IBM实现了创纪录的深度学习性能:完败Facebook微软
陈桦 编译整理
量子位 出品 | 公众号 QbitAI
昨晚,外媒都在用夸张的标题报道IBM的人工智能又立功了,例如说IBM的速度快得很“抓马”云云。到底怎么回事,量子位把IBM Research的博客全文搬运如下,大家感受一下IBM这次的捷报……

深度学习是一种被广泛使用的人工智能方法,帮助计算机按照人类的方式理解并提取图像和声音的含义。深度学习技术有望给各行各业带来突破,无论是消费类移动应用,还是医学影像诊断。然而,深度学习技术的准确性,以及大规模部署能力仍存在技术挑战,模型的训练时间往往需要几天甚至几周。
IBM研究院的团队专注于为大型模型和大规模数据集缩短训练时间。我们的目标是,将深度学习训练的等待时间从几天或几小时缩短至几分钟或几秒,同时优化这些人工智能模型的准确率。为了实现这一目标,我们正在将深度学习部署至大量服务器和英伟达GPU,解决“大挑战”规模的问题。
最热门的深度学习框架可以支持在单台服务器上的多个GPU,但无法支持多台服务器。我们的团队(包括Minsik Cho、Uli Finkler、David Kung和他们的合作者)编写了软件和算法,对这种规模庞大、非常复杂的并行计算任务进行优化,实现自动化。这种并行计算任务分布在数十台服务器的数百个GPU加速处理器上。

我们的软件可以完全同步地进行深度学习训练,且通信开销很低。因此,当我们将规模扩大至100s英伟达GPU集群时,对ImageNet-22k数据库中750万张图片的识别准确率达到创纪录的33.8%,高于此前的最高纪录,即来自微软的29.8%。
4%的准确率提升是巨大的飞跃,以往的优化通常只能带来不到1%的准确率提升。我们创新的分布式深度学习(DDL)方法不仅提高了准确率,还利用10s服务器的性能实现了在短短7小时时间里训练ResNet-101神经网络模型。这些服务器配备100s的英伟达GPU。
此前,微软花了10天时间去训练同样的模型。为了实现这一成绩,我们开发了DDL代码和算法,克服在扩展这些性能强大的深度学习框架时固有的问题。
这些结果采用的基准设计目标是为了测试深度学习算法和系统的极限,因此尽管33.8%的准确率听起来可能不算很高,但相比于以往已有大幅提升。给予任何随机图像,这个受过训练的人工智能模型可以在2.2万种选择中给出最高选择对象(Top-1精度),准确率为33.8%。
我们的技术将帮助其他人工智能模型针对特定任务进行训练,例如识别医学影像中的癌细胞,提高精确度,并使训练和再训练的时间大幅缩短。
Facebook人工智能研究部门于2017年6月在一篇论文中介绍了,他们如何使用更小的数据集(ImageNet-1k)和更小的神经网络(ResNet 50)来实现这一成果:“深度学习需要大型神经网络和大规模数据库才能快速发展。然而,更大的网络和数据库会造成更长的训练时间,不利于研究和开发进度。”
讽刺的是,随着GPU的速度越来越快,在多台服务器之间协调和优化深度学习问题变得越来越困难。这造成了深度学习的功能缺失,促使我们去开发新一类的DDL软件,基于大规模神经网络和大规模数据集运行热门的开源代码,例如Tensorflow、Caffe、Torch和Chainer,实现更高的性能和精确度。
在这里,我们可以用“盲人摸象”来形容我们试图解决的问题,以及所取得的初步成果的背景。根据维基百科上的解释:“每个盲人去摸大象身体的不同部位,但每个人只摸一部分,例如侧面或象牙。然后他们根据自己的部分经验来描述大象。对于大象是什么,他们的描述完全不同。”
尽管最初有分歧,但如果这些人有足够多的时间,那么就可以分享足够多的信息,拼凑出非常准确的大象图片。
类似地,如果你有大量GPU对某个深度学习训练问题并行处理几天或几周时间,那么可以很容易地同步这些学习结果。
随着GPU的速度越来越快,它们的学习速度也在变快。它们需要以传统软件无法实现的速度将学到的知识分享给其他GPU。这给系统网络带来了压力,并形成了棘手的技术问题。
基本而言,更智能、速度更快的学习者(GPU)需要更强大的通信方式,否则它们就无法同步,或是不得不花大量时间去等待彼此的结果。如果是这样,那么在使用更多、学习速度更快的GPU的情况下,你就无法加快系统速度,甚至有可能导致性能恶化。
我们利用DDL软件解决了这种功能缺失。当你关注扩展效率,或是在增加GPU以接近完美系统性能时,优势表现得最明显。我们在实验中试图了解,256个GPU如何“对话”,以及彼此学习了什么东西。
此前对256个GPU的最佳扩展来自Facebook人工智能研究部门(FAIR)。FAIR使用了较小的学习模型ResNet-50以及较小的数据库ImageNet-1k,后者包含约130万张图片。这样做减小了计算的复杂程度。基于8192的图片批量规模,256个英伟达GPU加速集群,以及Caffe2深度学习软件,FAIR实现了89%的扩展效率。
如果利用ResNet-50模型以及与Facebook同样的数据集,IBM研究院的DDL软件基于Caffe软件能实现95%的效率,如下图所示。这一结果利用了由64个Minsky Power S822LC系统组成的集群,每个系统中包含4个英伟达P100 GPU。
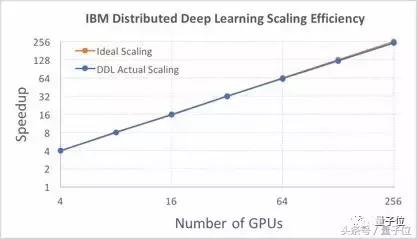
如果使用更大的ResNet-101模型,以及ImageNet-22k数据库中的750万张图片,图片批量规模选择5120,那么我们实现的扩展效率为88%。
此外,我们还实现了创纪录的最快绝对训练时间,即50分钟,而Facebook此前的纪录为1小时。我们用ImageNet-1k数据库训练ResNet-50模型,使用DDL将Torch扩展至256个GPU。Facebook使用Caffe2训练类似的模型。
对开发者和数据科学家来说,IBM研究院的DDL软件提供了一种API(应用程序接口),每个深度学习框架都可以挂接并扩展至多台服务器。技术预览版已通过PowerAI企业深度学习软件第4版发布,任何使用深度学习技术去训练人工智能模型的企业都可以使用这种集群扩展功能。
我们预计,通过将这种DDL功能提供给人工智能社区,随着其他人利用集群性能去进行人工智能模型训练,我们将看到准确性更高的模型运行。
—— 完 ——
活动报名
8月9日(周三)晚,量子位邀请三角兽首席科学家王宝勋,分享基于对抗学习的生成式对话模型,欢迎报名 ▼
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。量子位 QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态









