微软黄学东:「超人」语音识别模型只是优秀产品的其中一环
机器之心原创
参与:邱陆陆
今年 9 月,微软语音识别研究团队在黄学东的带领下,将去年 10 月刷新的 5.9% 词错率降至 5.1%。作为微软全球技术院士,黄学东认为,在技术研究的「最后一英里」,每 0.1 个百分点的进步都异常艰难。
每年的秋天也都是微软语音「收获」的季节,重量级的研究成果接连发布,将人与机器连接更紧密的产品逐步进入大众视野。今年也不例外,刷新 Switchboard WER 纪录的论文于八月发布,与 Harman 联手研发的智能音箱准备就绪,在中国,小冰也顺利进入第五代。
9 月 8 日,我们专访了机器之心的「老朋友」——微软全球技术院士黄学东,共同探讨了语音领域这一年里技术方法的变迁,关注重点的转移,以及从高精度模型到好用产品的转化之路。以下为专访内容:
WER 5.1% 的「超人」语音识别模型和说不定不会来的强人工智能
去年十月份,微软的语音识别系统在 Switchboard 语音识别任务测试中达到了低至 5.9% 的词错率(WER),实现了人类专业速记员的水平。现在一年过去了,语音识别领域有哪些突破性进展吗?
有,进展用一句话可以总结:词错率从 5.9% 降到了 5.1%。可能大家觉得这个进展不大,但是在「最后一英里」上,每 0.1 个百分点的进步都蛮艰难,必须保证系统没有任何bug。何况从相对错误率降幅(relative error rate reduction)角度, 5.9 到 5.1 是一个超过 10% 的相对进步,我们觉得十分满意。
另外,通过做 Switchboard 我们学到了很多新东西。这些会直接转化到我们的产品系统,让从 Cortana 到 Cognitive Services 再到 PowerPoint Presentation Transltor 这些微软的各种语音产品与服务都向前走。除了没有计算资源限制的情况下的最佳效果之外,我们也关注在训练数据和训练时间有限的情况下的最佳效果。虽然微软有钱有人力,但是我们希望与其他研究人员站在同样的起跑线上交流系统研发成果,并且做到最好。
从 5.9% 到 5.1% 是如何实现的呢?调整结构亦或调整参数?
我们跑了一千多个实验,评估了上百个不同的模型,几乎把所有的排列组合试了一遍,可以说是「粒粒皆辛苦」了。
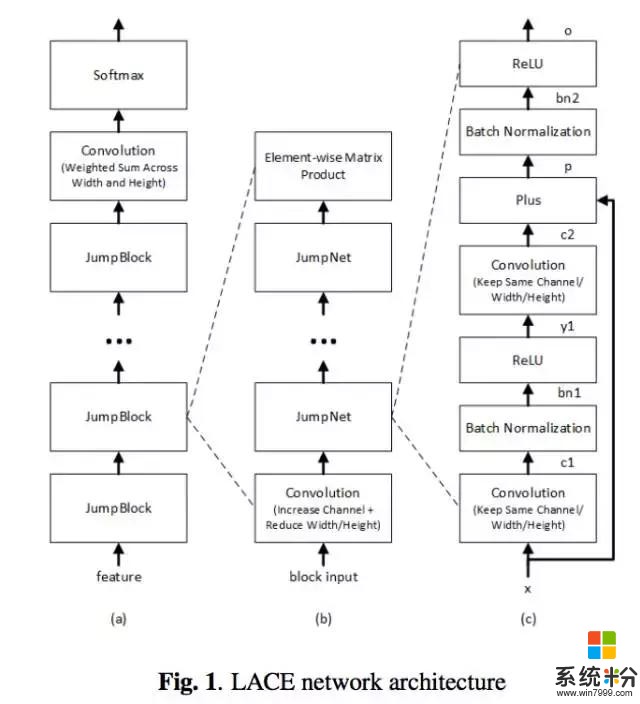
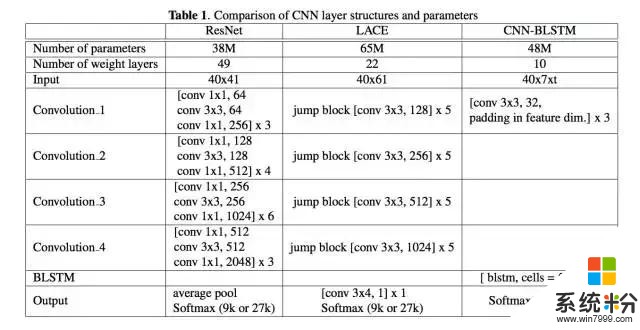
模型效果的进步来自以下几个方面:一是语音模型方面,以前我们虽然同时用到 Bi-LSTM 和 ResNet,但是模型间是完全独立、彼此并行的。现在我们把 CNN 和 Bi-LSTM 串联为一个模型,通过三层卷积操作提取底层的特征,然后再用 六层 Bi-LSTM 学习特征之间的序列依赖关系。二是在语言模型方面,模型从词级别进一步细化到字符级别,并且利用了整个对话的全局信息以及其中的语段(session)局部信息。三是在不同模型相结合方面,我们利用了不同的信号,这有点像提升决策树和随机森林算法的理念,信号是最基本的子语单元音(subphonetic senone),不同信号的引入让系统更加鲁棒。
5.9% 的次错率是人类专业速记员的水平,那么 5.1% 呢?是否可以说语音识别问题已经基本解决了?
语音识别作为一个整体还远没有解决,在 Switchboard 上可以说是解决了。5.1% 是什么概念呢:IBM在澳洲找了4个专业转录团队,他们可以比较、讨论、重听,四个团队一起工作的最好结果可以做到 5.1%。所以说,我们的系统做到5.1%,我觉得是达到了「超人」的水平。但是这只是在 Switchboard 这个任务上。
真正的语音识别有口音、噪音、远场、语速等等问题,在这些方面,人的鲁棒性还是不同一般的。所以我们在这个任务上达到了「超人」的水平只是一个小小的里程碑。今年我们的系统比去年增加了四个更加强大的神经网络、有了比去年更强大的语言模型,但是模型还不是即时的,因此距离投入实际应用还有一定的距离。然而就像现在生物学家寻找治疗癌症的药物的过程一样,我们要不惜代价去寻找更好的靶点。这就是为什么我们仍然在追求 WER 更低的系统。但我觉得今后几年语音识别普遍达到超人水平应该不是一个关键问题。
那么关键问题会是哪些任务?
语言理解,理解那些在交流过程中还没有用语言表达出来的意思。在感知方面,今后几年计算机可以达到人的水平,然而在认知上,人可以通过上下文以及额外的手势和眼神等信息对说话人的意思有比较透彻的理解,计算机在这方面差距还是很大的。
另外现在的系统还是非常的复杂,语音部分就有14个神经网络并行运作,要整合起来,再把语言模型加上去,再做整合…… 系统还是需要做非常多简化。
您在加入微软之前也曾参与过 CMU 的语音系统开发,高校和企业的研究团队在开发语音系统时有什么异同?
本质上是一样的,因为微软研究院的大批人都是从CMU过去的。CMU 的研究是非常实际的,要做最前沿的东西、做出来的东西要可以很快产品化且有实际效果。所以微软的研究院和CMU 计算机系的风格是非常接近的。微软的几任院长,李开复、沈向洋、洪小文不仅仅都是从CMU计算机系出来的,还都跟随同一位导师,Raj Reddy。
不同之处,一是在学术界做图像的人比较多,做语音的人相对比较少。第二,业界用语音可以做到实用的任务比较多,所以工业界的投入相对比较高,学术界很难和工业界抗衡。
另外,虽然说深度神经网络对感知这个大领域功不可没,但是在推出产品的时候,工程师要考虑的问题远比一个语音识别问题要多。比如用什么样的数据来训练模型,用什么样的模型来做更有效率,如何和其他的系统更紧密地衔接…… 想要推出一个简单好用、高效快速的产品或服务,是要解决很多工程问题的、方方面面都考虑到的,这是在大学做研究时候一般不会提到的事情。解决工程问题所需的资源比做一个这样的研究系统高很多,例如现在我们这个团队里,做纯研究的人员、资源不到10%。
语音领域从「识别」到「理解」,需要经过怎样的一个进程?
神经网络在识别领域所谓的「突破」其实并不算什么突破。它就是一个函数,如果有足够多有标注的点,就可以从一个序列映射到另一个序列。所以机器翻译、图像识别、语音识别,由于有很好标注的映射关系,所以进步比较大。但是自然语言理解,理解什么,标注什么?我们不仅缺少有标注的数据,即使标注了大家也不一定统一,尤其是深度推理、生成性模型,都是很玄乎的东西。
所谓(具有理解能力的)强人工智能,迄今为止还没有看到任何大的进步。深度学习会不会为我们带来强人工智能仍然是一个大问题。大家都觉得语音识别、计算机视觉、机器翻译都有很大的突破,就会导致人工智能在感知上有突破。其实这里要画一个很大的问号,不一定有。
好模型只是好产品的其中一环
可以完成任何任务的「强人工智能」还很遥远,那么旨在完成有相关性的不同任务「迁移学习」?
微软把三十多种不同的人工智能服务集合成 Cognitive Service 部署在云上。Cognitive Service 最大的特点是有定制的能力,可以根据用户在使用它时的不同要求,定制语音识别、图像识别功能。我们把工具交到开发者手中,只要有足够多的数据,开发者就可以根据自己的需求进行定制。这也是一种迁移学习。

此外,像 Cortana 这样的个人数字助理,现在基本尚不具备自我学习能力。只有把这种能力纳入系统,才会实现一个更大的飞跃。当然,实现这一功能要比较大的成本,因为不断地学习需要不断收集数据,所以有很大一部分是工程成本。
说到成本,训练中、实验中,我们可以不计成本地使用计算资源追求更高更快,但是实际部署上还是要考虑实时性以及运行成本的。您能给我们举一个例子说明从模型到产品的优化过程吗?
Microsoft PowerPoint Presentation Translator 就是一个例子。虽然我们在 Switchboard 达到了人的水平,但是来到具体产品中,要求实时性了,就是一个没有达到人的水平的「简化版」,并且还要戴一个麦克风来把远场问题变成近场问题。
大家现在都可以去微软的网站上去下载这个 Presentation Translator,它会成为 PowerPoint 的一个插件。然后你可以用英文、中文、法文等等语言进行演讲,演讲内容可以被实时翻译成超过 60 种语言的文本。如果演讲的听众讲不同语言,他们还可以在自己的智能设备上通过 Microsoft Translator APP 加入会议,看不同语言的实时同声传译,并用不同语言与嘉宾互动。重要的是,我们有能力根据用户演讲时的口音、用词习惯进行调整。比如我有湖南口音,电脑会据此作出调整。
微软的语音技术现在还服务于哪些人工智能的产品线?
除了 Presentation Translator之外,Skype 也有 Skype Translator,你在给另外一个人打电话的时候,你可以用你自己的语言讲,对方也可以用他自己的语言来回答。然后微软有Cortana,这个是个人助理,你可以通过语音与电脑进行交互。今年秋天我们还会推出一款智能音箱,是与德国的 Harman 合作的包含 Cortana 的产品。我自己试用经历是,它改变了我的生活方式。每天早上在我睁开眼睛之前,我就可以和它对话,知道现在几点了,有没有微软的新闻,我今天早上有哪些会议,我刚刚睡醒这半个小时得到了最充分的利用。音箱在家居里是很不起眼的一个小小的设备,我们会用「背景设备」(ambient decice)来形容它,然而因为有了语音交互,它改变了所处的整个环境,让我的生活更有效率。
能谈谈 Cortana 和 Alexa 以及其他第三方开发者的合作吗?
第三方开发者可以开发 Cortana Skills。Alexa 也可以参与含有 Cortana 的音箱。我可以在 PC 上说,「Hey Cortana, open Alexa. 然后让 Alexa 帮我去亚马逊买东西。」Cortana 本身也有很多独到的地方,他和 Office 365、Skype 的整合比较好,所以我知道我的日程、能与朋友联络。我们还有必应搜索,可以搜索知识库并回答简单问题。
微软也与 Facebook 联合推出了神经网络交换格式 ONNX,能简单谈一谈么?
有了 ONNX 之后,我们和 Caffe2 和 Pytorch 的模型就可以互换。你可以用 Pytorch 写模型,在 CNTK 上跑。CNTK 也能够把在 Caffe 上的模型读取并继续训练。CNTK 最大的强项就是快,跟据香港浸会大学褚教授团队比较, CNTK 比 TensoFlow 在 RNN 上快 3-6 倍。这也是我们为什么能够率先达到5.1% 的 WER。它可以将大量数据合理分配到不同 GPU 上进行并行计算。
CNTK 是最底层的工具,用以产生 Presentation Translator模型,模型产生后被打包、放在云端的 Cognitive Services 里面。在人工智能的每一个层面微软都有涉及。
像 Presentation Translator 这样一个产品,从语音识别模型到最后以插件形式作为产品呈现在用户面前,开发过程中最大的障碍在哪里?
我觉得一个好的产品最重要的是要了解的用户的使用场景。我觉得这个PPT的场景非常到位。我当年带着美式英文的底子去爱丁堡大学留学,一到苏格兰就傻了,苏格兰英语,看没有问题,听却听不懂。当时我就想,如果每一位教授讲课的时候像 BBC 一样有闭路字幕(closed caption)该多好。今天,如果爱丁堡大学的教授下载了Presentation Translator,那么每一个去苏格兰的中国学生都不会重复我当年所受的痛苦了。换一个场景,我们可以支持100个人同时用60种不同的语言讨论会话,60种语言基本上能涵盖世界上90%的人口,他们都可以跨国语言障碍参与讨论。
技术是产品中非常重要的一环,但并不是一个产品成功的关键。我觉得这些场景和技术一样有价值。微软能以这样的场景通过人和机器的连接让人和人靠得更近,消除语言障碍是一件非常有意义的事情。









