科大讯飞力压微软获机器阅读理解SQuAD测试第一
对于人类来说,通过阅读理解获取知识,通过对海量数据的分析了解世界是最平常不过的事情。但对于一个智能系统来说,要实现这个功能却非常困难。攻克这个困难,让阅读理解成为智能系统的标配也成为了各家科技公司研究开发的焦点之一。
据澎湃新闻8月2日报道,近日,科大讯飞与哈工大联合实验室(HFL)提交的系统模型,在斯坦福大学发起的SQuAD(Stanford Question Answering Dataset)挑战赛当中取得了第一名的成绩。这也是中国本土研究机构首次取得该赛事的榜首。
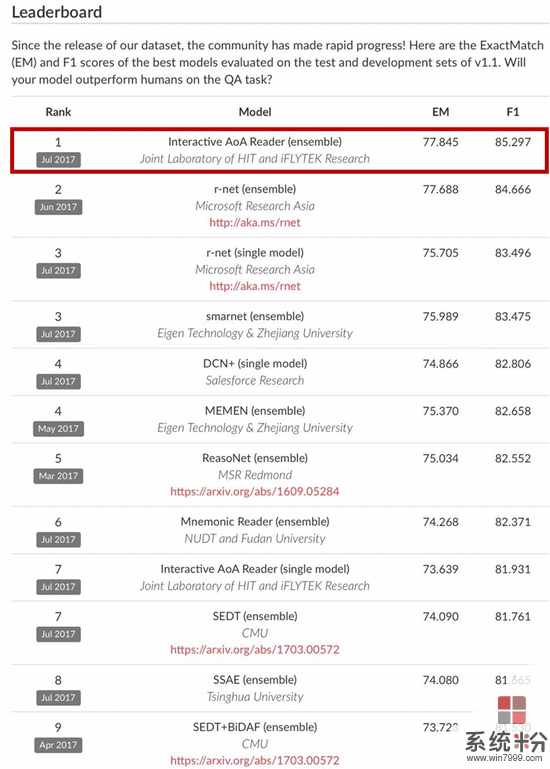
SQuAD挑战赛最新成绩榜单:
科大讯飞AI研究院副院长、哈工大讯飞联合实验室副主任王士进告诉澎湃新闻:“对机器来说,记忆海量知识并进行浅层推理,是一个相对较容易的工作,之前很多相关的工作证明了机器不比人类差,但精准的理解并实现推理,是一个相对更难的任务,为此目前全球最优秀的AI团队都在进行类似的研究。”
据王士进介绍,2015年5月,哈工大讯飞联合实验室开始启动研究机器阅读理解技术,是国内较早启动该项研究的团队。随后该团队又启动了内部项目 “六龄童阅读理解”,期待机器在认知智能上达到六岁儿童的智力,希望通过颠覆式的技术创新,做到机器看文章能够做出理解、推理和求解。
从众多外国研究机构手中拿下第一名
据楚北网报道,SQuAD挑战赛是行业内公认的机器阅读理解标准水平测试,也是该领域的顶级赛事,被誉为机器阅读理解界的ImageNet(图像识别领域的顶级赛事)。
参赛者来自全球学术界和产业界的研究团队,包括微软亚洲研究院、艾伦研究院、IBM、Salesforce、Facebook、谷歌以及卡内基·梅隆大学、斯坦福大学等知名企业研究机构和高校,赛事对自然语言理解的进步有重要的推动作用。
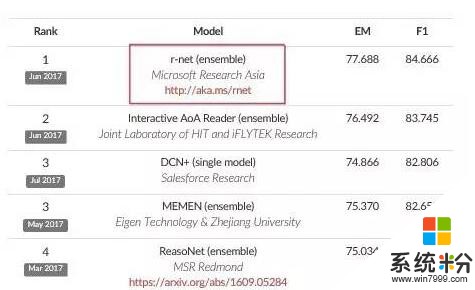
在科大讯飞今年获得第一名之前,微软亚洲研究院的自然语言计算研究组持续稳居榜首。
SQuAD挑战赛通过众包的方式构建了一个大规模的机器阅读理解数据集(包含10万个问题),将一篇几百词左右的短文给人工标注者阅读,让标注人员提出最多5个基于文章内容的问题并提供正确答案,短文原文则来源于500多篇维基百科文章。参赛者提交的系统模型在阅读完数据集中的一篇短文之后,回答若干个基于文章内容的问题,然后与人工标注的答案进行比对,得出精确匹配(Exact Match)和模糊匹配(F1-score)的结果。
SQuAD向参赛者提供训练集用于模型训练,以及一个规模较小的数据集作为开发集,用于模型的调优和选型。与此同时,SQuAD还提供了一个开放平台供参赛者提交自己的算法,由SQuAD官方利用隐藏的测试集对参赛系统进行评分,并在SQuAD官方确认后将相关结果更新到官网上。
得益于SQuAD提供的大规模高质量的训练数据以及层出不穷的模型,该挑战赛的榜单一次又一次的刷新。目前,根据SQuAD此次公布的结果,科大讯飞与哈工大联合实验室提交的系统模型取得了精确匹配77.845%和模糊匹配85.297%的成绩,位列世界第一。
如何夺取全球第一
在SQuAD官网的成绩榜单上,可以看到科大讯飞与哈工大联合实验室提交的模型名为“Interactive AoA Reader”,这是讯飞经过不断摸索之后提出的“基于交互式层叠注意力模型”(Interactive Attention-over-Attention Model)。正是这个与众不同的模型,让科大讯飞在全球自然语言理解研究领域脱颖而出跃居头名。

要解决机器阅读理解的问题,传统的自然语言处理(NLP)方式是采用分拆任务的方法将其分成问题分析、篇章分析、关键句抽取等一些步骤,只是这种方法容易造成级联误差的积累,很难得到很好的效果。
为了解决这种误差,科学家们又提出了完全端到端的神经网络建模。采用神经网络的方法能够,消除了分步骤产生的级联误差;通过大量的训练数据学习到泛化的知识表示,对篇章和问题从语义层面上高度抽象化。
科大讯飞此次提交给SQuAD的模型,也采用了端到端的神经网络模型,但把精力更多放在如何能够模拟人类在做阅读理解问题时的一些方法。
讯飞提出的基于交互式层叠注意力模型,主要思想是根据给定的问题对篇章进行多次的过滤,同时根据已经被过滤的文章进一步筛选出问题中的关键提问点。这样“交互式”地逐步精确答案的范围,与其他参赛者的做法不太相同,最终收获了令人瞩目的成绩。
王士进告诉澎湃新闻,实际上在此次挑战赛之前,哈工大讯飞实验室在Google Deepmind、Facebook等阅读理解测试集上都取得过最好成绩。但应用SQuAD公开测试集上表现并不理想,于是他们在原创技术上根据要求进行了大幅改进。
“因为SQuAD测试是通过众包的方式构建了一个大规模的机器阅读理解数据集,答案并不只是单个词,因此直接应用我们在完形填空式问题上使用的AoA Reader等原创技术效果并不理想。后来我们针对此类问题对AoA Reader做了大幅的改进,主要思想是根据给定的问题对篇章进行多次的过滤,同时根据已经被过滤的文章进一步筛选出问题中的关键提问点,同时我们利用了多个不同类型的模型进行融合,最终在效果上有了明显的提升。”王士进说。
机器学会阅读理解的意义
科大讯飞认为,人工智能的发展主要分为运算智能、感知智能和认知智能。机器在运算智能上有极大的优势,在感知智能上也已经取得了很大的进展,例如语音识别、语音合成、图像识别、机器翻译等。而在认知智能方面,自然语言处理一直是实现人机交互、人工智能的重要技术基石,机器阅读理解正是这一领域的一个研究焦点。同样,让机器实现“能听会说”到“能理解会思考”,也一直是科大讯飞所肩负的使命和方向。
早在2014年,科大讯飞与哈尔滨工业大学就联合成立了联合实验室,作为“讯飞超脑”计划的核心研发团队之一,联合实验室致力于在语言认知计算领域进行长期、深入的技术创新,重点突破深层语义理解、逻辑推理决策、自主学习进化等认知智能关键技术,并围绕教育学习、人机语音交互、信息安全等领域实现科研成果的规模化应用。
据科大讯飞介绍,哈工大讯飞联合实验室不仅能让机器在阅读理解比赛中“考出高分”,还能让机器给考卷的主观题评分。以语文考试的作文为例,在阅卷之前老师们先置一套通用的打分标准,包括字迹工整度、词汇丰富性、句子通顺度、文采、篇章结构、立意等多个层次,研究人员让机器来学习这套方案后进行阅卷。这每一项标准背后都需要精密复杂的技术支持,比如手写识别、主题模型、人工神经网络等。
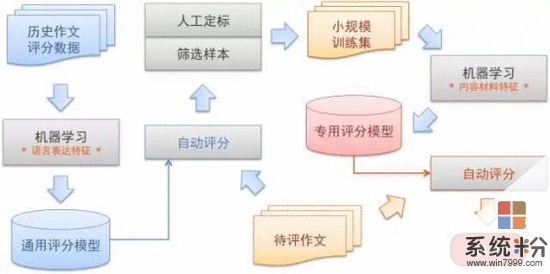
目前,科大讯飞的全学科阅卷技术在四六级、部分省份的高考、中考等大规模考试中进行了试点验证,验证结果表明计算机评分结果已经达到了现场阅卷老师的水平,满足大规模考试的需要。这项技术应用到正式考试中,可以辅助人工阅卷,减少人员投入,降低人工阅卷中疲劳、情绪等因素的影响,进一步提升阅卷效率和准确性。
此前,哈工大讯飞联合实验室曾先后在Google DeepMind阅读理解公开数据测试集、Facebook阅读理解公开数据测试集取得世界最好成绩,本次在SQuAD测试集再获全球最佳,包揽了机器阅读理解权威测试集的“大满贯”。
机器阅读理解技术拥有广阔的应用场景,例如在产品的精准问答、开放域的问答上都会起到有力的支撑作用,讯飞也在不断探索机器阅读理解技术的应用落地。
但对于机器阅读理解的“能理解会思考”的终极目标来说,现在还只是万里长征的开始,对自然语言的更深层次的归纳、总结、推理,一定是未来机器阅读理解不可缺少的部分。
而自2014年以来,科大讯飞就提出了“讯飞超脑”计划,其中的目标之一就是要让机器人考上重点大学。这次获得成绩也是为推进这一计划的努力之一。









