170亿参数加持,微软发布史上最大Transformer模型T-NLG

作者 | Corby Rosset
译者 | 刘畅 责编 | Just
出品 | AI科技大本营(ID:rgznai100)
BERT和GPT-2之类的深度学习语言模型(language model, LM)有数十亿的参数,互联网上几乎所有的文本都已经参与了该模型的训练,它们提升了几乎所有自然语言处理(NLP)任务的技术水平,包括问题解答、对话机器人和文档理解等。
更好的自然语言生成模型可以在多种应用程序中实现自如的转化,例如协助作者撰写内容,汇总一长段文本来节省时间,或改善自动客服助理的用户体验。
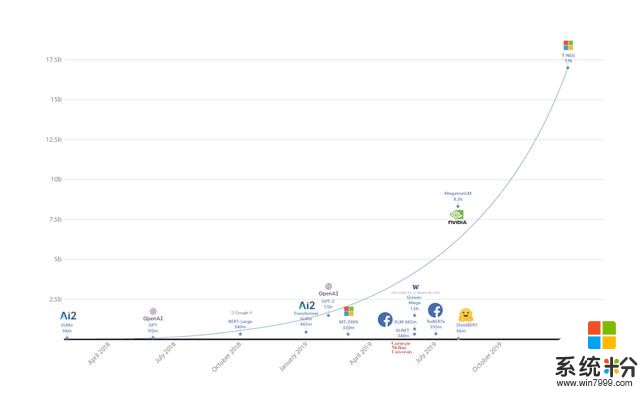
基于使用更大自然语言模型可以带来更好结果的趋势,微软推出了Turing自然语言生成(T-NLG)模型,这是有史以来规模最大的模型,其参数有170亿,在各种语言模型任务的基准上均优于最新技术,并且在应用于许多实际任务(包括概括和问题解答)时也很出色。
这项工作得益于在DeepSpeed库(与PyTorch兼容)的ZeRO优化器方面的突破。
我们正在向学术界的一小部分用户发布T-NLG的演示视频,包括生成自由格式,问题解答和概要功能,以进行初步测试和反馈。

T-NLG:大型生成语言模型的优势
T-NLG是一个基于Transformer的生成语言模型,这意味着它可以生成单词来完成开放式的文本任务。除了补充未完成的句子外,它还可以生成问题的答案和文档的摘要。
T-NLG之类的生成模型对于NLP任务很重要,因为我们的目标是在任何情况下都尽可能与人类直接,准确和流畅地问答。以前,问题解答和概要系统是依赖于从文档中提取现有内容,把这些内容用作备用答案或摘要,但它们通常看起来不自然或不连贯。借助T-NLG模型,就可以很自然的总结或回答有关个人文档或电子邮件主题的问题。
我们已经观察到,模型越大,预训练数据需要越多样化和全面,在泛华到其它任务时也会表现得更好。因此,我们认为训练大型集中式多任务模型并在众多任务中共享其功能比单独为每个任务训练新模型更为有效。

训练T-NLG:硬件和软件的突破
任何超过13亿参数的模型都无法装入单张GPU(甚至一个具有32GB内存的电脑),因此该模型本身必须在多个GPU之间并行化或分解。我们利用了几项硬件和软件的突破来训练T-NLG:
1.我们利用NVIDIADGX-2硬件设置和InfiniBand连接,使GPU之间的通信比以前更快。
2. 在NVIDIAMegatron-LM框架上,我们使用张量切片技术在四张NVIDIAV100 GPU上分割模型。
3. DeepSpeed with ZeRO库使我们可以降低模型并行度(从16降低到4),将每个节点的批处理大小增加4倍,并将训练时间减少3倍。DeepSpeed可以使用更少的GPU训练更大的模型,从而提高效率,并且仅使用256个NVIDIA GPU就可以实现512 batchsize的训练,而单独使用Megatron-LM则需要1024个NVIDIA GPU。DeepSpeed与PyTorch兼容。
最终的T-NLG模型具有78个Transformer层,其隐藏层的节点大小为4256,并包含28个注意力头。为了使结果可与Megatron-LM相媲美,我们使用了与Megatron-LM相同的超参数对模型进行了预训练,
我们还比较了预训练T-NLG模型在标准语言任务(例如WikiText-103(越低越好)和LAMBADA下一个单词预测准确性(越高越好))上的性能。下表显示,我们在LAMBADA和WikiText-103上都达到了最新的技术水平。Megatron-LM是NVIDIA Megatron模型公开发布的结果。
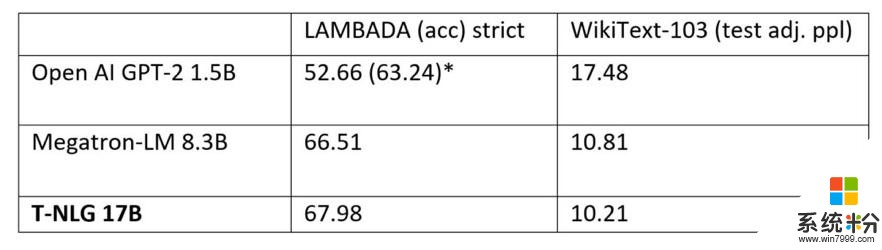
Open AI使用了额外的处理(停用词过滤)以实现比单独实现模型更高的数量。Megatron和T-NLG均未使用这种停用词过滤技术。
下面图1显示了与Megatron-LM相比,T-NLG在验证perplexity方面的表现。
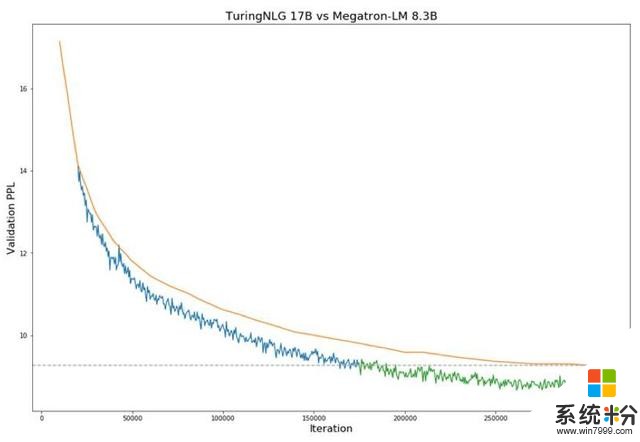
训练期间Megatron-8B参数模型(橙色线)与T-NLG 17B模型在验证困惑度方面的比较(蓝线和绿线)。虚线表示当前SOTA技术模型达到的最低验证损失。图中从蓝色到绿色的过渡表示T-NLG在性能上超过了SOTA水平。

直接问答和Zero-shot提问功能
许多网络搜索用户习惯于在问问题时看到答案直接显示在页面的顶部。这些页面大多数会在其所属段落的上下文中显示一个答案句子。我们的目标是通过直接回答他们的问题来更明确地满足用户的信息需求。例如,大多数搜索引擎在显示全文时会突出显示名称,如“Tristan Prettyman”(请参见下面的示例)

相反,T-NLG将直接用完整的句子回答问题。在Web搜索之外,此功能更为重要,例如,当用户询问有关个人数据的问题(例如电子邮件或Word文档)时,此功能可使AI助手智能响应。
该模型还能够实现“zeroshot”问题解答,这意味着无需上下文即可进行回答。对于下面的示例,没有给出模型的段落,仅给出了问题。在这些情况下,模型依赖于在预训练过程中获得的知识来生成答案。

由于ROUGE分数与真实答案相符,无法反映其他方面,如事实正确性和语法正确性,因此我们要求人工标注者为我们之前的基准系统(类似于CopyNet的LSTM模型)和当前的T NLG模型进行评判。

我们还注意到,较大的预训练模型仅需要较少的其它任务样本就可以很好地学好。
我们最多只有100,000个问题-消息-答案三元组的样本,即使仅进行了数千次训练,我们的模型仍优于训练了多次的LSTM基准模型。
由于收集带标注的监督数据非常昂贵,因此这种观察到的现象会产生实际的业务影响。

不需监督的摘要总结
NLP文献中的摘要有两种类型:提取-从文档中获取少量句子作为摘要的代名词,抽象-用NLG模型像人类一样生成摘要。
T-NLG的目标不是复制现有内容,而是为各种文本文档(如电子邮件,博客文章,Word文档,Excel工作表和PowerPoint演示文稿)编写类似于人类的抽象摘要。
这其中主要的挑战之一是在所有这些情况下都缺乏监督训练数据:因为人类并不总是会明确地总结每种文档类型。T-NLG的强大功能在于,它已经非常了解文本,因此无需太多的监督即可胜过我们之前使用的所有技术。
为了使T-NLG尽可能通用,以汇总不同类型的文本,我们在几乎所有公开可用的汇总数据集中以多任务方式微调了T-NLG模型,总计约有400万个训练样本。我们给出了ROUGE分数,以便与另一种最新的基于Transformer的语言模型(称为PEGASUS)和以前的最新模型进行比较。
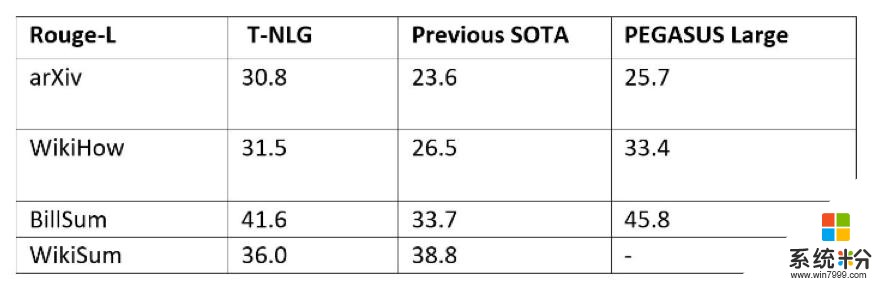
以多任务方式训练T-NLG,同时使用所有数据集对其进行训练。众所周知,由于ROUGE评估在汇总任务方面存在缺陷,因此我们在下面提供了一些公开可用文章的输出摘要,以供比较。


T-NLG未来的应用
T-NLG在自然语言生成方面已经取得了优势,为微软和客户提供了新的机会。
除了通过汇总文档和电子邮件来节省用户时间之外,T-NLG还可以通过为作者提供写作帮助并回答读者可能对文档提出的问题来增强MicrosoftOffice套件的体验。
此外,它为更流畅的聊天机器人和数字助理铺平了道路,因为自然语言生成可以通过与客户交谈来帮助企业进行客户关系管理和销售。
原文:https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
本文为 CSDN 翻译,转载请注明来源出处。









