微软目前在语音识别领域应用深度学习的历史性突破

在几十年的历程中,有非常多优秀的公司在语音和语言领域进行了不懈地探索,终于在今天,达到了和人一样精准的语音识别,这是非常了不起的历史性突破。语言是人类特有的交流工具。今天,计算机可以在假定有足够计算资源的情况下,非常准确地识别你和我讲的每一个字,这是一个非常大的历史性突破,也是人工智能在感知上的一个重大里程碑。
Switchboard是整个工业界常用的一个测试数据集。很多新的领域或新的方法错误率基本都在20%左右徘徊。大规模标杆性的进展是IBM Watson,他们的错误率在5%到6%之间,而人的水平基本上也在5%到6%之间。过去20年,在这个标杆的数据集上,有很多公司都在不懈努力,如今的成果其实并不是一家公司所做的工作,而是整个业界一起努力的结果。
各种各样的神经网络学习方法其实都大同小异,基本上是通过梯度下降法(Gradient Descent)找到最佳的参数,通过深度学习表达出最优的模型,以及大量的GPU、足够的计算资源来调整参数。所以神经网络对计算机语音识别的贡献不可低估。早在90年代初期就有很多语音识别的研究是利用神经网络在做,但效果并不好。因为,第一,数据资源不够多;第二,训练层数少。而由于没有计算资源、数据有限,所以神经网络一直被隐马尔可夫模型(Hidden Markov Model)压制着,无法翻身。

深度学习翻身的最主要原因就是层数的增加,并且和隐马尔可夫模型结合。在这方面微软研究院也走在业界的前端。深度学习还有一个特别好的方法,就是特别适合把不同的特征整合起来,就是特征融合(Feature Fusion)。
如果在噪音很高的情况下可以把特征参数增强,再加上与环境噪音有关的东西,通过深度学习就可以学出很好的结果。如果是远长的语音识别,有很多不同的回音,那也没关系,把回音作为特征可以增强特征。如果要训练一个模型来识别所有人的语音,那也没有关系,可以加上与说话人有关的特征。所以神经网络厉害的地方在于,不需要懂具体是怎么回事,只要有足够的计算资源、数据,都能学出来。
我们的神经网络系统目前有好几种不同的类型,最常见的是借用计算机视觉CNN(Convolution Neural Net,卷积神经网络)可以把不同变化位置的东西变得更加鲁棒。你可以把计算机视觉整套方法用到语音上,把语音看成图像,频谱从时间和频率走,通过CNN你可以做得非常优秀。另外一个是RNN(Recurrent Neural Networks,递归神经网络), 它可以为时间变化特征建模,也就是说你可以将隐藏层反馈回来做为输入送回去。这两种神经网络的模型结合起来,造就了微软历史性的突破。
微软语音识别的总结基本上可以用下图来表示。
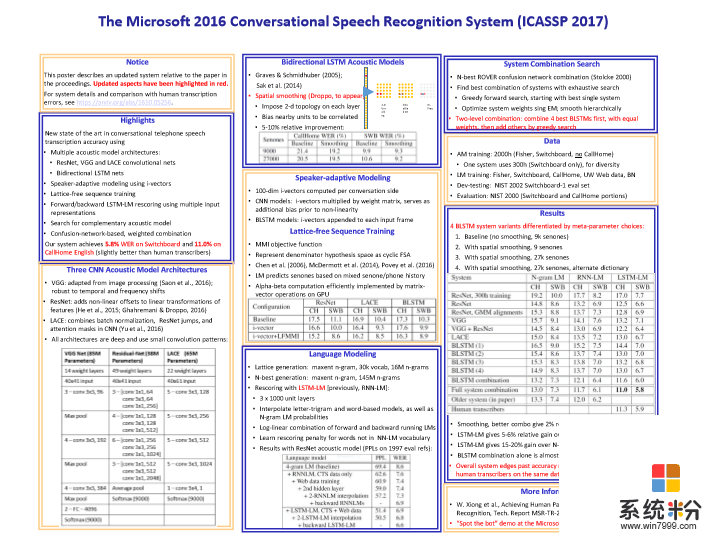
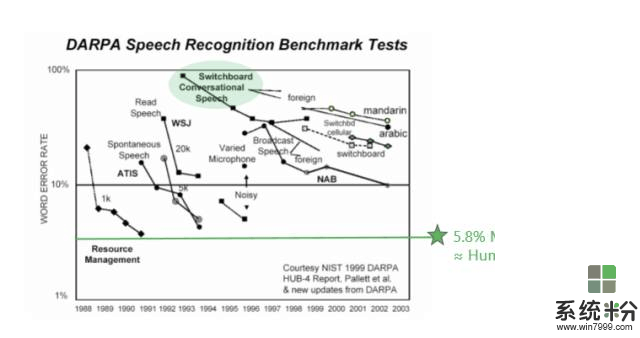
下图是业界在过去几十年里面错误率下降的指标,可以看到5.8%是微软在去年达到的水平。Switchboard的错误率从80%左右一直到5.8%左右,是用了什么方法呢?我们是怎么达到这个目标呢?
大家知道语音识别有两个主要的部分,一个是语音模型,一个是语言模型。

语音模型我们基本上用了6个不同的神经网络,并行的同时识别。很有效的一个方法是微软亚洲研究院在计算机视觉方面发明的ResNet(残差网络),它是CNN的一个变种。当然,我们也用了RNN。可以看出,这6个不同的神经网络在并行工作,随后我们再把它们有机地结合起来。在此基础之上再用4个神经网络做语言模型,然后重新整合。所以基本上是10个神经网络在同时工作,这就造就了我们历史性的突破。









