参数少一半效果更好,天津大学和微软提出Transformer压缩模型
选自arXiv
作者:Xindian Ma、Peng Zhang、Shuai Zhang、Nan Duan、Yuexian Hou、Dawei Song、Ming Zhou
机器之心编译
参与:王子嘉、一鸣、路
引言
近来,预训练语言模型在很多 NLP 任务中表现良好。特别是基于 Transformer 的预训练语言模型,它完全基于自注意机机制,在自然语言处理(NLP)各项任务中取得了突破。
然而,在这些模型中,Transformer 的核心结构——多头注意力机制限制了模型的发展。多头注意力本身带来了大量的模型,这可能使训练中出现问题,而部署模型、导入庞大数量的参数也需要较高的资源支持。因此,压缩大型神经预训练语言模型一直是 NLP 研究中的重要问题。
为了解决这一问题,基于张量分解和参数共享的思想,本文提出了多头线性注意力(Multi-linear attention)和 Block-Term Tensor Decomposition(BTD)。研究人员在语言建模任务及神经翻译任务上进行了测试,与许多语言建模方法相比,多头线性注意力机制不仅可以大大压缩模型参数数量,而且提升了模型的性能。
论文地址:https://arxiv.org/pdf/1906.09777.pdf
Transformer 的张量化
在 Transformer 中,多头注意力是一个很重要的机制,由于 Query、Key 和 Value 在训练中会进行多次线性变换,且每个头的注意力单独计算,因此产生了大量的冗余参数。为了更好地压缩多头注意力机制中的参数,目前主要有两个挑战:
Transformer 的自注意函数是非线性函数,难以压缩;压缩后的注意力模型难以直接集成到 Transformer 的编码器-解码器框架中。为了解决这些问题,研究人员提出的方法结合了低秩近似和参数共享的思想,因此实现了更高的压缩比。虽然可以重建 Transformer 中的自注意力机制(缩放点积注意力),但他们并没有这么做,而是选择了分割三阶张量(即多线性注意力的输出),这样更利于提高实验准确率。
研究采用的压缩方法如图所示:
在图 2(左)中,研究人员将多头注意力重建为一个单块注意力(Single-block attention),采用的 Tucker 分解是一种低秩分解方法。在图 2(右)中,为了压缩多头注意力机制中的参数,研究人员提出了一种基于 Block-Term 张量分解的多线性注意力机制。这种机制在多个块之间共享因子矩阵(参数共享)。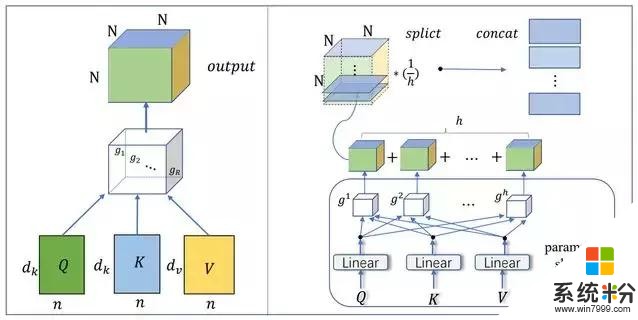
图 2:模型的压缩方法:左图为使用 Tucker 分解构建单块注意力。右图则构建了新的注意力机制——多头线性注意力。
压缩多头自注意力
模型压缩遇到的第一个问题是压缩多头自注意力中的参数数量。为了解决这个问题,研究人员首先证明了正交基向量可以线性地表示自注意力机制。然后,通过初始化低秩的核张量,重建新的注意力表示。为了构建多头注意力机制并压缩模型,他们使用了 Block-Term 张量分解(BTD),这是一种 CP 分解和 Tucker 分解的结合。Q、K、V 在构建每个三阶块张量的时候共享,因此可以降低许多参数。
图 2(左)展示了单块注意机制的结构。首先,Query、Key 和 Value 可以映射成三个因子矩阵 Q、K、V,它们由三组正交基向量组成。然后通过初始化一个可训练的三阶对角张量 G 来构建一个新的注意力机制(单块注意机制)。在图 2(左)中,R 是张量的秩,N 是序列的长度,d 是矩阵的维数。利用 Tucker 分解,可以计算出单块注意力的表达式:
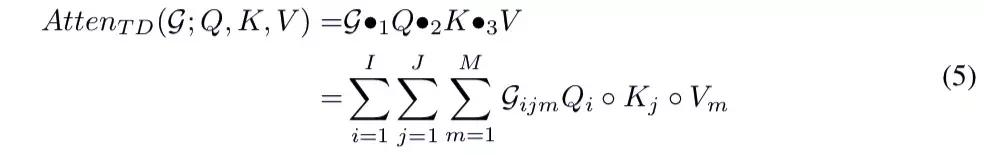
集成多头线性注意力
为了将压缩后的单块注意力张量集成在 Transformer 中,首先,研究人员计算了每个块张量的平均值。其次,将张量分割为矩阵,然后将这些矩阵级联,作为 Transformer 中下一层的输入,这样就可以集成在 Transformer 的编码器-解码器结构中。
在图 2(右)中,为了完成多头机制并压缩多组映射参数的参数,研究人员使用一组线性映射,并共享线性映射的输出。所学习的线性投影可以将 Query、Key 和 Value 映射到由基向量组成的三个矩阵。在此基础上,利用 Block-Term 张量分解来建立多头机制。研究人员将这个模型命名为多线性注意力,可将其表示为:
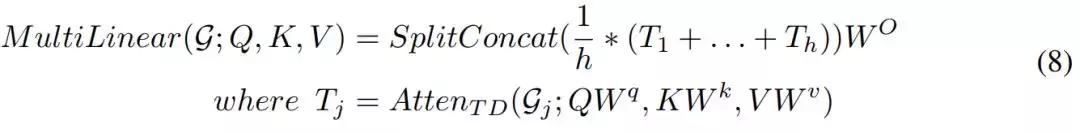
这是一个压缩模型。在对 Transformer 的多头注意力进行压缩后,实现了张量化的 Transformer。多线性注意力可以被融合到 Transformer 中。
实验结果
为了检验在 Transformer 中对多头注意力所作调整的效果,研究人员在语言建模 (LM) 和神经机器翻译 (NMT) 两个任务中进行了实验。
语言建模
语言建模的任务是预测句子中下一个单词。研究采用了语言建模的标准设置——根据前一个 token 预测下一个 token。选择了小型数据集 PTB,中等数据集 WikiText-103 和大型数据集 One-Billion。在预处理中,所有单词变为小写。新行被替换为。词汇表使用的是常见的单词,未出现的单词由 [UNK] 来表示。模型的评估基于困惑度(PPL),即每个单词的平均对数似然。PPL 越低,模型越好。
实验采用了最新的开源语言建模体系结构 Transformer,并将标准的多头注意力层替换为多线性注意力层。然后,我们在 PTB、WikiText-103 和 One-Billian 单词基准数据集上测试不同的模型配置,结果如表 1 和表 2 所示。
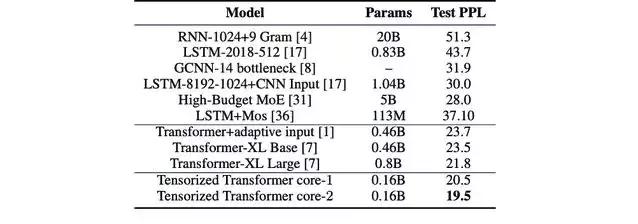
表 1:在 One-Billion 数据集上,模型的参数数量和其困惑度分数。Core-1 表示模型使用了单核张量。而 Core-2 表示使用了两个块张量(block term tensor)。
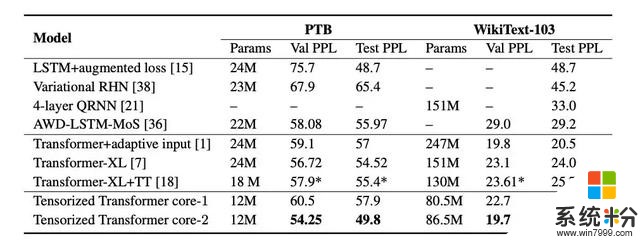
表 2:在 PTB 和 WikiText-103 两个数据集上,模型的参数数量和其困惑度分数。「-」表示没有该模型的表现报告。「*」表示为研究人员自己实现的模型结果。
神经机器翻译
在这个任务中,研究人员在 WMT 2016 英译德数据集上对 Transformer 模型进行了训练。在实验中,使用多头线性注意力替换了每个注意层。为了评估,使用集束搜索,限定大小为 5,长度惩罚 α= 0.6。结果与 Transformer 进行了比较,如表 3 所示。*表示研究人员自己实现的结果。

表 3:模型参数数量和对应的 BLEU 分数。









