CCAI|如何能既便宜又快速地获取大数据?这位微软研究员设计了两个模型,帮你省钱省时间

美国微软雷德蒙研究院首席研究员周登勇
文/CSDN贾维娣
7 月 22 - 23 日,在中国科学技术协会、中国科学院的指导下,由中国人工智能学会、阿里巴巴集团 & 蚂蚁金服主办,CSDN、中国科学院自动化研究所承办的 2017 中国人工智能大会(CCAI 2017)在杭州国际会议中心盛大召开。
大会第二天上午,美国微软雷德蒙研究院首席研究员周登勇(Denny Zhou)发表了《众包中的统计推断与激励机制》主题报告,从“为什么众包”、“众包的挑战”、“统计推断”、“激励机制”着手,结合多个生动形象的案例,具体总结了微软雷德蒙研究院过去几年在众包研究与工程上的进展。
周登勇博士表示,在可以预见的将来,机器智能完全代替人的智能几乎没有任何可能,我们应该是让人与机器各施所长互相补充。数据标注是一个比较简单的人机系统,但这里面包含的技术已经相当有挑战性。如果我们要建立更复杂的人机智能系统解决更大的问题,会有更多的新的困难需要克服。
以下为演讲实录,在不违背原意的情况下进行了删减和调整。
大家好,我今天要讲的是众包。具体来说,我将讨论如何通过众包获取高质量的数据标签。为开发一个机器学习的智能系统,我们第一步要做的事情就是获得高质量的带标签的数据。
为什么需要众包?
通过众包我们很容易拿到大量的带有标签的数据。众包有两个优点:
速度快。一个商业众包平台或许有上百万甚至几百万的数据标记人员。
便宜。在亚马逊众包平台标注一个图像数据通常都不到一美分。
所以,通过众包很可以以很少的花费在短时间内获得大量的带标签的数据。在机器学习里大家经常会说的一句话:更多的数据会打败一个聪明的算法。
如何提高众包数据的质量
众包存在的问题
可是,通过众包获取的数据标签质量或许不高。 只要原因如下:
专业技能。因为众包人员可能没有标记你的数据所需的技能。
动机。众包人员没有动力好好的把这个数据标记好。
如果使用低质量的数据去训练一个机器学习模型,不管使用什么高级的算法,都可能无济于事。
众包中的统计推断
在一定程度上,统计推断可以帮助我们从低质量的通过众包获得的数据标签中提炼出正确的标签。

让我们先看一个假想的例子。比如这个橙子与橘子的分类问题。每幅图像同时有几个人标注,不同的人或给出不同的答案。但是,当把不同的答案设法结合起来,我们或许能知道正确的答案是什么。这也通常叫做群体智慧。
怎么结合不同人的答案呢?最简单的办法就是采用投票的方式。也就是说,哪一类标签拿到的投票数是最多的,我们就认为这个图像属于这一类。
我们在做一个问题的时候,总应该想一想,我们的做法合理吗? 还有改进的空间吗? 在我我们的这个问题上, 投票意味着什么呢?投票意味者所有人的水平都是一样的。也就是说, 大家都一样好。
显然这在现实上不太可能。更可能的是大家的的水平参差不齐。但是,因为没有正确的答案,我们不能立即知道谁的水平更高。而且,即使我们知道正确的标签,也很难比较两个人的水平的高低,因为不同的问题难度会很不一样。一个答对了10道容易问题的人与答对10道难题的人水平或很不一样。所以,为了推断出正确的数据标签,我们需要把把以上讨论的关于人的水平与问题难度的直观想法转化成一个数学模型。
接下来讲我们的方案。在这之前,让我先引进一些数学符号。让我们把收集来的众包数据表示成一个矩阵这个矩阵的每一行对应一个数据标记员,每一列对应着我们需要标记的对象。数据表示第个人对第个数据做出的标记。真实的标签是不知道的。我们需要解决的问题就是如何从推断出。
极小极大熵原理

我们的解决方案叫极小极大熵原理,可以分成两块来解读:
优化的对象;
优化的约束条件。

我们先看约束条件。第一个约束条件是针对每个数据标记员工,第二个约束条件是针对每个需要标记的对象。下面我将解释这两个约束。我们会看到第一个约束条件对应着人的水平,第二个约束条件对应着问题的难度。
刚才说过,每一个数据标记人员所标记的数据对应着矩阵的一行。我们的约束做这么一件简单的事情:计数。我们数一下有多少类别为的对象被误标为。约束方程的右边是观察到的误标总数,左侧则是对应的期望值。一个人误标越多,水平就越低。
构造这个约束方程的原理可以理解如下。

假设我们有一枚硬币,我们希望知道这个硬币是正面的概率是多大。假设我们把这个硬币不断的丢10次,有6次是正面。那么正面的概率是多少呢?一般我们会说正面的概率是60%。为什么呢?我们可以这样想。假设正面的概率是p,我们会认定10 * p = 6,右边是观察到的正面数,左边是期望值。解这个方程,我们就可以得到p = 0.6。
类似的,我们对需要标记的每一个对象也有这样的计数。当我们知道真实的类别的话,我们会知道有多少人标错了。标错的人越多,这个问题就越难。我们方程的右侧统计一下到底有多少人标错了,左边则是是它的期望值。

约束条件已经讲完了,现在回到为什么采用这样一种目标函数。首先我们把极小化放在一边,先看极大化。也就是极大熵。我们用一个数学模型解释观察到的数据的时候,尽量用一个光滑的模型去拟合数据。类似地,当我们用一个概率分布解释观察到的数据的时候,会让分布尽可能平坦。这就是极大熵原理的直观解释。为进一步推断真实的标签,我们极小化最大的熵。熵在直觉的意义上意味着不确定性。极小化最大的熵意味着极小化不确定性,也就是我们认为数据标记员都在尽力做好他们的工作。如果他们只是提供随机的标签,那么就没有任何办法去恢复真实的标签。

解决极小极大的优化问题的时候,我们需要把它变成一个对偶问题,叫拉格朗日对偶。拉格朗日乘子与可以分别解释成人的水平与问题的难度。我们初步设想是把每个人的能力与问题的难度给刻画出来,但是并没有假设这个模型是什么样的。当我们同时引进约束条件和极大极小化熵,这个模型就自动推出来了。要注意到这里的拉格朗日乘子是矩阵,与ℓ是类别。非对角线上的元素(与ℓ不相等)表示怎么把一个类别的标记对象,混淆成另外一个类别。对角线线上的数字 (与ℓ相等)则表示标记的精度。

我们现在讨论以上模型的另外一种解释方案,这个方式跟心理学有关。这是数学心理学家在60年代提出的想法,称之为客观性测量原理。比如说我们测量桌子长度的时候,假设一张桌子是另外一张的两倍长。不管我们用什么尺子去测量,这个永远是另外一个的两倍,这叫测量的客观性。在众包里面我们要做的测量是每个人的水平以及每个问题的难度。我们也要保证测量的方式足够客观。这意味着两个人的水平的相对比较应该与用来测量人的水平的具体的问题是独立的。把这个客观性原理用数学刻划出来的话,可以证明我们提出的众包模型是唯一符合客观性原理的模型。
我们的众包模型很容易拓展到分级的数据上面去。比如说我们在做搜索的时候,数据标签通常是“完美”、“优秀”、“好“,“公平”,或者是“不好“。一个人可能把一个“完美”与“优秀”有混淆,但是不太可能把“完美“与”不好“混淆。当我们把这样的直觉变成数学的描述,就构造了下面的约束条件。

在第一个方程里面,我们检查数据标记员的标签是不是比某一个标签c大,而且真实的是不是也比这个大,然后让经验观察的次数与它的期望值相等。其他的方程可以类似解释。
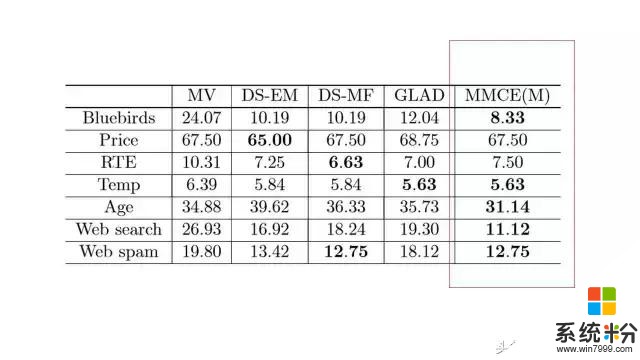
以上图表是在众包数据集上的实验结果,每一个数字表示了错误率,我们方法的结果在最后一列。经验结果表明我们的方法确实能产生比较好的性能,但是除了有一个数据集Price。在这个数据集里面,包含的是UCI本科学生对产品价格的估计。这个数据有系统性的偏差。学生们把价格普遍低估。这或许并不令人惊讶。
我们也考虑了预算最优的众包问题。在这个问题里面,我们需要在每一步考虑两个问题:哪一个数据需要更多的标记;以及让谁来标注。在我们的方案里面,这个问题通过马尔科夫决策理论解决。
众包激励措施
我要讨论的下一个问题,就是在做众包的时候怎么付钱。我之所以想做这个问题,是因为我对前面的解决方案并不是很满意。尽管极小极大熵原理相对投票以及其他的方法准确率有很大的提高,但是我希望能有更大的提高。
如果我们想把一个问题的解决方案做出本质的提升,我们往往需要跳出原来的解决思路。我们注意到众包远不只是机器学习的问题。众包是个商业行为。众包人员给我们标记数据的时候,我们需要付钱。如何付钱有可能是整个众包数据质量的关键所在。
一个常用的付钱策略就是通过随机抽查的答案的质量来决定付多少钱。具体操作起来,就是把一些我们已经知道答案的问题随机分布在众包任务里面(下图里面红方框表示已经知道标签的图像)。这些知道答案的问题通常称为金色标准问题。数据标记人员不知道哪些问题是金色标准问题。我们根据一个数据标记人员在金色标准问题上的表现来决定付多少钱。

我们可以先想想怎么付这个钱。比如说:
报酬正比于精度。假设我们有100个图像需要标记,有4个图像我们是知道答案的,但是数据标记员不知道哪4个图案你是知道答案的,假设每个标记是两分钱,有一个人答对了一个,正确率就是四分之一,报酬是4 x 2 x ¼ = 2。
超过一定精度才给钱。比如说精度超过了60%,我们就给钱,低于60%就不给钱。上面那个例子里面就不给钱。
我们能否有更好的付钱方式呢?
允许跳过没有把握的问题
付钱问题实际上有利益冲突在里面:数据标记人员希望用最小的努力拿到最大化的收益;雇主希望花最少的钱让他们出最好的活。
一个好的付钱机制需要协调这个矛盾,达到双赢。为解决这个问题我们需要用数学刻划两个概念,一个是“真实性“(truthful)准则,一个是”没有免费的午餐“(no-free-lunch)准则。
“真实性”准则假设每个人在回答问题的时候会有一个信心(confidence)值,在0到1之间。如果他的信心值不到一定程度,他就不应该回答这个问题。反之,如果他的信心值足够大,就应该回答这个问题。我们要设置一个付钱的机制,使得给你标记数据的人,能与你的想法互相配合。否则,这只会是我们自己的一厢情愿。

我举一个例子解释一下真实性准则。比如说我们让人去标记一下这个狗是什么种类。假设我们设定了一个信心值是50% (注意到随机猜的正确率是1/3, 小于50%)。第一个人认为自己只有30%的几率认为会达到一个正确的答案。由于30% 小于给定的50%, 他就应该如实选择“我不确定“。第二个人觉得自己有90%的几率答案会是对的。 由于90% 大于50%,这种情况下她应该回答这个问题。
“没有免费的午餐“准则决定在什么情况不付钱: 如果一个雇员的所有没有跳过去的问题的回答都是错的,就不付钱。 这样的雇员没有给我们带来任何价值。
现在的问题是我们要找到一个付钱的方式,同时满足“真实性”和“没有免费的午餐“,也就是说,使得雇员心甘情愿做你想做的事情,而且没做好的话就拿不到钱。一般来说,付钱的方式还不能太复杂,最好用简单的加法和乘法就能解决。

这个是我们的付钱方式,一种乘法机制,或者叫做“翻倍或归零”: 如果一个人犯了任何错误的话,就没有钱了,否则的话拿到的收入采用乘积的方式往上增长。
归零或让人会觉得很残酷。这里需要解释几件事:
在做数据标记的时候,雇员可以跳过没有把握的问题,他的收入不受影响。
众包中我们往往会把巨大的数据标记任务分解成很多小任务。每个小任务几分钟之内就可以完成。如果没有拿到钱的话,也是几分钟之内没有拿到钱。一但没有拿到钱,众包人员知道自己做错事情了,会从中吸取教训,在下一轮里面做的更好。
我们可以给每个雇员固定的收入,只是用这个方式计算额外收入或者奖金,就像你在公司工作的情况下,你的收入会分成好两部分,基本工资与奖金。
让我用例子解释实际上如何使用这个付钱机制。在众包之前需要很清楚地告诉雇员钱是怎么付的。回到图像标记这个问题上,我们或许给定这样的付钱规则: 刚开始是一分钱,对每个正确的答案拿的钱就翻倍,如果有任何的答案是错的情况下,钱就归零了,如果跳过问题的话,不影响付钱。

比如第一个人前两个答案是对的,收入等于1 x 2 x 2。后三个答案跳过去了。跳过去的时候收入不受影响(等价于乘1),所以总共拿到4分钱;
第二个人两个答案是对的,两个没有回答,一个是错的。在这个情况下收入是零,因为错了一道题。
我们在亚马逊众包平台上做了实验,发现使用这种付钱方式能够把数据标注的错误率甚至可以降低60%。有没有其他的付钱方式同时满足“真实性”和“没有免费的午餐“这两个准则呢?令人惊奇的是,理论上可以证明,我们的付钱方式是唯一的可以满足这两个准则的付钱方式。 我们还有另外一个定理,假设有一个人所有的问题都跳过去,我们的付钱方式也是唯一的能够给这些人付最少钱的方式。可能有人会好奇,为什么这个人什么问题都不回答也给钱?理论上我们证明了一个不可能性定理:如果一个人什么问题都不回答就不给钱的话,那样的付钱机制一定不能满足“真实性”。
允许选择一个子集(subset selection)

我们可以把刚才的方案做进一步的延伸。在许多情况下,雇员不知道真实的答案是什么,但是知道哪些答案是错的。比如这个狗的问题,他确信最后一个答案肯定是错的,但是不肯定正确的答案到底是第一个还是第二个。于是,他就把前两个答案都选上。这信息对我们来说是有用的,因为他排除了第三个答案。如果他把所有答案都选上了,相当于他没有回答这个问题或者说把这个问题跳过去了。

在这种情况下,我们有一种类似的付钱方式。我们现在有一个表示子集的大小,全部答对的情况下拿到的总收入是 A,选择的子集越大的话,拿到的钱越少。如果某这个选择的子集没有包含正确的答案,就不给钱。在这里我们类似地定义“真实性”和“没有免费的午餐“这两个准则,并获得类似的定理。

众包数据标记的时候如果你没有精力抽查,你可以再雇另外一批人帮你抽查结果,类似于每年你去开机器学习大会,你会发现大会主席不可能评价每篇论文该收还是不收,会雇佣一些论文审查人员审查论文。写论文的作者在这里相当于提供数据标签的人,论文审查人员相当于这里审查别人答案的人,大会主席就是你自己。在这种情况下我们也需要设计一个不同的付钱方式。
谢谢大家!









