),它可以为时间变化特征建模,也就是说你可以将隐藏层反馈回来做为输入送回去。这两种神经网络的模型结合起来,造就了微软历史性的突破。
微软语音识别的总结基本上可以用下图来表示。
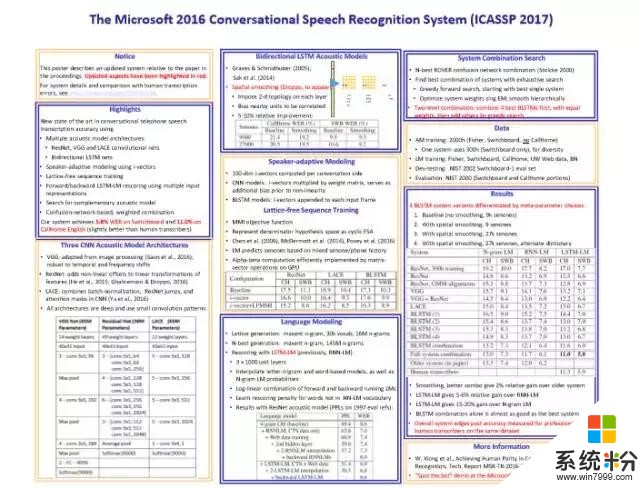
这是2017年ICASSP刚刚发表的一篇文章。我先给大家简单介绍一下。
第一,Switchboard和人类比较的时候,很多人做过不同的实验。1997年Lippman就做了大量的实验,人的错误率大约在4%左右,当时的语音识别系统错误率在80%左右,从80%到4%这是遥不可及的,那时是90年代中期。
当然,测试数据也在不断变化,后来微软把测试数据送给人工标注专家进行测试,但并不告诉他们这是要测的,而是把这些数据当成是普通数据标注的一部分。我们得到的人工标注专家的错误率是5.9%。后来IBM又请澳大利亚最优秀的专家反复听,用4个团队标注,它的错误率在5.1%左右。我相信如果让我们这些普通大众来标注,错误率都将超过6%。
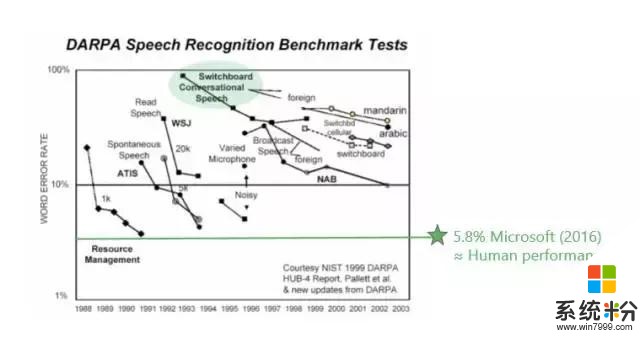
上图是业界在过去几十年里面错误率下降的指标,可以看到5.8%是微软在去年达到的水平。Switchboard的错误率从80%左右一直到5.8%左右,是用了什么方法呢?我们是怎么达到这个目标呢?

大家知道语音识别有两个主要的部分,一个是语音模型,一个是语言模型。
语音模型我们基本上用了6个不同的神经网络,并行的同时识别。很有效的一个方法是微软亚洲研究院在计算机视觉方面发明的ResNet(残差网络),它是CNN的一个变种。当然,我们也用了RNN。可以看出,这6个不同的神经网络在并行工作,随后我们再把它们有机地结合起来。在此基础之上再用4个神经网络做语言模型,然后重新整合。所以基本上是10个神经网络在同时工作,这就造就了我们历史性的突破。
下面给大家分享一下微软在人工智能方面的一些研究和开发总览。
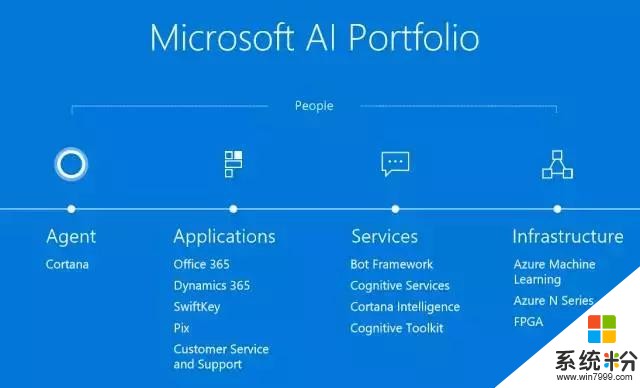
微软在人工智能方面有四个重要的技术。(1)计算非常重要,以Azure为代表,我们在基础架构上有很高的投入;(2)Service方面,我们提供了很多如微软认知服务、微软认知工具包等服务和工具,大家可以使用它们创造各自的人工智能应用;(3)我们的应用都会利用微软的认知服务来增强它们的智能特质;(4)我们认为人工智能最有标志性的是对话,所以在对话里我们有几个具有代表性的Agent。
刚才提到的微软认知服务,它包括了20多个人工智能领域的API,我们将其打包,以云服务的方式提供。如果你是一个开发人员,那么你不需要掌握人工智能、计算机视觉、机器翻译等等的技术知识,只需调用API就可以了。通过这种形式,微软为广大的应用开发人员提供了一个良好的服务。
而源自于中国团队的微软小冰,其语音合成基本上达到了非常高的水平。小冰的自然度、情绪表达能力已经很接近人类水平了,比业界其他的合成系统有一个很大的提高,这也是得益于深度学习。
另外,微软的研究使得语音识别在Switchboard达到了很高的水平,但是跨领域的语音识别performance还是一个问题,所以微软提供了一个可以量身定制的语音识别系统。微软的自定义语音服务(Custom Speech Service)在每个人的应用场景里都可以完全量身定制语音识别系统。这是微软把人工智能普及化的最好案例之一。
接下来,讲讲我们团队在机器翻译里的进步。微软机器翻译其实做了很长时间,目前机器翻译我们可以同时支持100个讲不用语言的人使用。如果我的演讲PPT是英文,我要把它翻译成英、法、日、德等,只要用手机下载了Microsoft Translator应用,照一张相就可以翻译成你需要的语言。Microsoft Translator可以支持60种语言的翻译,所以当到任何地方去,只要用Microsoft Translator,就可以消除所有的语言障碍。
Microsoft Translator的现场翻译功能是一个非常有意义的使用案例,也是用深度学习来达到一个非常高性能指标的成功案例。它用的神经网络语言模型是联合模型,不仅仅是原语言、目标语言的dependency都可以用神经网络来训练,它用的语言模型也是LSTM。以前统计机器翻译的运作方法和语音系统非常类似。现在最新的神经网络机器翻译,其实非常简单,它就是有一套输入系统,用的是LSTM,有一套输出系统用的也是LSTM,LSTM输入系统有一个最后的状态,这个状态通过一些加权,可以通过解码器的方法产生输出的语言句子,基本的架构就是这样。
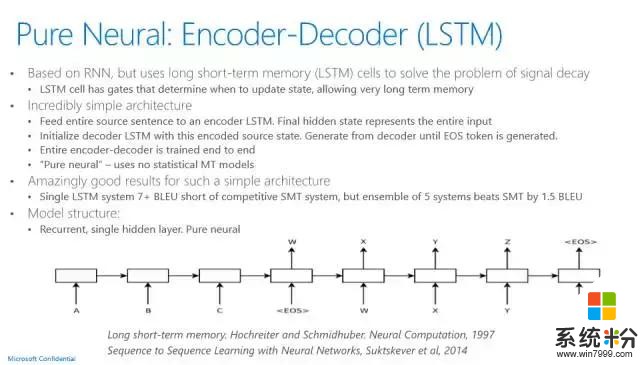
和传统的机器翻译相比,神经网络机器翻译像语音识别一样,有了一个大幅度的提高,涨了四个点。做机器翻译研究的应该都知道,这是一个很了不起的历史性的进步。目前,语音识别在有计算资源的情况下可以达到人的水平,我相信,机器翻译也指日可待。
尽管我们语音识别达到了历史性的水平,但是语音理解还有很长的路要走。微软在智能客服方面做了很多工作,现在微软产品的客服上已经使用了有深度学习的人工智能,这个功能目前已在微软美国上线了。
如果,用户有关于微软产品线的问题需要相关的支持,这时就是微软人工智能在帮忙回答问题。这里涉及的是有深度的,也很有挑战性的客服问题,是需要有深度训练的人工智能。比如,问-怎么样才能升级Windows?人工智能回答-你现在的Windows是什么样的产品?用户-XP。然后它会给你具体的建议,如果不满意,那么可以点击一个链接,这时候就有真实的客服人员帮你解决问题。智能客服的经济效益是极大的。
微软用最先进的人工智能帮用户解决问题,而这也是微软的人工智能和其他人工智能最不同的地方,理念的不同,产品思路的不同。
刚刚讲了好几个案例,从语音识别到语音合成到智能客服,他们都得益于深度学习的进步。其实我们最大得益于的是微软有一个自己开源的认知工具包,叫Computational Network Toolkit(CNTK)。它为我们提供了强大的计算力量。有人会问,强大到什么地步?大家都知道谷歌有一个TensorFlow,它非常流行,大家谈到深度学习一定会觉得TensorFlow很强大。此前英伟达做了一个评测,这个评测是图型越高越好。黄色是谷歌的TensorFlow,蓝色是微软的CNTK,可以看出不仅仅是一个GPU、两个GPU、四个GPU、八个GPU,微软是全线超越最流行的深度学习工具包。
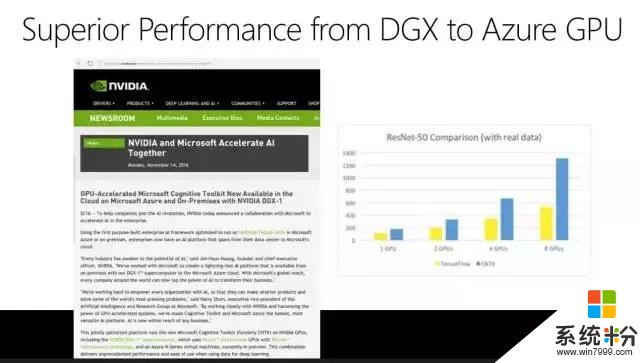
ComputerWorld在2017年2月份做了一个评测,它说微软CNTK的性能是10,TensorFlow也是10。它把几个不同的深度学习工具包做了一个打分,我们是第二名,你如果要关注速度的话,CNTK是非常优秀的。这也是微软的语音识别系统为什么能做到历史性的突破,我们做了非常多的实验,如果没有CNTK这样高速的工具包很难想象我们可以取得今天的成绩。
最后一点要讲,微软Azure计算平台不仅仅有GPU还有FPGA,FPGA对实时运算速度的提高也是很大的,这样强大的计算机系统可以在云上为我们提供强大的计算资源。
总结一下,这是整个微软公司在人工智能领域所做的一些基本工作。从Azure到Cortana,到应用再到服务,我们想为大家提供一个非常强大的服务。我们的愿景很明确,就是为大家提供人工智能的实惠,普及人工智能的开发和应用,这就是我的总结和我们今天能达到人类语音识别水平的背后故事,谢谢大家!
作者简介
黄学东博士,微软人工智能及微软研究事业部技术院士,目前领导微软在美国、中国、德国、以色列的全球团队,负责研发微软企业人工智能、微软认知服务等最新人工智能产品和技术。作为微软首席语音科学家,黄学东博士领导的语音和对话研究团队在 2016 年取得了语音识别历史性的里程碑。
1993年加盟微软之前,黄学东博士在卡内基-梅隆大学计算机学院工作。曾荣获1992年艾伦纽厄尔研究卓越领导奖、1993年IEEE 最佳论文奖、2011年全美亚裔年度工程师奖。2016年Wired 杂志评选他为全球创造未来商业的25位天才之一。
他在爱丁堡大学、清华大学、湖南大学分别获得博士、硕士、学士学位。他还已获IEEE和ACM院士等殊荣。









