比CPU/GPU快30倍!Google TPU机器学习芯片揭秘
在谷歌发布TPU一年后,这款机器学习定制芯片的神秘面纱终于被揭开了。昨日,谷歌资深硬件工程师Norman Jouppi刊文表示,谷歌的专用机器学习芯片TPU处理速度要比GPU和CPU快15-30倍(和TPU对比的是英特尔Haswell CPU以及Nvidia Tesla K80 GPU),而在能效上,TPU更是提升了30到80倍。
从这次发布的测试结果来看,TPU似乎已经超出了业界的预期,但是藏在这一芯片背后的内部架构究竟有什么秘密呢,我们从Jouppi此前发布的论文当中,可以找到答案。

据雷锋网了解,早在四年前,谷歌内部就开始使用消耗大量计算资源的深度学习模型,这对CPU、GPU组合而言是一个巨大的挑战,谷歌深知如果基于现有硬件,他们将不得不将数据中心数量翻一番来支持这些复杂的计算任务。
所以谷歌开始研发一种新的架构,Jouppi称之为“下一个平台”。Jouppi曾是MIPS处理器的首席架构师之一,他开创了内存系统中的新技术。三年前他加入谷歌的时候,公司上下正在用CPU、GPU混合架构上来进行深度学习的训练。
Jouppi表示,谷歌的硬件工程团队在转向定制ASIC之前,早期还曾用FPGA来解决廉价、高效和高性能推理的问题。但他指出,FPGA的性能和每瓦性能相比ASIC都有很大的差距。他解释说,“TPU可以像CPU或GPU一样可编程,它可以在不同的网络(卷积神经网络,LSTM模型和大规模完全连接的模型)上执行CISC指令,而不是为某个专用的神经网络模型设计的。一言以蔽之,TPU兼具了CPU和ASIC的有点,它不仅是可编程的,而且比CPU、GPU和FPGA拥有更高的效率和更低的能耗。
TPU的内部架构
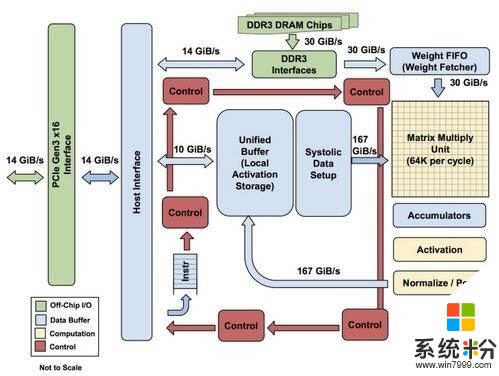
该图显示了TPU上的内部结构,除了外挂的DDR3内存,左侧是主机界面。指令从主机发送到队列中(没有循环)。这些激活控制逻辑可以根据指令多次运行相同的指令。
TPU并非一款复杂的硬件,它看起来像是雷达应用的信号处理引擎,而不是标准的X86衍生架构。Jouppi说,尽管它有众多的矩阵乘法单元,但是它GPU更精于浮点单元的协处理。另外,需要注意的是,TPU没有任何存储的程序,它可以直接从主机发送指令。
TPU上的DRAM作为一个单元并行运行,因为需要获取更多的权重以馈送到矩阵乘法单元(算下来,吞吐量达到了64,000)。Jouppi并没有提到是他们是如何缩放(systolic)数据流的,但他表示,使用主机软件加速器都将成为瓶颈。
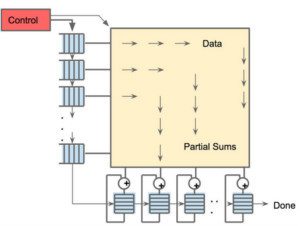
256×256阵列缩放数据流引擎,经过矩阵乘法积累后实现非线性输出
从第二张图片可以看出,TPU有两个内存单元,以及一个用于模型中参数的外部DDR3 DRAM。参数进来后,可从顶部加载到矩阵乘法单元中。同时,可以从左边加载激活(或从“神经元”输出)。那些以收缩的方式进入矩阵单元以产生矩阵乘法,它可以在每个周期中进行64,000次累加。
毋庸置疑,谷歌可能使用了一些新的技巧和技术来加快TPU的性能和效率。例如,使用高带宽内存或混合3D内存。然而,谷歌的问题在于保持分布式硬件的一致性。
TPU对比Haswell处理器
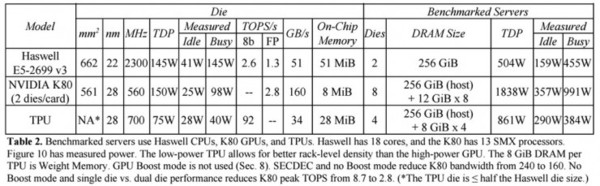
在和英特尔“Haswell”Xeon E5 v3处理器来的对比中,我们可以看到,TPU各方面的表现都要强于前者。
在Google的测试中,使用64位浮点数学运算器的18核心运行在2.3 GHz的Haswell Xeon E5-2699 v3处理器能够处理每秒1.3 TOPS的运算,并提供51GB/秒的内存带宽;Haswell芯片功耗为145瓦,其系统(拥有256 GB内存)满载时消耗455瓦特。
相比之下,TPU使用8位整数数学运算器,拥有256GB的主机内存以及32GB的内存,能够实现34GB/秒的内存带宽,处理速度高达92 TOPS ,这比Haswell提升了71倍,此外,TPU服务器的热功率只有384瓦。
除此之外,谷歌还测试了CPU、GPU和TPU处理不同批量大小的每秒推断的吞吐量。

如上图所示,在小批量任务中(16),Haswell CPU的响应时间接近7毫秒,其每秒提供5482次推断(IPS),其可以实现的最大批量任务(64)每秒则可以完成13194次推断,但其响应时间为21.3毫秒。相比之下,TPU可以做到批量大小为200,而响应时间低于7毫秒,并提供225000个IPS运行推理基准,是其峰值性能的80%,当批量大小为250,响应时间为10毫秒。
不过需要注意的是,谷歌所测试的Haswell Xeon处理器似乎也不能完全说明问题,英特尔Broadwell Xeon E5 v4处理器和最新的“Skylake”Xeon E5,每核心时钟(IPC)的指令比这款处理器提升了约5%。在Skylake是28核,而Haswell为18核,所以Xeon的总体吞吐量可能会上升80%。当然,这样的提升与TPU相比仍有差距。
最后雷锋网需要强调的是,TPU是一个推理芯片,它并非是要取代GPU,可以确定的是,TPU与CPU一起使用对训练分析更加有益。但对于CPU制造商而言,如何研发出像ASIC一样兼顾性能和能效的芯片是现在以及未来要做的。
Jouppi表示谷歌TPU已经开始出货,而英特尔这些芯片商也将面临更大的挑战。
文章来源:雷锋网









