已解决决策树方法的主要原理是什么?
提问者:sopnba | 浏览次 | 提问时间:2017-01-02 | 回答数量:1
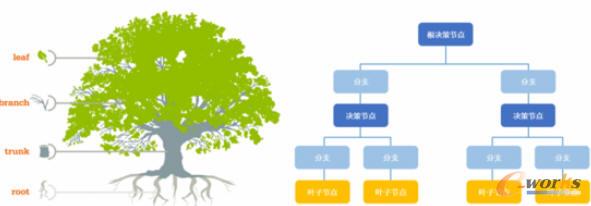 决策树故名思意是用于基于条件来做决策的,而它运行的逻辑相比一些复杂的算法更容易理解,只需按条件遍历树就可以了,需要花点心思的是理解如何建立决策树。举个例子,就好像女儿回家,做妈妈的...
决策树故名思意是用于基于条件来做决策的,而它运行的逻辑相比一些复杂的算法更容易理解,只需按条件遍历树就可以了,需要花点心思的是理解如何建立决策树。举个例子,就好像女儿回家,做妈妈的...
提问者:sopnba | 浏览次 | 提问时间:2017-01-02 | 回答数量:1
决策树故名思意是用于基于条件来做决策的,而它运行的逻辑相比一些复杂的算法更容易理解,只需按条件遍历树就可以了,需要花点心思的是理解如何建立决策树。举个例子,就好像女儿回家,做妈妈的...

伪装者crazy
回答数:191 | 被采纳数:132

今天给大家带来主板供电不足到底是什么原因,主板供电不足用什么方法有解决,让您轻松解决问题。 在有些时候我们的主板供电不足了,这该怎么办呢?下面就由学习啦小编来为你们简单的介绍主...
今天给大家带来雨林木风win7系统安装要清理什么东西,win7系统的清理方法是什么,,让您轻松解决问题。 如今绝大多数的用户都选择使用Win7系统,它拥有很多新功能、新特...

不少用户发现自己所用的Firefox浏览器有崩溃的状况,但是又找不出原因,win 7系统看似也没问题,因此很多人都一头雾水,其实大家再想想,有可能是Flash 11.3的...
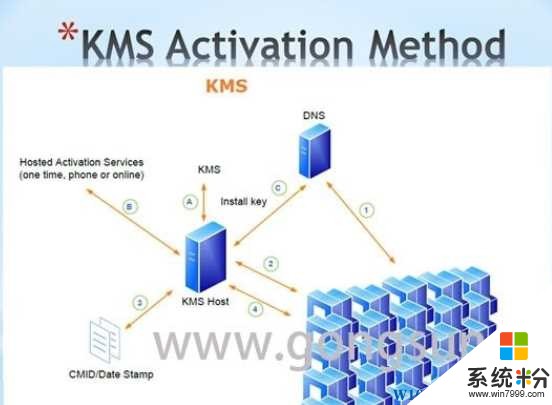
目前来说,除了使用已经激活的Win7/Win8.1升级Win10,或是你有正版的Win7/win8序列号,那么你可以完美激活Win10,否则你就需要使用KMS激活(Win10激活工...