何恺明团队提出Focal Loss,目标检测精度打破现有记录

翻译|AI科技大本营(rgznai100)
参与 | 周翔,尚岩奇
他可谓神童。
2009年,在 IEEE 举办的 CVPR 大会上,还在微软亚研院(MSRA)实习的何恺明的第一篇论文“Single Image Haze Removal Using Dark Channel Prior”艳惊四座,获最佳论文,这是第一次完全由中国人组成的团队获得该奖项。
2016年,何恺明所在团队的另一篇论文“Deep Residual Learning for Image Recognition”再获 CVPR 最佳论文奖。
同年 8 月,这位 2003 年的广东省理科高考状元离开 MSRA,加入 FAIR(Facebook AI Research),担任科学家。
当然,除了这些不凡的履历之外,何恺明还是 Faster R-CNN 和 Mask R-CNN 的主要贡献者。有媒体评价称,何恺明用自己的行动打破了外界认为高考状元高分低能的偏见。(当然,本营长还是羡慕高考状元滴,木有偏见)
近日,AI科技大本营在 arXiv 上发现了何恺明所在 FAIR 团队的最新力作:“Focal Loss for Dense Object Detection(用于密集对象检测的 Focal Loss 函数)”。
这篇论文到底有什么重大意义呢?
清华大学孔涛博士在知乎上这么写道:
目标的检测和定位中一个很困难的问题是,如何从数以万计的候选窗口中挑选包含目标物的物体。只有候选窗口足够多,才能保证模型的 Recall。
目前,目标检测框架主要有两种:
一种是 one-stage ,例如 YOLO、SSD 等,这一类方法速度很快,但识别精度没有 two-stage 的高,其中一个很重要的原因是,利用一个分类器很难既把负样本抑制掉,又把目标分类好。
另外一种目标检测框架是 two-stage ,以 Faster RCNN 为代表,这一类方法识别准确度和定位精度都很高,但存在着计算效率低,资源占用大的问题。
Focal Loss 从优化函数的角度上来解决这个问题,实验结果非常 solid,很赞的工作。
也就是说,one-stage 检测器更快更简单,但是准确度不高。two-stage 检测器准确度高,但太费资源。
鱼和熊掌,不可兼得。
如果想要两者兼得,如何实现?
何凯明团队提出了用 Focal Loss 函数来训练。
因为,他在训练过程中发现,类别失衡是影响 one-stage 检测器准确度的主要原因。那么,如果能将“类别失衡”这个因素解决掉,one-stage 不就能达到比较高的识别精度了吗?
于是在研究中,何凯明团队采用 Focal Loss 函数来消除“类别失衡”这个主要障碍。
结果怎样呢?
为了评估该损失的有效性,该团队设计并训练了一个简单的密集目标检测器—RetinaNet。试验结果证明,当使用 Focal Loss 训练时,RetinaNet 不仅能赶上 one-stage 检测器的检测速度,而且还在准确度上超越了当前所有最先进的 two-stage 检测器。
可谓鱼和熊掌兼得之。
具体怎么实现呢?以下是该论文简介,Enjoy!详细信息,请查阅原文链接。

摘要
目前准确度最高的目标检测器采用的是一种常在 R-CNN 中使用的 two-stage 方法,这种方法将分类器应用于一个由候选目标位置组成的稀疏样本集。相反,one-stage 检测器则应用于一个由可能目标位置组成的规则密集样本集,而且更快更简单,但是准确度却落后于 two-stage 检测器。在本文中,我们探讨了造成这种现象的原因。
我们发现,在训练密集目标检测器的过程中出现的严重的 foreground-background 类别失衡,是造成这种现象的主要成因。我们解决这种类别失衡(class imbalance)的方案是,重塑标准交叉熵损失,使其减少分类清晰的样本的损失的权重。Focal Loss 将训练集中在一个稀疏的困难样本集上,并防止大量简单负样本在训练的过程中淹没检测器。为了评估该损失的有效性,我们设计并训练了一个简单的密集目标检测器—RetinaNet。试验结果证明,当使用 Focal Loss训练时,RetinaNet 不仅能赶上 one-stage 检测器的检测速度,而且还在准确度上超越了当前所有最先进的 two-stage 检测器。
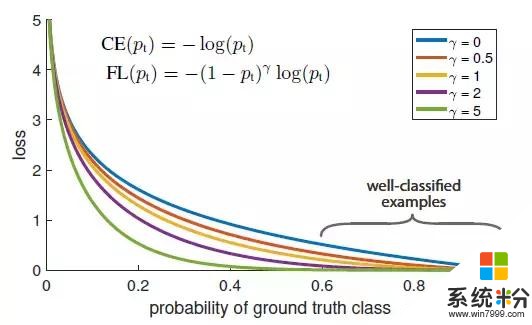
损失函数 Focal Loss(焦点损失)
图1:我们提出了一种新的损失函数 Focal Loss(焦点损失),这个损失函数在标准的交叉熵标准上添加了一个因子 (1- pt) γ 。设定 γ > 0 可以减小分类清晰的样本的相对损失(pt > .5),使模型更加集中于困难的错误分类的样本。试验证明,在存在大量简单背景样本(background example)的情况下,我们提出的 Focal Loss 函数可以训练出准确度很高的密集对象检测器。
1 简介
当前最优秀的目标检测器使用的都是一种由 proposal 驱动的 two-stage 机制。和在 R-CNN 框架中一样,第一个阶段生成一个候选目标位置组成的稀疏样本集,第二个阶段使用一个卷积神经网络将各候选位置归至 foreground 类别或 background 类别。随着一些列的进步,这个 two-stage 框架可以在难度极高的 COCO benchmark 上一直保持很高的准确度。
既然 two-stage 检测器的结果这么好,那么一个很自然的问题是:简单的 one-stage 检测器是否也能实现类似的准确度? one-stage 检测器主要应用在一个由目标位置(object locations)、尺度(scales)和长宽比(aspect ration)组成的规则密集样本集上。最近对 one-stage 检测器(如 YOLO 和 SSD)进行的试验都得出了优秀的结果,相比最优秀的 two-stage 方法,得出的检测器检测速度更快,而且能实现 10%- 40% 的准确度。
本文进一步提高了 one-stage 检测器的性能:我们设计出了一个 one-stage 目标检测器,并首次达到了更复杂的 two-stage 检测器所能实现的最高 COCO 平均精度,例如(特征金字塔网络,Feature Pyramid Network ,FPN)或 Faster R-CNN 的 Mask R-CNN 变体。我们发现训练过程中的类别失衡是阻碍单阶段检测器实现这个结果的主要障碍,并提出了一种新的损失函数来消除这个障碍。
通过两阶段的级联(cascade)和采样的启发(sampling heuristics),我们解决了像 R-CNN 检测器的类别失衡问题。候选阶段(如Selective Search、EdgeBoxes 、DeepMask 和 RPN)可以快速地将候选目标位置的数目缩至更小(例如 1000-2000),过滤掉大多数背景样本。在第二个分类阶段中,应用抽样启发法(sampling heuristics),例如一个固定的前景样本背景样本比(1:3),或者在线困难样本挖掘法(online hard example mining),在 foreground 样本和 background 样本之间维持可控的平衡。
相反,one-stage 检测器则必须处理一个由图像中规则分布的候选目标位置组成的大样本集。在实践中,目标位置的总数目通常可达 10 万左右,并且密集覆盖空间位置、尺度和长宽比。虽然还可以应用类似的抽样启发法,但是这些方法可能会失效,如果容易分类的背景样本仍然支配训练过程话。这种失效是目标识别中的一个典型问题,通常使用 bootstrapping 或困难样本挖掘来解决。
在本文中,我们提出了一个新的损失函数,它可以替代以往用于解决类别失衡问题的方法。这个损失函数是一个动态缩放的交叉熵损失函数,随着正确分类的置信度增加,函数中的比例因子缩减至零,见图1。在训练过程中,这个比例因子可以自动地减小简单样本的影响,并快速地将模型集中在困难样本上。
试验证明,Focal Loss 函数可以使我们训练出准确度很高的 one-stage 检测器,并且在性能上超越使用抽样启发法或困难样本挖掘法等以往优秀方法训练出的 one-stage 检测器。最后,我们发现 Focal Loss 函数的确切形式并不重要,并且证明了其他实例(instantiations)也可以实现类似的结果。
为了证明这个 Focal Loss 函数的有效性,我们设计了一个简单的 one-stage 目标检测器—RetinaNet,它会对输入图像中目标位置进行密集抽样。这个检测器有一个高效的 in-network 特征金字塔(feature pyramid),并使用了锚点盒(anchor box)。我们在设计它时借鉴了很多种想法。RetinaNet 的检测既高效又准确。我们最好的模型基于 ResNet-101- FPN 骨干网,在 5fps 的运行速度下,我们在 COCO test-dev 上取得了 39.1 AP 的成绩,如图2 所示,超过目前公开的单一模型在 one-stage 和 two-stage 检测器上取得的最好成绩。
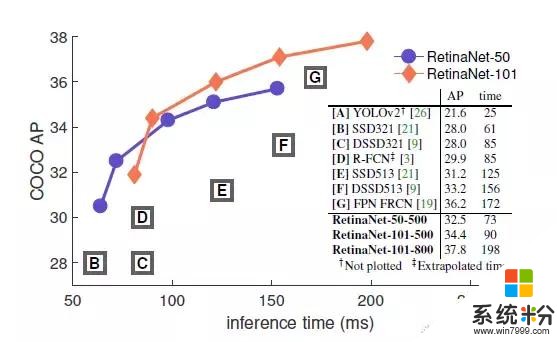
图2:横坐标是检测器在COCO test-dev 上的检测速度(ms),纵坐标是准确度(AP: av
在 Focal Loss 的作用下,我们简单的 one-stage RetinaNet 检测器打败了先前所有的 one-stage 检测器和 two-stage 检测器,包括目前成绩最好的 Faster R-CNN系统。我们在图 2 中按 5 scales(400-800 像素)分别用蓝色圆圈和橙色菱形表示了 ResNet-50-FPN 和 ResNet-101-FPN 的 RetinaNet 变体。忽略准确度较低的情况(AP < 25),RetinaNet 的表现优于当前所有的检测器,训练时间更长时的检测器达到了 39.1 AP 的成绩。
2 Focal Loss
首先,我们介绍下二进制分类(binary classification)的交叉熵(CE)损失开:
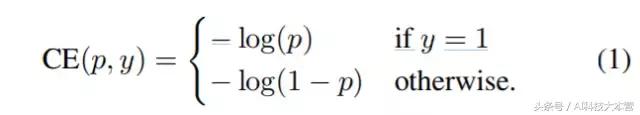
公式1中,y∈{±1} 指定了 ground-truth class,p∈[0,1] 是模型对于标签为 y = 1 的类的估计概率。为了方便起见,我们定义 pt 为:
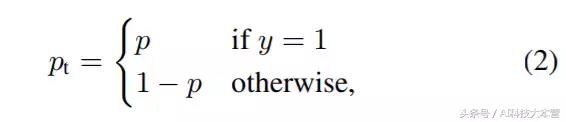
公式2可以转写称:
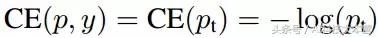
解决 class imbalance 的常见方法是分别为 class 1 和 class -1 引入加权因子 α∈[0; 1]、1-α。 α-balanced 的CE损耗可写为:
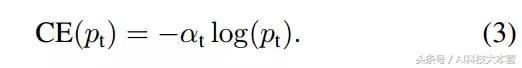
更正式地,我们建议为交叉熵损失增加一个调节因子(1 - pt)γ,其中 γ≥0。于是 Focal Loss 可定义为:
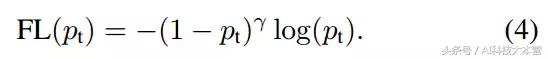
以下是我们在实践中使用的 Focal Loss:
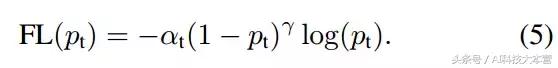
3 RetinaNet 检测器
RetinaNet 是由一个骨干网络和两个特定任务子网组成的单一网络。骨感网络负责在整个输入图像上计算卷积特征图,并且是一个现成的我卷积网络。 第一个子网在骨干网络的输出上执行卷积对象分类;第二个子网执行卷积边界框回归。如下图所示。
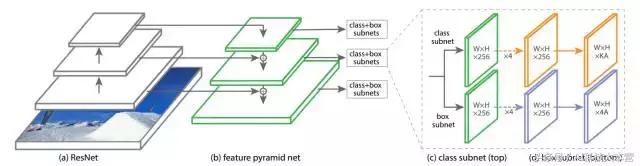
图3:one-stage RetinaNet 网络结构
4 训练
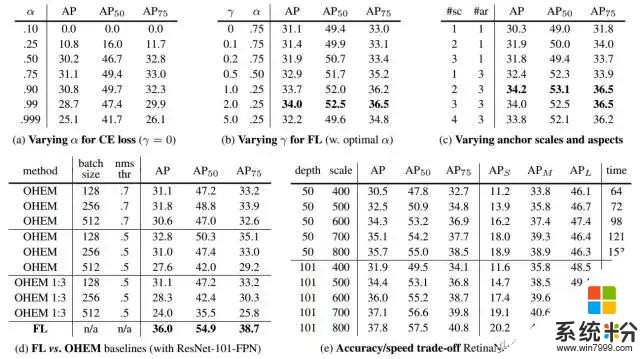
表1: RetinaNet 和 Focal Loss 剥离试验(ablation experi
5 试验
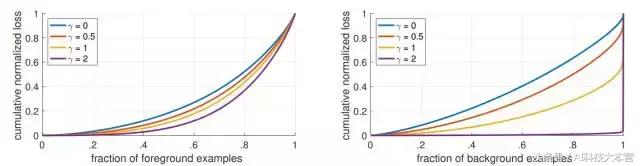
图4:收敛模型的不同 γ 值的正、负样本的归一化损失的累积分布函数。
改变 γ 对于正样本的损失分布的影响很小。 然而,对于负样本来说,大幅增加 γ 会将损失集中在困难的样本上,而不是容易的负样本上。
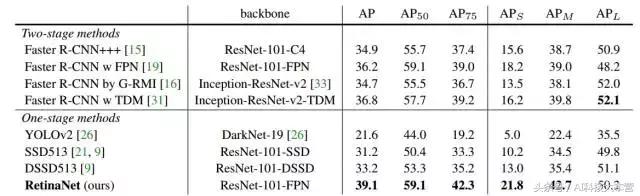
表2:目标检测单模型结果(边界框AP)VS COCO test-dev 最先进的方法
6 结论
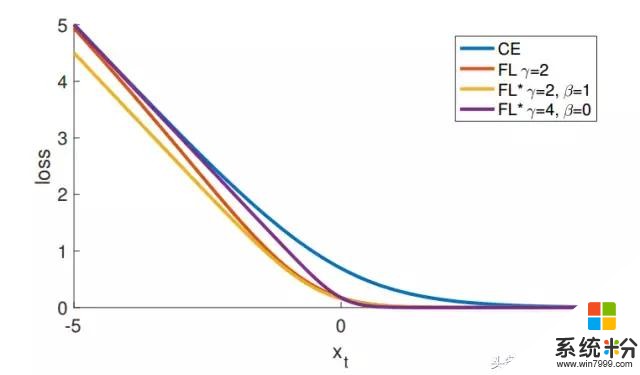
图5: 作为 xt = yx 的函数,Focal Loss 变体与交叉熵相比较。
原来的 FL(Focal Loss)和替代变体 FL* 都减少了较好分类样本的相对损失(xt> 0)。
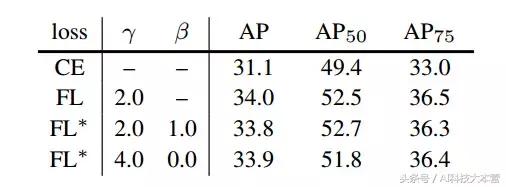
表3:FL 和 FL* VS CE(交叉熵) 的结果
论文地址
https://arxiv.org/abs/1708.02002









