微软官方解读自家机器阅读研究:要教机器学会阅读、回答和提问
选自Microsoft Blog
作者:Allison Linn
机器之心编译
参与:李亚洲、黄小天

Rangan Majumder、Yi‐Min Wang 和高剑锋(自左至右)在微软雷德蒙德研究院。
微软的研究员目前已经创造出了能够像人类一样完成两种困难任务的技术:图像识别和语音识别。现在微软的顶级人工智能专家正在研究能够完成更复杂任务的系统:阅读文本进而回答问题。
Maluuba 的联合创始人 Kaheer Suleman 说到,「我们正在尝试开发一种文献机器:它能阅读、理解文本,然后学习如何交流,无论是笔录还是口述。」微软在今年年初时收购了这家创业公司。
机器阅读系统也能帮助医生、律师和其他专家更快地完成文档阅读这样的苦差事,从而让专家们有更多的时间治疗病人或构想合法抗辩。
Maluuba 团队是微软几个解决机器阅读难题的团队之一。其他两个团队,一个在华盛顿雷德蒙,一个在北京的研究室。这两个团队在斯坦福大学的 SQuAD 数据集上正在展开竞争,使用 Wikipedia 上的信息测试人工智能系统回答问题的能力。
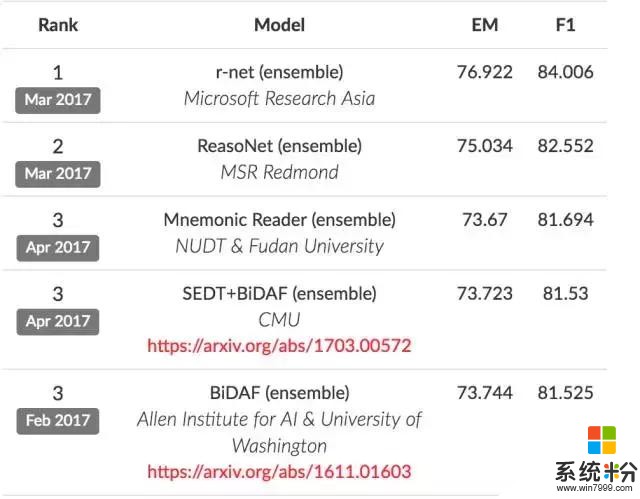
在 SQuAD 数据集上的排名
SQuAD 数据集是机器阅读这一新兴领域的核心基准,许多顶尖的学术或产业团队都在使用它测试自己的系统。它类似于 ImageNet 竞赛,激励着计算机视觉的发展。此外,微软研究员和其他来自学界、产业界的团队也在使用另一个数据集 MS MARCO 进行激烈竞争,MS MARCO 数据集使用来自 Bing 搜索词条的真实、匿名数据来测试系统回答问题的能力。
团队成员说这是一个有附加值的挑战,因为它是基于人类的真实问题。在这种数据上测试能保证建立的系统最终对客户有用。
微软 Bing 部门合作伙伴组的一位项目经理 Rangan Majumder 说:「我们不只要奖励一堆算法解决理论问题,我们也要使用它们解决真实问题,在真实数据上进行测试。」他与雷德蒙德机器阅读研究团队有密切的合作,并领导开发了 MS MARCO 数据集。

前排左二的韦福如、前排中间周明、以及微软亚洲研究院自然语言研究团队的成员
认知 VS 感知
总体而言,人工智能专家认为机器阅读要比图像识别这样的人工智能任务更困难,因为中间有太多模糊不清的地方。
北京微软亚洲研究院的周明博士表示,图像识别这样的技能是感知型任务:基于系统之前见过的图像,使用机器学习算法进行识别。目前,周明博士带领着微软亚研的自然语言研究组。
机器阅读是更复杂的认知型任务:它需要系统有大局观,查看它所读取文字的语境,甚至需要加入自身已有的关于这个主题的背景知识。
周说:「一些词可能有不同的含义,而相同的事情可能用不同的方式提及。」
另一个复杂性在于:给出的回答可能不包含问题中的词汇,甚至可能一个都没有。
例如,让我们假设有人问,「John Smith 的国籍是?」答案可能是,「John Smith 生于美国」,或者「他有美国护照」。在任何情况下,系统需要寻找、使用关联国籍的信息,但可能不会明确的说国籍这个词。
微软深度学习技术中心的高剑锋表示:「它需要生成一个答案,而且该答案与已有的都不同。」
Maluuba 的联合创始人 Suleman 提到,这正是人们如何测试其他人学习内容的方式。问问题,从小就开始问,并贯穿一生。
他们团队如何进一步推进机器阅读任务?这是一句深入的描述,「他们正在研发一种能够阅读文章并构思问题的系统,而不只是回答。该研究受启发于 20 世纪 80 年代的一个研究,研究表明在答题测试中,学生被要求写下关于一个主题的问题时会做的更好。」
Suleman 说:「有趣的是,生成问题时(而非回答)你真的需要更深入地理解文本。」

从左开始,依次是 Muluuba 联合创始人 Kaheer Suleman 和 Sam Pasupalak
搜索引擎的终结
机器阅读如此诱人是因为它对许多人都有很大帮助。
例如,高效的机器阅读系统能够推进搜索引擎的工作。相比于敲打词条,然后获得一堆链接,先进的机器阅读系统能像一个知识渊博的人回答问题一样给出解答。
高说,「它以自然的方式传递信息。」
大部分搜索引擎只能做基础的词条搜索,而且不是人们期待的那种要复制所有的信息。
机器阅读系统也能帮助医生、律师以及其他专家更快地阅读专业的医学或判例文档,从而让他们有更多的时间对病人进行治疗或构思合法抗辩。
它也能帮助人们更快地发现隐藏在汽车使用说明书或税务条例中的信息,节约时间。
高说:「世界中有大量信息,尤其是互联网中;为了让信息产生价值,需要将其转化为知识,而机器阅读技术可以在信息与知识之间搭建一个桥梁。」
数十年的研究以及最新进展
微软机器阅读工作的根基可以追溯到大约 20 年之前研究者在自然语言处理领域所做的早期工作。那时,微软的自然语言处理方面的首席研究员 Bill Dolan 开玩笑说,系统的工作只是偶尔很完美。
尽管如此,这一基础性工作正在被整合进算法之中,雷德蒙德团队正是借助这一算法取得了当前机器阅读的绝大多数进展;该算法还是 Dolan 及其团队在自然语言处理方面取得的其他突破性成果的基础。
正如过去几年出现的人工智能进展,机器阅读也从更好的深度学习算法、大幅提升的云计算能力和海量数据中大受脾益。
研究者说这些能力,连同深度学习方法在图像和语音识别领域的进步,已经使他们自信地感觉到机器阅读的重大突破尽在眼前。这正是许多人依然惊奇的事情。
微软亚洲研究院自然语言处理组首席研究员韦福如说:「这对于从事自然语言处理甚至是人工智能的研究者来说是一个长期的梦想。」
尽管如此,研究者警惕说,为了创造出可以同时在语言及其细微差别方面真正理解人类诉求的系统,仍然有大量工作要做。
通常来讲,人工智能系统仍然只擅长处理特殊任务,它们也许能够找到问题的正确答案,精确识别出狗的品种或者人类的情绪状态,甚至理解会话中的词语;但是,研究者指出,这并不意味着它们可以人类一出生就具有的方式理解信息,注意到所有的细微差别和语境。
韦福如指出,即使机器阅读团队的系统可以在 SQuAD 数据集中和人表现的一样好,但并不意味着机器可以像人一样真正阅读和理解,这是未来必须要面临的一个挑战。
周说:「这只是通向自然语言理解巨大挑战的一小步。」









