微软推出深度学习加速平台脑波计划:FPGA驱动实时人工智能
选自微软博客
机器之心编译
参与:路雪、黄小天、蒋思源
近日在 Hot Chips 2017 上,微软团队推出了一个新的深度学习加速平台,其代号为脑波计划(Project Brainwave),机器之心将简要介绍该计划。脑波计划在深度学习模型云服务方面实现了性能与灵活性的巨大提升。微软专为实时人工智能设计了该系统,它可以超低延迟地处理接收到的请求。云基础架构也可以处理实时数据流,如搜索查询、视频、传感器流,或者与用户的交互,因此实时 AI 变的越发重要。
近来,FPGA 对深度学习的训练和应用变得越来越重要,因为 FPGA:
性能:低批量大小上的优秀推理性能、在现代 DNN 上服务的超低延迟、>10X 且比 CPU 和 GPU 更低、在单一 DNN 服务中扩展到很多 FPGA。
灵活性:FPGA 十分适合适应快速发展的 ML、CNN、LSTM、MLP、强化学习、特征提取、决策树等、推理优化的数值精度、利用稀疏性、更大更快模型的深度压缩。
规模:微软在 FPGA 上拥有全球最大的云计算投资、AI 总体能力的多实例操作、脑波计划运行在微软的规模基础设施上。
所以我们发布了脑波计划(Project BrainWave),一个可扩展的、支持 FPGA 的 DNN 服务平台,它有三个特性:
快速:小批量 DNN 模型有超低延迟、高吞吐量服务
灵活:适应性数值精度与自定义运算符
友好:CNTK/Caffe/TF/等的交钥匙(turnkey)部署
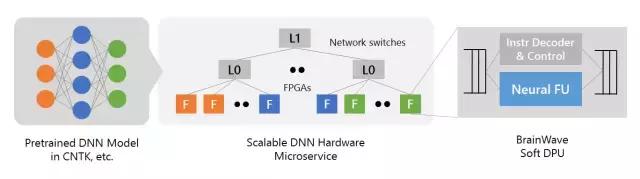
脑波计划
脑波计划系统的主要内容包括以下三个层面:
一个高性能的分布式系统架构;
一个集成在 FPGA 的硬件 DNN 引擎;
一个用于已训练模型的低摩擦(low-friction)部署的编译器和运行时间。
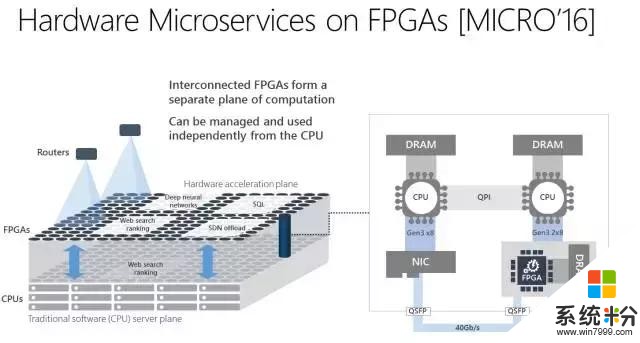
首先,脑波计划利用了微软这些年一直部署的大量 FPGA 基础架构。通过把高性能 FPGA 直接连接到我们的数据中心网络,我们可以把 DNN 作为硬件微服务,其中 DNN 可以映射到一个远程 FPGA 池,并被循环中没有软件的服务器调用。这个系统架构不仅可以降低延迟(因为 CPU 并不需要处理传入的请求),还可以允许非常高的吞吐量,并且 FPGA 处理请求可以如网络的流式传输一样快。
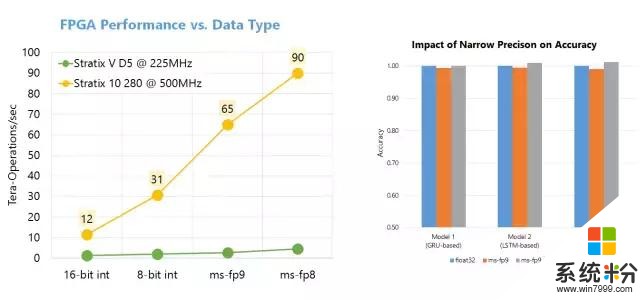
第二,脑波计划使用了一个强大的在商业化可用的 FPGA 上合成的「软」DNN 处理单元(DPU)。大量的公司,包括大型公司和一大批初创公司,正在构造硬化的 DPU。尽管其中一些芯片具有高峰值性能,但它们必须在设计时选择运算符和数据类型,这限制了其灵活性。脑波计划采取了另一种方法,提供了一个可在一系列数据类型上缩放的设计。这个设计结合了 FPGA 上的 ASIC 数字信号处理模块和可合成的逻辑,以提供一个更大更优化数量的功能单元。这一方法以两种方式利用了 FPGA 的灵活性。首先,我们已经定义了高度自定义、窄精度(narrow-precision)的数据类型,无需损失模型精度即可提升性能。第二,我们可以把研究创新快速整合进硬件平台(通常是数周时间),这在快速移动的空间中至关重要。因此,我们取得了可媲美于甚至超过很多硬编码(hard-coded)DPU 芯片的性能,并在今天兑现了性能方面的承诺。
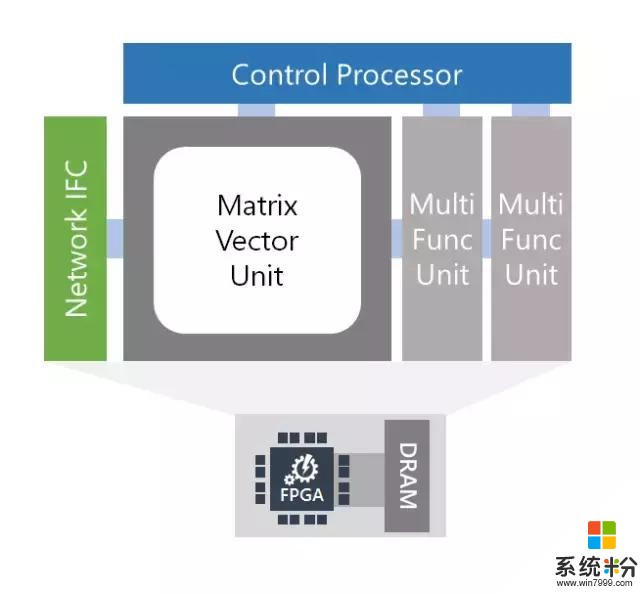
脑波软 DPU 架构
核心特征
单线程 C 编程模型(没有 RTL)
具有专门指令的 ISA:密集矩阵乘法、卷积、非线性激励值、向量操作、嵌入
独有的可参数化的窄精度格式,包含在 float16 接口中
可参数化的微架构,并且扩展到大型 FPGA(~1M ALMs)
硬件微服务完全整合(附设网络)
用于 CPU 主机和 FPGA 的 P2P 协议
易于扩展带有自定义运算符的 ISA
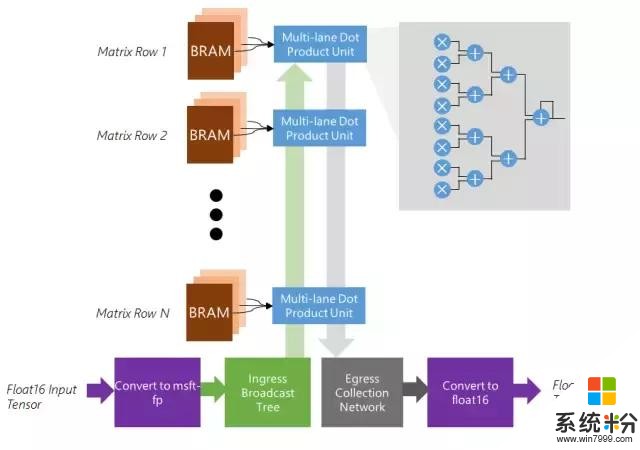
矩阵向量单元
特征
优化以适用于批量为 1 的矩阵向量乘法
矩阵逐行分布在 BRAM 的 1K-10K 个内存块上,最高 20 TB/s
可扩展以使用芯片上所有可用的 BRAM、DSP 和软逻辑(soft logic)
将 float 16 权重和激活值原位转换成内部格式
将密集的点积单元高效映射到软逻辑和 DSP
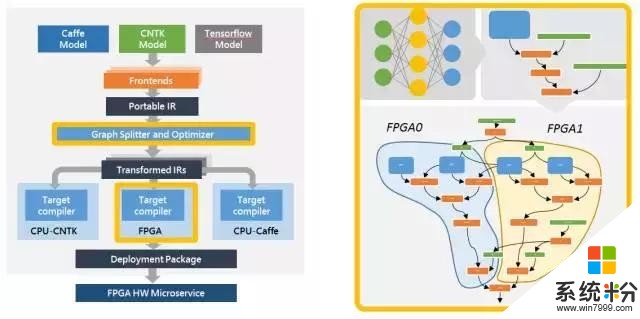
第三,脑波计划纳入了一款支持多个流行深度学习框架的软件栈(software stack)。我们已经支持微软 Cognitive Toolkit 和谷歌的 Tensorflow,并且计划支持其他框架。我们已经定义了一个基于图的中间表示(intermediate representation),我们将在流行框架中训练的模型转换成中间表示,然后再将其编译成我们的高性能基础架构。

编译器 & 运行时:框架中立的联合编译器和运行时,用于将预训练的 DNN 模型编译至软 DPU
架构:自适应 ISA,用于窄精度 DNN 接口;灵活、可扩展,可支持快速变化的人工智能算法
微架构:BrainWave Soft DPU 微架构;高度优化,适用于窄精度和小批量
扩展一致性:在 FPGA 芯片内存中一致的模型参数;可在多个 FPGA 中扩展以支持大模型
英特尔 FPGA 上的 HW 微服务:英特尔 FPGA 大规模部署,带有硬件微服务 [MICRO'16]
脑波编译器和运行时
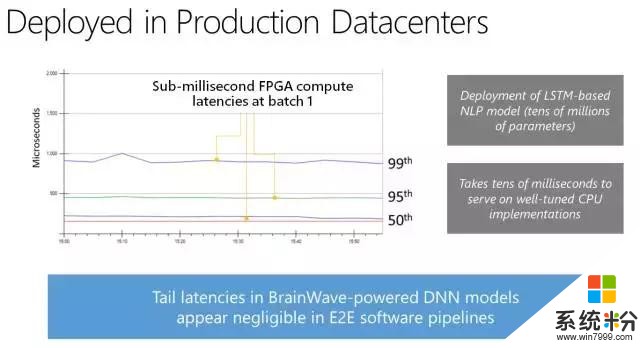
我们构建该系统,以展示其在多个复杂模型中的高性能,同时无须执行批处理(batch-free execution)。公司和研究人员构建 DNN 加速器通常使用卷积神经网络(CNN)展示性能 demo。CNN 是计算密集型,因此它取得高性能相对比较简单。那些结果通常无法代表其他域的更复杂模型上的性能,如自然语言处理中的 LSTM 或 GRU。DNN 加速器经常用来提升性能的另一项技术是用高度批处理运行深度神经网络。尽管该技术对基于吞吐量的架构和训练等离线场景有效,但它对实时人工智能的效果没有那么好。使用大批量,一个批次中的第一个查询必须等待该批次中的其他查询完成。我们的系统适用于实时人工智能,无须使用批处理来降低吞吐量,即可处理复杂、内存密集型的模型,如 LSTM。
即使在早期 Stratix 10 silicon 中,移植的 Brainwave 系统可运行大型 GRU 模型,它们可能比不使用批处理的 ResNet-50 还要大 5 倍,同时该系统也实现了创纪录的性能。该演示使用的是微软定制的 8 位浮点格式(「ms-fp8」),它在很多模型中都不会遭受到平均准确度损失。我们展示了 Stratix 10 在大型 GRU 模型中保持了 39.5 Teraflops,并且每一个请求的运行时间都在毫秒内。在性能方面,脑波架构每一个周期保持了超过 130000 个计算操作,并且由每 10 个周期发布的宏指令驱动。脑波在 Stratix 10 上运行,实现了实时 AI 的强大性能,特别是在非常具有挑战性的模型上。我们将在接下来的几个季度调整系统,希望它能够实现显著的性能提升。
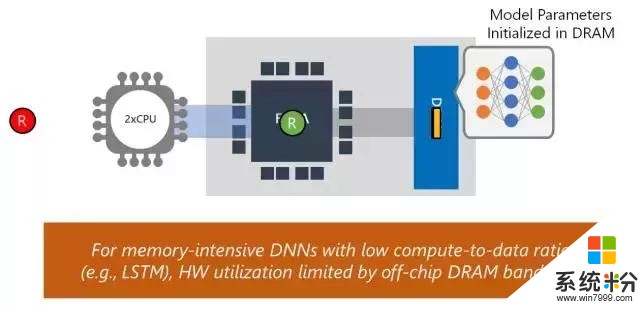
传统的加速方法:Local Offload and Streaming
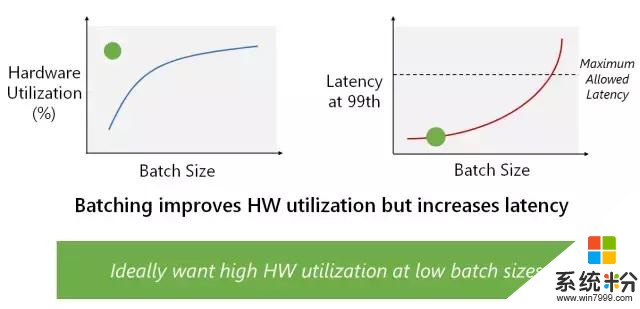
通过批处理提升硬件效用
FPGA 上的窄精度接口
结语
我们正将这种强大的实时 AI 系统介绍给大家,特别是 Azure 平台的用户。这样,我们的用户才能从脑波计划中直接获益,并间接补充了访问我们的服务的路径,如 Bing。在不久的未来,我们将具体说明 Azure 用户可以怎样使用该平台运行他们复杂的深度学习模型,并达到创纪录的性能。因为脑波计划系统是大规模集成系统并对我们用户是可用的,所以 Microsoft Azure 在实时人工智能上有行业领先的性能。









