AI怎么知道人类对话在说什么?微软研究团队告诉你
KYLE WIGGERS 对此做了详细的介绍,将其文章进行了不改变愿意的编译,具体如下。
在一份预先出版的论文中,微软研究团队详细地介绍了他们的工作——为开放领域的对话进行无监督的上下文重写。他们声称,在重写质量和多轮响应生成方面,他们的实验结果已经达到了最新基准。
正如研究人员所解释的那样,对话上下文提出了句子建模中所没有的挑战,比如主题转换、共同引用(像他、她、它、他们这种)、长期依赖。大多数系统解决这些问题的方法是在最后一段话中添加关键字,或者用 AI 模型学习数字表示,但这种方法往往会遇到障碍,比如无法选择正确的关键词、无法处理较长的上下文等。
这时候,就是微软研究团队的方法的用武之地了。它通过对语境信息的考量,重新制定了对话中的最后一句话;这么做是为了生成一个独立的话语,既不存在相互参照,也不依赖过去对话的其它话语。

注:【 图片来源:Microsoft 所有者:Microsoft 】
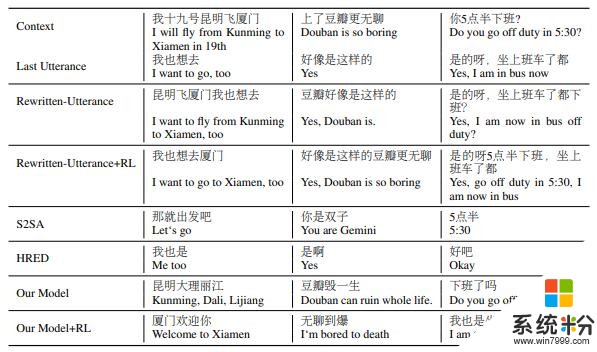
举个例子,如果将“我讨厌喝咖啡。- - 为什么?它挺好喝的啊。”转化成“为什么会讨厌喝咖啡呢?它挺好喝的啊。”,这就借用了“它”和“为什么”。其中,“它”指代的是对话中提到的咖啡,“为什么”则是“为什么讨厌喝咖啡”的缩写形式。
对此,研究人员设计了一个机器学习系统——上下文重写网络(按:context rewriting network, CRN),来实现端到端的流程自动化。这个系统是由一个序列到序列模型组成的,它能够将固定长度的话语映射到固定长度的重写句子上。并且,它还具有一个独立的注意力机制,这个机制能够通过最后话语中的不同单词来帮助它从上下文中复制单词。
那么,这个系统是如何被设计出来的呢?
首先,微软研究团队使用伪数据对模型进行了训练,这些伪数据是通过提取上下文的关键字,将这些关键字插入到原始对话中的最后话语中来生成的。然后,为了让最后的响应影响重写过程,他们利用了强化学习去推动系统朝着目标前进。
注:【 图片来源:Microsoft 所有者:Microsoft 】
在一系列实验中,该团队评估了他们的方法在几种重写质量,多回合响应生成,多回合响应选择以及基于端到端检索的任务上的应用。他们注意到,由于他们的模型更倾向于从上下文中提取更多的单词,因此该模型在强化学习后偶尔会变得不稳定,不过,这也显著地提升了话语的多样性。
微软研究团队认为,他们的工作朝着更易解释和更易控制的上下文建模中迈进了一步。另外,该研究团队还表示,他们的模型可以从嘈杂的语境中提取出重要的关键词,然后将这些关键词插入到最后的话语中,使其不仅变得易于控制和解释,还有助于将信息直接传递到最后的话语中。
注:本文编译自 KYLE WIGGERS 发表在 venturebeat 上的文章。









