微软Malmo协作AI挑战赛冠军详解比赛思路: 我们是如何让AI在 Minecraft 里合作抓住一头小猪的
AI 科技评论按:在2017年的微软Malmo协作AI挑战赛MCAC上,新加坡南洋理工大学助理教授安波带领的团队凭借他们的AI HogRider从来自26个国家的81支团队中脱颖而出拿下冠军。
安波是新加坡南洋理工大学计算机科学与工程学院南洋助理教授,于 2011 年在美国麻省大学 Amherst 分校获计算机科学博士学位。他的主要研究领域包括人工智能、多智能体系统、博弈论及优化。有 60 余篇论文发表在人工智能领域的国际顶级会议 AAMAS、IJCAI、AAAI、ICAPS、KDD 以及著名学术期刊 JAAMAS、AIJ、IEEE Transactions,今年也在 IJCAI获得了 IJCAI early career award并进行了现场演讲。 AI 科技评论之前也对安博士做过专访,详见 能玩德扑也能保障国家安全,南洋理工安波博士阐述算法博弈论的魅力何在?

近期,冠军团队也发出了一篇详细的论文介绍了他们对协作AI的思考以及这次比赛的获奖技巧(论文已经被AAAI 2018录用)。 AI 科技评论把论文主要内容介绍如下。
比赛环境和规则
多个各自具有独立兴趣的智能体如何在复杂环境下协作完成更高级的任务一直是亟待解决的研究难点。 微软的 Malmo 协作 AI 挑战赛(MCAC)就是多智能体协作领域的一项重要比赛,鼓励研究者们更多地研究协作AI、解决各种不同环境下的问题。
今年 MCAC 2017 中的挑战问题是,如何在基于 Minecraft 的小游戏环境中让两个智能体合作,抓住一只小猪。
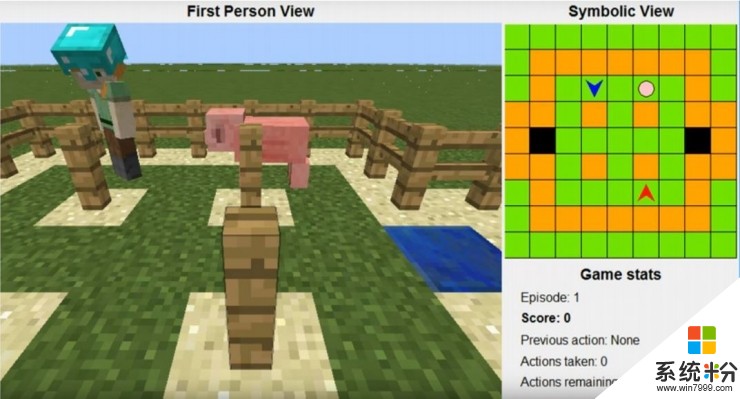
环境设置如图所示,左侧为第一人称视角,右侧为对应的符号化的上帝视角。区域一共9x9大小,绿色格子代表可以走动的草地,橙色格子是不能穿过的围栏或者柱子,两个黑色的格子是出口;粉色的圈是小猪;蓝色、红色两个箭头就是要交替行动、合作抓住这只小猪的智能体;蓝色智能体是比赛提供的,参赛选手要设计红色智能体的策略,跟蓝色智能体配合抓住小猪。
智能体的合法行为有三种,左转、右转以及前进。每局游戏中,蓝色智能体有25%的几率是一个随机行动智能体,另外75%的几率是一个沿着最短路径追着小猪跑的专注行动智能体。小猪的移动是完全随机的,并且智能体得到的信息也是有噪音的。
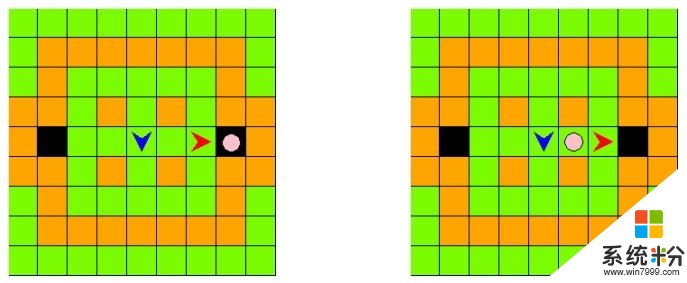
比赛的计分规则并不复杂,经过一定局数的游戏(比如100局或500局)后,统计总分。智能体和围栏/柱子一起把小猪完全围住,两个智能体就可以都得到25分,如上图所示单个智能体把小猪堵在黑色格子或者两个智能体共同夹击小猪都可以,然后进入下一局;某一个智能体自己走到出口也会进入下一局,但这时只有先走到出口的智能体可以得到5分;比赛选手的智能体每一个行动都会扣掉1分。另外,一局中智能体一共达到25个行动,或者达到大约100秒的比赛时间后,也会进入下一局。
从计分规则可以看出,参赛选手的智能体必须用尽可能少的行动步数抓到小猪才能得到高分,这个过程中也最好和比赛提供的智能体有所配合(能在更多位置抓到小猪)。
HogRider团队的比赛思路
在HogRider团队看来,多智能体合作系统本来就是一大难题。其中一个重要因素是智能体之间的互动问题,在许多实际情境中,由于每个智能体都是利己的,所以它们不一定会选择共同合作达到高回报,而可能选择回报更稳定的单独行为(即便获得的回报较少)。还有一个重要因素是不确定性,一种不确定性来自对环境和对其它智能体的有限的知识,这种不确定性还可以用概率模型应对,但也有一种更麻烦的不确定性来自某些环境相关的因素,很难用建模的方式处理。
而在MCAC这样需要形成系列决策的环境中更会放大这些困难。首先因为除了短期回报之外,还要考虑长期回报,所以在变化的环境中必须考虑当前的行动可能带来的未来影响。另一个关键特性是有限的学习次数,Minecraft中的一轮动作通常要花好几秒,要学到一个高效的策略也就很花时间。
所以团队分成了下面几步来应对。
首先分析游戏环境,找到环境的关键难点和游戏规则没有揭示的特性。
比如游戏规则并没有给出小猪的行为模式,而它的行为模式显然又很重要。在记录了一万步行动后,他们绘制出了小猪位置的分布图,如下图。
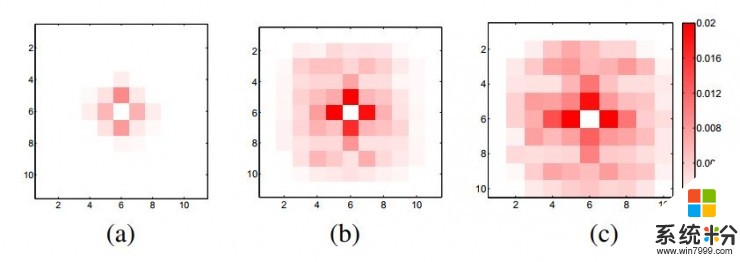
最中间的格子是小猪的初始位置,a、b、c三张图分别对应参赛选手的智能体刚做出行动的那一刻、做出行动1秒钟后、以及做出行动3秒钟后的位置。
从图中他们发现:1,小猪和智能体的行动规则不一样,智能体走一步的时候,小猪可以走好几个格子,甚至还能转弯;2,小猪往每个方向走的概率是相同的;3,参赛选手智能体两个行动间的时间越久,小猪位置移动的概率就越高。
这给他们带来一个有帮助的想法,如果小猪当前在一个抓不住的位置,那就可以等几秒钟,等待它走到能抓住的位置了再让智能体行动。
对于比赛提供的蓝色的智能体,如前文所述它有25%的概率是随机的、75%的概率是专注的;同时团队发现,观察蓝色智能体的行为也有25%左右的错误率。如果忽略了这种观察带来的不确定性就很麻烦。
这就引出了第二步,提出了一种新的智能体类型假说,用来处理这种类型的不确定性以及观察动作的不确定性。
他们设计了一个智能体类型假说框架用于更新对蓝色智能体的类型的判断,他们建立的方法能抵抗观察动作带来的不确定性。其中用到了泛化贝叶斯方法,并用双曲正切函数压缩类型判断的更新因子作为抵抗观察错误的方法。
第三步,提出了一种新的Q-learning框架。
这是用来学习每一类型的智能体对应的不同最优合作策略。首先对“状态 - 行动”的对应关系进行抽象提取,发现其实只有智能体、小猪和出口之间的空间对行动决策有影响,就显著减小了原本巨大的行动空间。然后,相比于传统Q-learning中的Q值先用随机值初始化再花很多时间训练,HogRider团队用了一个热启动的方法初始化,通过人类的推理过程形成决策树。如下图。训练时也分别为另一个智能体是随机或专注的情况训练出不同的Q-函数,集成在Q-learning框架中。
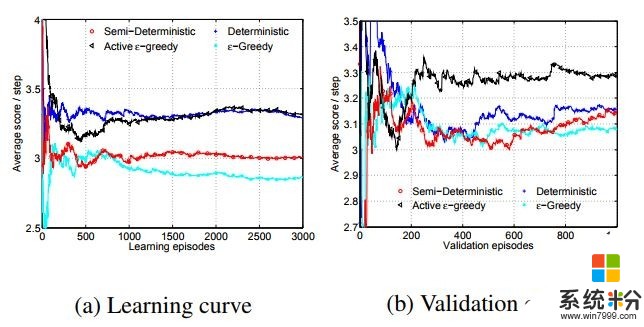
进一步地,他们还证明,当学习尝试的次数有限时,一直在整个行动空间内做随机探索是非常低效的(“ε-贪婪”),有时候甚至会妨碍找到最优策略,尤其是当找到的策略树已经不错的时候。所以他们提出了一个“活跃的 ε-贪婪”方法,以(1 - ε)的概率选择现有策略,以 ε 的概率尝试新的策略;如果带来的表现提升概率大于认为设定的50%,就更新策略。这样在“执行现有策略”和“寻找更好策略”之间比以往方法取得更好的平衡。
模型表现
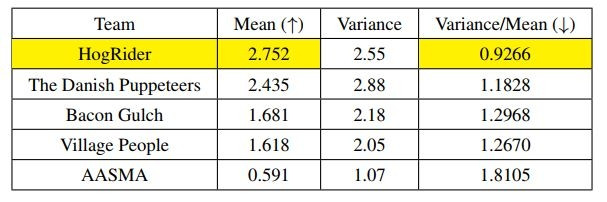
首先看比赛分数。得分最高的5支队伍分数如图,每局平均分数(越高越好)和变化幅度(分数波动/平均分数,越低越好)方面,HogRider分别领先第二名13%和21%。这表明HogRider在优化程度和稳定性方面都表现很好。
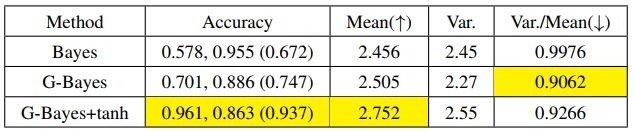
模型中选择的一些具体方法也进行了单项验证。比如第二步中更新对蓝色智能体的判断的方法,泛化贝叶斯+双曲正切限幅的准确率和平均得分就比传统贝叶斯方法高不少。
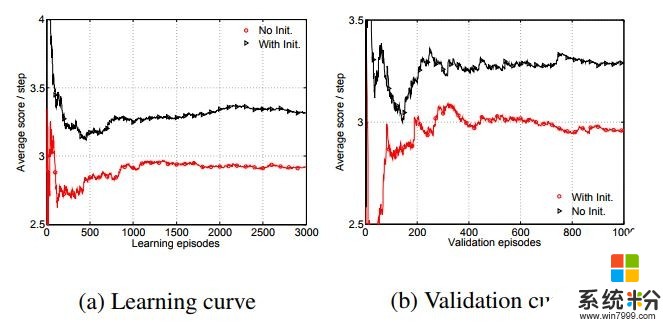
与专注的蓝色智能体协作时,带有热启动初始化的Q-Learning得分更高,学习曲线也收敛得更快
对于“活跃的 ε-贪婪”方法,通过学习曲线可以看到,浅蓝色线代表的“ε-贪婪”方法果然出现了表现下降,“活跃的 ε-贪婪”方法则可以保证在训练过程中表现总是在进步的。验证曲线更明显地体现了“活跃的 ε-贪婪”方法的优秀性。
HogRider团队还邀请了一些在读博士生尝试这个游戏,结果HogRider模型的表现比人的表现还要好不少,平均分数和变化幅度分别领先28%和29%。

比赛经验教训
论文中HogRider团队也分享了他们的经验教训,以供其它研究人员或者比赛团队参考。
首先,在开头的时候一定要深入了解要解决的问题。HogRider团队在设计智能体类型的集成框架和新的Q-Learning方法前经过了漫长的摸索,一开始他们选择的不区分智能体类别的Q-Learning只有非常糟糕的表现,毕竟要解决的问题确实会出现不同的特点,也有非常多的不确定性。前沿的算法固然是解决问题的有力工具,但认真了解问题的基础特征才能确保自己走的是正确的方向。并且,要解决面向应用的问题,最终的方案往往是多种技术的结合体,而不能指望单独用某一种复杂的方法就可以一次搞定。
其次,人类的直觉可以帮助把机器表现提升到新的高度。团队成员们一开始打算用DQN而不是Q-Learning,它虽然有良好的Q函数表达能力,但参数化的Q函数无法初始化。有一些用了DQN的团队也是表现很糟糕。这种时候,带有人类的推理能力帮助的Q-Learning就展现出了巨大优势,这种初始化方式也可以用在更多背景知识可以帮助利用人类推理能力的地方。
最后,当发现新的隐含属性后,模型和解决方案算法都应当跟着持续地更新。在比赛过程中,算法几乎编写完毕的时候团队才发现观察另一个智能体的动作原来是有一定出错的比例的,这时候他们没有偷懒,向算法中的传统贝叶斯方法中增加了两项额外的适配,也对算法表现带来了显著的提升。
结语
在对游戏结构的细致探索之后,HogRider团队结合了高效的智能体类型判断方法,以及带有热启动的新型Q-Learning(并运用了状态-动作空间的抽象化和新的搜索策略),造就了HogRider的优秀表现。
在MCAC后,未来更有挑战的研究方向是两个完全不知道对方特点的智能体如何协作,以及开发能够泛化到不同环境中的算法,这种时候智能体需要把离线学习和在线学习相结合,以及融合更多强化学习的方法。这都需要研究者们继续努力,也还有更多有趣的新发现在前方等着大家发现。









