图灵奖获得者John Hopcroft:理性看待AI浪潮,下次革命或许还需要另外40年 | 21CCC
AI科技评论消息,2017年10月19日微软亚洲研究院 联合 哈尔滨工业大学共同在哈尔滨市举办了第19届“21世纪的计算” 大型国际学术研讨会(21CCC 2017)。
“二十一世纪的计算”学术研讨会是微软亚洲研究院自创立之初便开始举办的年度学术盛会,每年都吸引着无数计算机科学领域学者们的目光。作为中国及亚太地区规模最大、最具影响力的计算机科学教育与研究盛会之一,该大会已在中国、日本、韩国、新加坡等多个国家和地区成功举办了18届。

本次大会的主题为“人工智能,未来之路”,并邀请了包括图灵奖获得者John Hopcroft在内的多位世界级计算机领域专家分享他们在AI领域的研究和观点。现场有超过1500名高校师生参与。

下面内容为记者根据几位嘉宾的现场报告和微软亚洲研究院资深研究员秦涛博士的解读整理而成,附加有现场拍摄的PPT,以飨诸位。
Peter Lee:Artisanal AI(人工智能的手工性)
Peter Lee认为,虽然目前人工智能已经到达了一种前所未有的科技高度,但是创造和部署这样的人工智能应用并非易事,需要大量的专业知识和手动设计的解决方案。所以目前AI开发还严重依赖经过训练的AI“手工艺人”或者“工匠”。因此,在这个意义上,可以说我们还正处于“手工AI”的时代。
Peter提到十九世纪欧洲工业设计领域工艺美术运动的创始人William Morris,William认为所有的人都应该可以接触到美好的东西,但是创作过程对手工艺人的依赖又阻碍了艺术的普及化。正如中国古代的丝绸、玉器一样,正是由于熟练工匠的缺乏导致这些东西价值不菲。
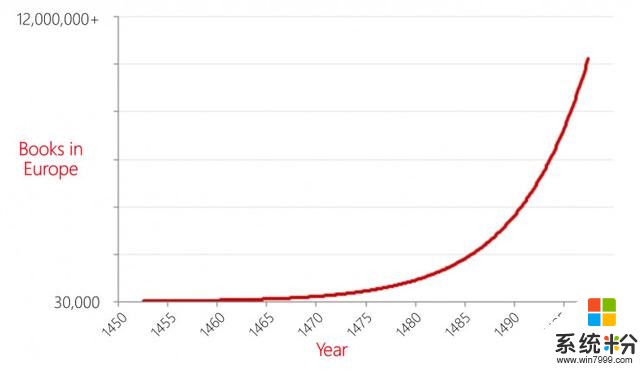
Peter以活字印刷为例。在这项发明之前,欧洲的书籍都以手抄的形式传播。随着中国的这项技术传入欧洲,在十五世纪中期,在短短的50年中,整个欧洲的书籍数量就从3万本增长到一千两百万本。这一变化对当时的社会制度是破坏性的。教堂无法继续垄断书籍,新的知识表现形式层出不穷,而人们对教育的期望也从根本上发生了改变。Peter认为,从某种意义上来说,我们面临的AI对人类社会的当前结构也将是破坏性的,AI将和活字印刷机一样改变人类历史。但是我们还需要从“手工AI”的时代往前走,创造出人人皆可用的AI技术。
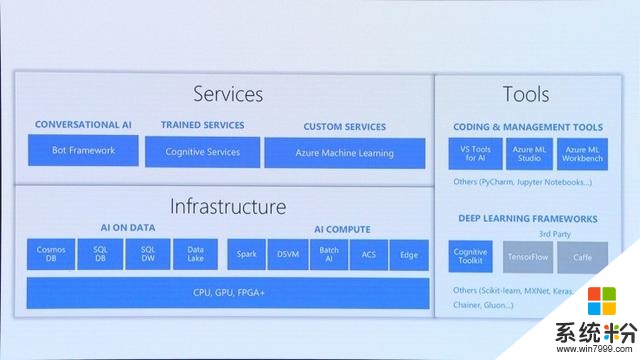
Peter介绍,微软当前正在着手这样的工作,以让更多的人便捷地使用AI技术。他向大家展示了微软搭建的基于云的AI平台。其中The Bot Framework可以帮助开发者便捷地搭建聊天机器人,Cognitive Services让开发者方便地将AI嵌入到每个APP中,Azure Machine Learning则可以帮助你从零开始进行数据研究以及创建AI应用。这个平台有较为先进的数据服务以及最新的硬件设备,支持所有主流开源的机器学习框架,具有良好的扩展性。
John Hopcroft:The AI Revolution(AI 革命)
在本演讲中,康奈尔大学计算机系教授、1986年图灵奖获得者John Hopcroft带领大家回顾了机器学习的基础知识,并分享了一些深度学习领域中比较有趣的研究问题。
John从最简单的线性分类器(感知器)算法讲起。随后介绍了在数据线性不可分情况下把样本映射到更高维空间的研究,包括核函数等,这种情况下支持向量机的出现极大地促进了这方面的研究。在支持向量机之后,机器学习的下一个大的发展就是深度学习。随着深度神经网络的引入,特别是卷积神经网络(卷积神经网络,由卷积层、池化层、全连接层组成,最后是softmax输出每个类别的概率)的引入,图像分类等方面的错误率逐年下降,在2015年微软亚研院提出的152层深度残差网络(ResNet)在图像分类中超过了人的识别水平。

但是在这方面还有很多问题值得研究,例如每个门学习的是什么、怎样让第二层的门与第一层的门学习不同的信息、怎样让一个门学习的内容随时间演化、用不同的初始权重门学习的是否是相同的内容、用不同的图像集训练两个网络早期的门学习的是否相同等等。

此外,在训练一个深度网络时,可能会有许多局部极小值,有些极小值可能会比其他的好。如何保证我们在训练的过程中能够找到一个好的局部极小值呢?训练深度网络往往会花费很长的时间,我们是否可以加速训练呢?这些也都是非常有意义的研究方向。

随后John考虑了当训练两个网络时会出现什么有趣的研究。对于两个网络,我们可以同时训练,也可以一先一后。

这两种情况,两个网络在激活空间里是否共享相同的区域呢?

一个当前比较火的例子就是生成式对抗网络(GAN),这个网络属于一先一后的情况。

最后John提出了一个问题:人工智能是真的吗?他认为,现在的人工智能只是高维空间中的模式识别,AI还不能提取出一个事物的本质或者理解它的功能。在John看来,要想实现这一点,只是需要另外40年的时间。

他还说到,其实很多现在看来是智能的任务其实都不是AI,有些只需要强大的计算以及大数据就足够了,例如棋类比赛。计算机正在做越来越多的人们以为需要智能的事情,实际上有些并不是AI。所以我们在从事人工智能相关的工作时要想一想,这个问题的核心的是AI吗?还是仅仅需要大计算而已?
Lise Getoor:Big Graph Data Science(大图数据分析)
图数据是 Lise Getoor教授一直以来的研究对象。Lise Getoor教授认为,我们正处于数据爆炸的时代,图数据无处不在。然而,数量并不代表质量,大数据分析的挑战之一就在于如何能够合理利用大型、异构、不完整且带有噪音的集成数据进行合理推论。

在演讲中,Lise Getoor教授首先给我们介绍了一些图数据所需的常见推理模式。

例如为缺失标签的节点做标签预测的协同分类(collective classification),给出数据里隐含的连接节点的边的连接预测(link predictions),以及判断两个节点是否为同一实体并进行合并的实体分辨(entity resolution)。

随后她像我们介绍了用于解决这些重要问题的一种工具——概率软逻辑(probabilistic softlogic ( PSL ),psl.linqs.org)。
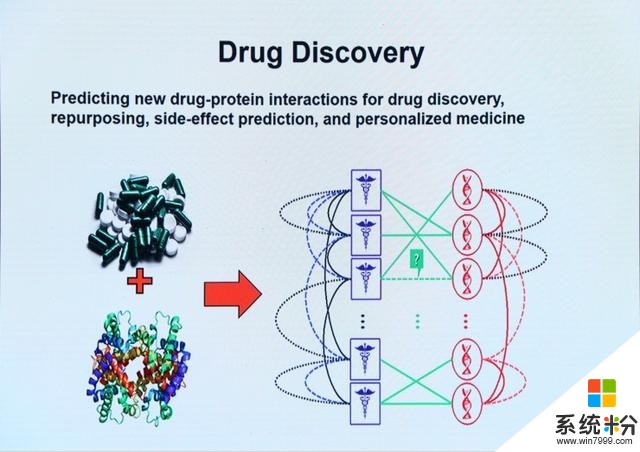
最后她向我们展示了PSL应用的一些案例,例如政治辩论立场分类、混合推荐系统、药物研究、垃圾邮件检测等。
Raymond Mooney:The Deep Learning Revolution: Progress, Promise, and Profligate Promotion(深度学习革命)
首先Raymond教授简单回顾了机器学习的历史,从单层神经网络到符号AI和知识工程,到多层神经网络和符号学习,到统计学习和核方法,再到近年来的深度学习。

1957年,弗兰克•罗森布拉特(Frank Rosenblatt)提出感知器算法。感知器就是一个最简单的神经网络,只有输入层和输出层,没有隐藏层。感知器利用爬山法从训练样本中进行学习更新参数。只有当样本线性可分的时候,感知器才能进行学习;很多分类的函数感知器并不能学习,例如XOR。
1969年,马文•明斯基(Marvin Minsky)和西摩尔•帕普特(Seymour Papert)发表了《Perceptrons: An Introduction to Computational Geometry》,书中描述了简单神经网络也就是感知器的局限性。此后七十年代到八十年代初期,神经网络方面的研究陷入了低谷。
上个世纪80年代中期连接主义的兴起导致了神经网络的复兴,这一时期反向传播算法被用来训练3层神经网络(包含输入层输出层以及一个隐藏层)。但是,通用反向传播算法并不能很好的推广到更深的网络,并且其方法也缺乏理论基础,因此1995-2010这15年间神经网络的研究陷入了第二次低谷,这一时期机器学习研究的兴起转移到概率图模型和以支持向量机为代表的核方法。

2010年以后,随着更好的深度神经网络训练方法的提出,神经网络又卷土重来。深度学习“革命”,Raymond用“革命”一词来形容深度学习的影响之大。深度学习在几大方面取得了成功,包括计算机视觉(主要归功于卷积神经网络CNNs)、机器翻译和语音识别(主要归功于循环神经网络RNNs)以及视频和棋牌游戏(得益于深度强化学习)。

近年来深度学习的推动力除了前面提到的更好的训练算法和模型,还有两个方面:大规模有标注的训练数据和强大的计算力(如GPU)。大数据、大模型、大计算是深度学习成功的三大支柱因素,但它们同时也为深度学习的进一步发展和普及带来了一些制约因素。现在深度学习面临一些新的挑战,包括(1)如何从无标注的数据里学习,(2)如何降低、压缩模型大小,(3)全新的硬件设计、算法设计、系统设计来加速深度神经网络的训练和使用,(4)如何与知识图谱、逻辑推理、符号学习相结合像人一样从小样本进行有效学习,(5)如何在复杂的动态系统里进行博弈机器学习。
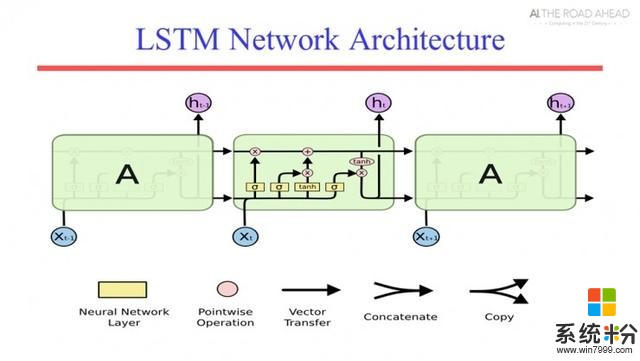
随后Raymond教授简单介绍了卷积神经网络、循环神经网络以及深度强化学习的基本内容,并分析了为什么在人工智能领域,科学家总是热衷于让AI跟人类下棋,玩游戏?

从简单的跳棋、五子棋,到更加复杂的中国象棋、国际象棋,以及最近非常热门的围棋和德州扑克,每次AI在某个智力游戏上成功地击败人类选手,便会让大家唏嘘不已,慨叹AI会在不久的将来取代人类。而科学家之所以乐于选择棋类游戏,一方面是因为它们自古以来就被认为是人类智力活动的象征,模拟人类活动的AI自然要以此为目标。成功达到人类甚至高于人类水平,可以吸引更多人关注并投身于人工智能的研究和应用中来。另一方面,棋类也很适合作为新的AI算法的标杆(Benchmark)。棋类游戏的规则简洁明了,输赢都在盘面,适合计算机来求解。理论上只要在计算能力和算法上有新的突破,任何新的棋类游戏都有可能得到攻克。一个会下棋的AI也并非科学家的终极目标,其更积极的意义在于,AI算法在研究棋艺的过程中不断精进和提升,会带来更多设计上的创新,从而在根本上提升人工智能算法的能力和适用范围。

Raymond教授认为机器学习、神经网络等有着悠久的历史,深度学习也取得了很多成绩,并且还将取得更多成绩,但现在深度学习的能力被过度夸大了,其有着明显的局限性,还不能真正解决AI问题。Raymond认为我们不能过于满足和夸大当前的成绩,AI的核心问题尚未解决,未来的路还很长。
滕尚华:Scalable Algorithms for Big Data and Network Analysis(大数据和网络分析的可扩展算法)
身处大数据时代,我们对高效算法的需求比先前任何时候都要突出。滕尚华教授指出,大数据将我们带入我们先驱者所设想的渐近世界,但问题规模的爆炸式增长也对经典算法的有效性提出挑战:根据多项式时间表征,以前被认为有效的算法可能不再适用,有效的算法应该是可扩展的。换句话来说就是,问题的复杂性就问题的大小而言,应当是线性的或近似线性的。因此可扩展性应该被提升为用于表征高效运算的中心复杂性概念。而设计具有可扩展性的算法,需要借助一些技巧,例如拉普拉斯范式。这类技巧包括局部网络探索、高阶抽样法、稀疏化以及图分割等。此外还包括谱图理论方法,如用于计算电流和在高斯-马尔可夫随机场中取样等。这些方法体现了网络分析中组合、数值和统计思维的融合。滕尚华教授在演讲中,通过一些基本的网络分析问题解释了这些技巧的应用,特别是在社会和信息网络中确定重要的节点和连贯的社区中的应用。
注:由于此时记者正在采访其中一位嘉宾,没能聆听滕尚华教授的报告内容,深表遗憾。
洪小文:探索机器和人类学习的方式
在本演讲中,洪小文博士将介绍微软亚洲研究院在帮助机器学习方面取得的最新成果,例如对偶学习和自生成数据学习。此外,他还强调了机器学习目前面临的一些重要挑战。

洪小文博士表示近年来,机器学习在计算机视觉、语音和自然语言处理等领域取得了长足的进步。随着人工智能对社会的影响越来越大,更多挑战需要人们去研究、去攻克,因此无论是对人类还是机器来说,我们都进入了持续学习的时代:从“无所不知”到“无所不学”。
对偶学习对于计算机而言,学习需要时间、数据和老师,而深度学习则需要大规模的标记数据。数据标记的成本非常高,并且在很多应用场景中,获取大量标记数据已是难题(例如罕见疾病、少数民族语言等)。为了降低对大规模标注数据的依赖性,微软亚洲研究院的研究员提出了一种新的学习范式——对偶学习。

很多人工智能的应用涉及两个互为对偶的任务。例如,机器翻译中从中文到英文翻译和从英文到中文的翻译互为对偶,语音处理中语音识别和语音合成互为对偶,图像理解中基于图像生成文本和基于文本生成图像互为对偶等等。这些互为对偶的任务可以形成一个闭环,使从没有标注的数据中进行学习成为可能。
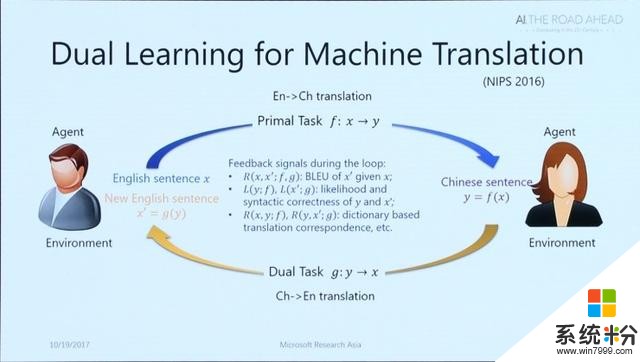
对偶学习的最关键一点在于,给定一个原始任务模型,其对偶任务的模型可以给其提供反馈。同样的,给定一个对偶任务的模型,其原始任务的模型也可以给该对偶任务的模型提供反馈,从而这两个互为对偶的任务可以相互提供反馈,相互学习、相互提高。
洪小文博士表示除了机器翻译,对偶学习还可以用于训练图像分类生成、情感分析等多个研究领域。
自增强学习介绍完对偶学习,洪小文博士开始探讨在多个领域展示出优势的卷积神经网络CNN是否同样适用于3D图形领域。和其他学习任务一样,训练CNN需要大规模的数据,保证大量的图片输入和与之对应的材质属性。而数据采集需要非常多复杂的设备支持、相对更长的采集时间,同时要求大量的手工工作,这其中的成本是相当高昂的。

为了利用这些海量的未标定的照片来进行机器学习,我们设计了自增强训练的方法(Self-augmented training)。自增强训练采用了一种特殊的CNN训练方式,区别于传统利用标注的输入输出对作为训练数据的训练方法,自增强训练利用当前尚未训练好的CNN来对未标定的数据进行测试。
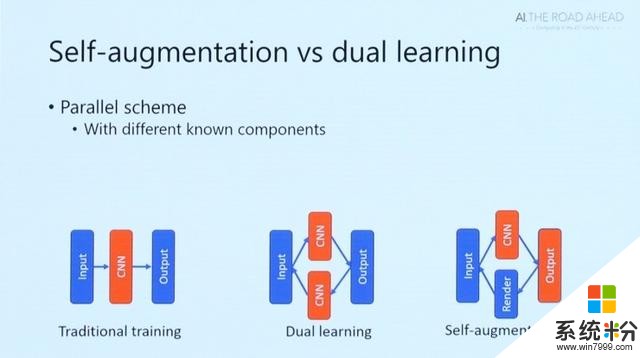
当然,由于现在CNN还没有训练好,测试结果肯定不能作为正确的标定用来训练。但是,我们对材质属性估计这个问题的逆问题,具有完整的知识。因此,可以用这个中间测试结果得到的材质属性,配合现有的材质渲染程序,生成一个当前中间结果的材质属性和其对应的渲染结果(照片)的数据对,这一数据对是完好保持纹理照片和纹理属性这一对应关系的“正确标定数据对”,因此我们就可以放心地利用这一自增强出来的数据来进行训练。
AI 创造除机器进行自身学习以外,人类同样需要提升自己的技能。

洪小文博士表示机器还可以在多方面帮助人们学习,例如提供学习建议和案例,作为语言学习的辅助手段。AI还可以有艺术创造力:创作诗歌、歌词以及音乐,对图片进行风格转换等。
微软小英
首先,洪小文博士介绍了微软小英。它可以帮助初学者快速建立日常英语沟通能力,帮助英语学习者完善发音,熟练口语。微软小英融合了语音识别、语音合成、自然语言理解、机器翻译、机器学习、大数据分析等人工智能前沿技术。
小英的口语评测系统搭建在一个由机器学习训练成的神经网络的语音识别系统上,基本处理流程是利用语音识别模型,根据跟读文本对用户的录音进行音素层级的切分。每一个小单元再和其相应的标准发音模式进行匹配,发音越标准则匹配越好,得分也越高。系统中各个标准发音的模型是深层神经网络在几百个发音标准的美式英语数据库中训练而成的。
微软小冰
随后,在AI的艺术创造方面,洪小文博士介绍了微软小冰的写诗能力。据介绍,小冰写诗,主要是运用了生成式对抗网络(GAN)。
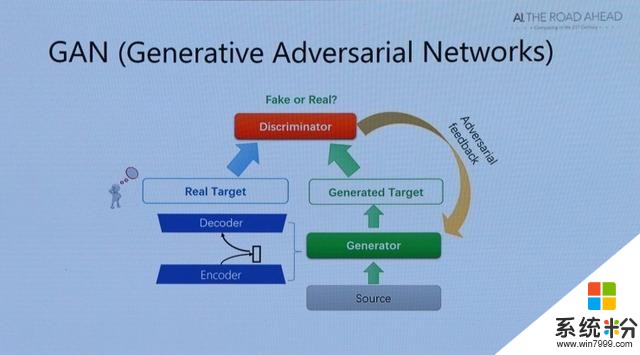
简单来说就是,有一个诗歌生成模型(generator),它的目标是生成一首接近于人类创作的诗歌;与此同时我们有一个诗歌判别模型(discriminator),它的目标是能够正确判别一首诗是机器生成出来的还是人类写的。诗歌生成模型和判别模型之间进行博弈,直至生成模型与判别模型无法提高自己——即判别模型无法判断一首诗是生成出来的还是真实的而结束。小冰于今年出版了第一本现代诗集《阳光失了玻璃窗》,洪小文博士现场展示了小冰创作的诗 。



除了作诗,她还能根据诗词谱音,创作一首歌曲。


风格迁移
此外,洪小文博士还介绍了深度学习运用到图片风格迁移的研究。他们利用卷积神经网络分解内容图片和风格图片的特点,然后加以融合。微软亚研院的研究员在CVPR 2017上发表了一种新的风格迁移算法,该算法对图像的风格提供了一种显式的表达“风格基元”(styleBank),通过对不同风格的图片使用不同的“风格基元”,再用简单的自解码器模型(auto-encoder)便可以实现不同风格的迁移。目前这项风格迁移技术已经被应用到最新的相机应用Microsoft Pix iOS版, 允许用户将照片的纹理、图案和色调转化成所选定的风格,使之成为一件独特的创作作品。

洪小文博士补充道,除上述算法以外,微软亚洲研究院的研究员们还提出了一个端到端 ( end-to-end ) 的在线视频风格迁移模型 ( Coherent Online Video Style Transfer )。

这个模型在处理相邻帧的连续性的做法是:对于可追踪的区域,用前一帧对应区域的特征以保证连续性,而对于遮挡区域,则用当前帧的特征,最后得到既连续又没有重影的风格化结果。

而对于更为精确和精致的视觉特征转化,需要建立图像间的语义对应。微软亚研院的研究员们提出了一种新的算法,结合图像对偶技术(Image Analogy)和深度神经网络(DNN),为内容上相关但视觉风格迥异的两张图像之间建立起像素级的对应关系,从而实现精确地视觉特征迁移。

最后洪小文博士总结到:人类和机器都进入了持续学习的时代:从“无所不知”到“无所不学”;学习过程永远需要时间、数据和老师,而在学习过程中,机器和人类将一同共进化;对偶学习等新的方法让缺乏大量标记数据的机器学习成为可能;Encoder-decoder DNN 以及 GAN等神经网络让机器有了艺术创造力;人类可以利用机器更好地学习。









